






 本文详细介绍了云原生环境中Kubernetes的部署和优化实践,包括资源效率提升、环境一致性、故障检测与自我修复、弹性扩展、底层环境搭建、业务推广策略以及风险控制措施。还探讨了与传统KVM的对比和解决方案,强调了容器化技术在资源管理和性能优化中的优势。
本文详细介绍了云原生环境中Kubernetes的部署和优化实践,包括资源效率提升、环境一致性、故障检测与自我修复、弹性扩展、底层环境搭建、业务推广策略以及风险控制措施。还探讨了与传统KVM的对比和解决方案,强调了容器化技术在资源管理和性能优化中的优势。
公众号关注 「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !

云原生落地最佳实践
1. 上价值
从虚拟机到 Kubernetes 转变的收益
更高效的利用系统资源:虚拟化本身大概占用10%的宿主机资源消耗,在集群规模足够大的时候,这是一块非常大的资源浪费。
保证环境的一致性:环境不一致问题是容器镜像出现之前业界的通用问题,不利于业务的快速上线和稳定性。
加快资源交付和扩缩容:虚拟机创建流程冗长,各种初始化和配置资源准备耗时长且容易出错,而容器秒级启动,声明式的配置,降低出错概率,并内置智能负载均衡器。
强大的故障发现和自我修复能力:支持端口检查、url检查、脚本检查等多种健康检测方式,支持使用启动探针、就绪探针、存活探针,在应用出现问题时自动下线并重启。
支持弹性伸缩:可根据容器的内存、CPU使用率,调用QPS等,进行自动的扩缩容。
2. 搭建底层环境
从稳定性、高可用性、可观测性、高性能和可运维性角度出发搭建底层环境
说明:已 Centos 操作系统的物理机为例
安装前准备
常规操作:禁 swap、防火墙、SELINUX,更换 yum 源,安装依赖包,配置时间同步
性能优化:内核升级(建议把rpm放到公司内部私有仓库),调节 CPU 性能模式,内核参数优化,性能压测(后面文章会详解系统压测方法)
自动化 check:检查 hostname 是否符合 DNS 规范,检查 Service & Pod CIDR 是否与当前网段冲突,检查时间同步,检查外网连通性等
组件安装
Etcd :建议外置,单独安装,5节点集群;参数优化,开启自动压缩,调整 raft 消息最大字节数,调整 etcd 最大容量;性能压测(使用benchmark & FIO 压测,后续详解)
Master 三大件:Apiserver、Controller Manager、Scheduler 5节点,参数优化,调整 apiserver 的流控 qps;性能压测(使用 kubemark + Clusterloader2 压测,后续详解)
