






公众号关注 「奇妙的 Linux 世界」
设为「星标」,每天带你玩转 Linux !
作为一名开发者,你是否经常遇到这样的困扰?AI 编程助手虽然强大,但仍然存在严重的代码幻觉,经常编造根本不存在的 API 接口。此外,目前主流的大语言模型(如 OpenAI,Claude,DeepSeek)的训练数据往往滞后于技术的更新,导致生成的代码常常基于已经废弃的旧版 API。结果就是,虽然 AI 可以快速生成代码,但调试和排错却耗费了大量时间,反而拖慢了开发进度。
Context7 的优点
Context7 的出现正是为了解决上面的痛点,Context7 充当了编程提示与实时软件文档之间的桥梁。每当被调用时,Context7 会从官方源头获取最新的、版本特定的文档和相关代码示例,提供给 AI 编程助手,将这些信息注入到 LLM 的上下文中,从而有效提高 LLM 生成代码的质量。Context7 的优点包括:
✅ 最新、最准确的代码:获取反映最新库版本和最佳实践的建议。
✅ 减少调试时间:减少因过时的 AI 知识导致的错误修复时间。
✅ 拒绝代码幻觉:依赖于已记录的、存在的函数。
✅ 精准版本:能根据你用的特定库版本给答案。
✅ 无缝的工作流程:直接集成到你现有的 AI 编程助手中(如 Cursor、带有 MCP 