Node 节点:kubelet,kube-proxy,CRI,CNI,CSI
插件:kube-vip(保证 Apiserver的高可用性),nodelocaldns + coredns,Ingress (修改内核参数,提高并发能力)
可观测
指标类:kube-prometheus + 开发 exporter --> 汇聚到 VictoriaMetrics
日志类:ELK/Fluentd/Clickhouse
事件类:kube-eventer
链路类:OpenTelemetry
可观测性大盘:Grafana(图表绘制)
安装后可用性验证测试
集群状态检查、节点状态检查、部署 Pod 测试、服务访问测试、删除重启节点测试、拔测等
DevOps
运维平台支持:Deployment/Argo Rollout/Service/Ingress 对象的生命周期管理(申请、展示、扩缩容、销毁)
发布平台支持:CI 支持编译推送镜像,Java/Nodejs/Go/Python Yaml文件模版;CD 支持滚动发布,灰度发布,启动日志查看,回滚
堡垒机:支持容器登录,文件上传下载
3. 业务推广
策略:
a. 请喝奶茶
b. 先搞出个试点,最佳实践,然后 点--> 线 --> 面 推广
c. 上下齐力:从上到下,从下到上,一同发力
d. 风险控制:测试没问题,再上线,环境依次是,work --> test --> ut --> prod 灰度 --> prod 全量;做好回滚虚拟机的应急方案
e. 请喝奶茶
4. 风险控制和可靠性保障
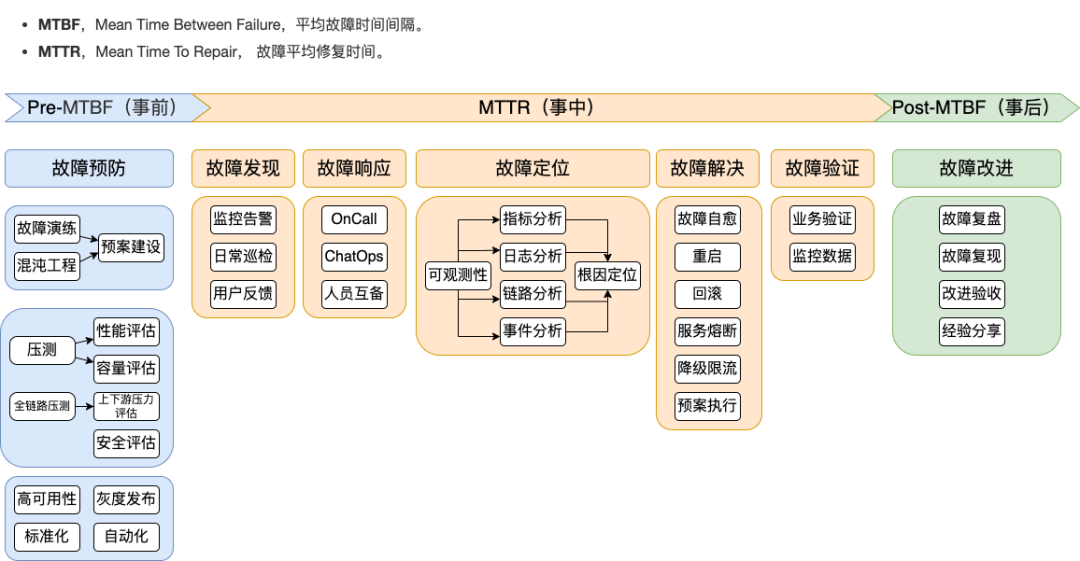
根据上图具体要做的事情分为以下几个方面(具体方案后续文章会详解)
故障演练
Apiserver 高可用故障演练
Etcd 高可用故障演练
混沌工程
Pod 级别故障注入
OS层:Cpu、Mem(内存)、File(文件)、Disk(磁盘)、Process(进程)、Network(网络)
JVM 虚拟机:CodeCacheFilling 字节码填充、delay 延时、throwDeclaredException、threadfull、OutOfMemoryError、full-gc
Node 级别故障注入
OS层:同上
预案建设:
Etcd 备份恢复
Velero 备份恢复
Master 节点紧急扩容
Etcd 节点紧急扩容
多集群故障迁移
性能评估
物理机性能压测
Master 组件性能压测
Etcd 性能压测
应用性能压测
容量评估
建立集群资源池、和资源预留,用于应急
Node 资源预留 防止雪崩
Pod Limit Request 限制,CPU/MEM/磁盘大小
Pod Qos、优先级 按服务等级划分
HPA
安全评估
开启 Apiserver 审计日志
使用 RBAC 最新权限原则授权
配置 PodDisruptionBudget (PDB)保护策略
API 通信使用强加密算法
污点、亲和性隔离
自动化巡检
核心指标主动巡检
监控告警
新增 Node Problem Detector(NPD) 监控
新增 tcp-exporter
补全、优化监控告警项
定义 Pod Tag中包涵 Appid 字段,使用 kube-state-metrics 将 Tag 暴露出去进行关联查询报警
CD
灰度发布
回滚
5.核心能力全景图
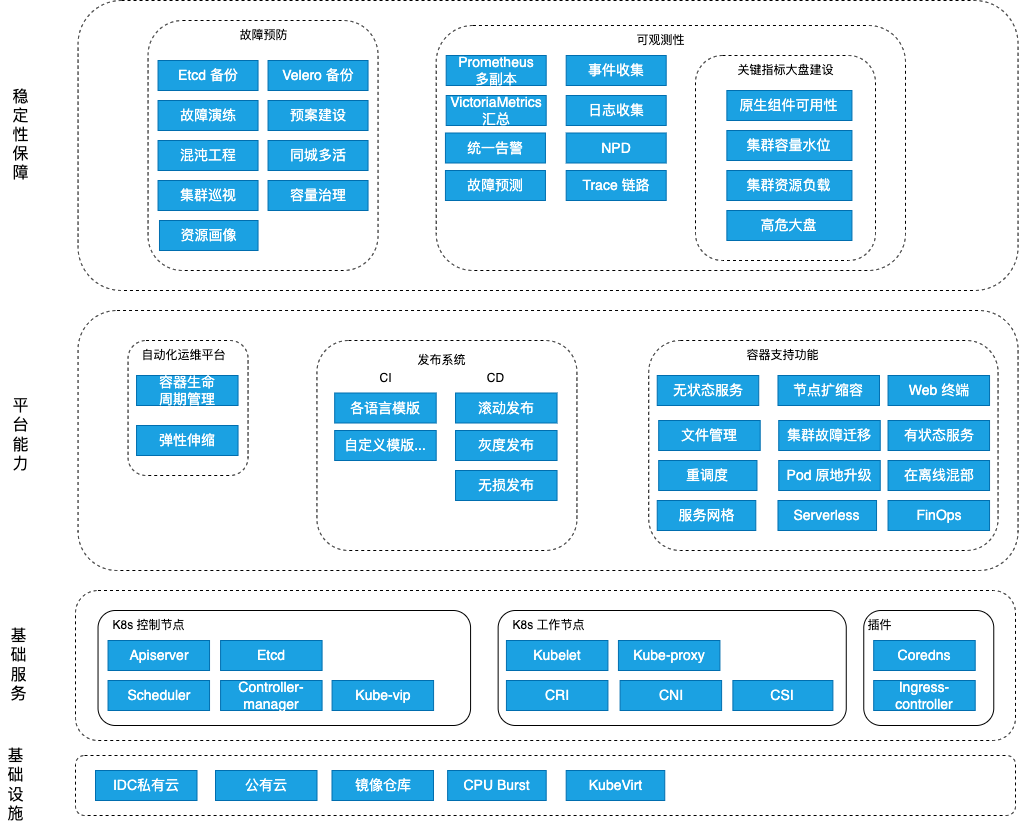
云原生是一个快速发展的领域,我们应该积极关注社区动态,进行版本迭代和新工具的引入,提高稳定性,效益最大化。
6. 对比 KVM 的 FAQ
1)应用从 KVM 迁移到 容器 后,资源利用率为何发生变化?
容器化后,CPU、MEM 使用率降低:容器是一种轻量级的资源隔离技术,与传统的虚拟机相比,容器使用更少的资源。每个容器共享宿主机的操作系统内核,而不像虚拟机那样需要独立的操作系统和内核。这减少了操作系统内核的开销,使得容器能够更高效地利用CPU和内存资源。虚拟机除了操作系统内核的开销外,还有各种 agent 的开销,zabbix-agent、filebeat-agent、hids-agent 等
可用内存减少(内存黑洞问题):虚拟机 和 容器的计算方式不同,虚拟机中可用内存取值为:free 中的 available 字段,数据来源于
/proc/meminfo,计算较为复杂,可简单理解为available = free_pages - total_reserved + pagecache + SReclaimable = free_pages - Σ(min((max(lowmem) + high_watermark), managed)) + (pagecache - min(pagecache / 2, wmark_low))+ (SReclaimable - min(SReclaimable/2, wmark_low))在容器中,没有类似虚拟机中
free命令中available字段的直接计算方式,容器的内存管理方式与虚拟机有所不同,容器通常直接共享宿主机的内存资源,并且容器内的内存使用情况是由容器运行时管理的,而不是像虚拟机那样拥有自己的操作系统和内核。容器的内存使用情况,可以参考内存使用率指标,数据来源于/sys/fs/cgroup/memory/kubepods/xxx/xxx,当使用率达到100%时,会发生OOM
2) 流量洪峰时,容器比虚拟RT长
RT 变长的原因是:容器发生 CPU 节流现象
什么是 CPU 节流?
CPU节流是一种资源调度的现象,当一个进程或任务需要的CPU资源超过了其分配的CPU配额时,操作系统或虚拟化管理程序会限制其对CPU的使用,从而导致其性能下降。这种限制是为了平衡系统中各个进程或任务之间的资源使用,防止某个进程过度使用CPU而影响其他进程的正常运行。
在Linux系统中,CPU节流通常是由CFS(Completely Fair Scheduler,完全公平调度器)实现的。CFS是Linux内核默认的调度器,用于公平地分配CPU时间片给各个运行中的进程和线程。当某个进程或任务的CPU使用超过了其分配的CPU配额时,CFS会根据其CPU Shares和CPU Quota等参数来限制其对CPU的使用,从而实现CPU节流。
容器和虚拟机在资源管理有一些区别
在 Kubernetes 中使用的是 cgroups 来管理资源分配与隔离,调度程序则选取了完全公平调度(CFS)中的强制上限(Ceiling Enforcement),CFS会根据每个容器的CPU配置(如CPU Shares、CPU Periods和CPU Quota)来进行CPU时间片的分配和调度。容器之间共享宿主机的CPU核心。
虚拟机是完全隔离的虚拟化技术,每个虚拟机运行在自己的虚拟操作系统中,有自己独立的CPU调度器和资源管理。虚拟机的CPU资源由Hypervisor管理,每个虚拟机获得分配的CPU核心,资源隔离较为明确,不容易相互影响。
什么情况下会发生 CPU 节流?
Pod 使用的 CPU 超过了 limit,会直接被限流。
容器内同时在 running 状态的进程/线程数太多,内核 CFS 调度周期内无法保证容器所在 cgroup 内所有进程都分到足够的时间片运行,部分进程会被限流。
内核态 CPU 占用过高也可能会影响到用户态任务执行,触发 cgroup 的 CPU throttle,有些内核态的任务是不可中断的,比如大量创建销毁进程,回收内存等任务,部分核陷入内核态过久,当切回用户态时发现该 CFS 调度周期时间所剩无几,部分进程也无法分到足够时间片从而被限流。
流量洪峰,属于 1 和 2 同时存在的情况
解决方案
业务侧改造:提前压测容器能承载的最大 QPS(RT较低的情况),根据 QPS 设置合理 HPA(自动弹性伸缩)规则,当容器平均 QPS,到达 阈值时,自动进行 扩容,使得容器 QPS 始终保持在阈值以下 提前压测容器能承载的最大 QPS(RT较低的情况),评估业务QPS可能达到的最大峰值,根据最大峰值计算确定容器的 Max数量,基于 HPA 定时任务规则,在业务活动时,自动提前扩容到Max 值
平台侧改造 几种的方案:
使用 cpusets 进行应用CPU绑核,缺点:资源利用率较低
根据历史节流数据,推测出合理的 CPU limit 值,让开发改为推荐配置
升级内核到 5.14 以上,支持CPU Burst技术(在传统的 CPU Bandwidth Controller quota 和 period 基础上引入 burst 的概念。当容器的 CPU 使用低于 quota 时,可用于突发的 burst 资源累积下来;当容器的 CPU 使用超过 quota,允许使用累积的 burst 资源。最终达到的效果是将容器更长时间的平均 CPU 消耗限制在 quota 范围内,允许短时间内的 CPU 使用超过其 quota。)
本文转载自:「SRE运维进阶之路」,原文:https://url.hi-linux.com/syXF0,版权归原作者所有。欢迎投稿,投稿邮箱: editor@hi-linux.com。

最近,我们建立了一个技术交流微信群。目前群里已加入了不少行业内的大神,有兴趣的同学可以加入和我们一起交流技术,在 「奇妙的 Linux 世界」 公众号直接回复 「加群」 邀请你入群。

你可能还喜欢
点击下方图片即可阅读
Wave Terminal: 又一款开源、跨平台的高颜值现代化终端
点击上方图片,『美团|饿了么』外卖红包天天免费领

更多有趣的互联网新鲜事,关注「奇妙的互联网」视频号全了解!

















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









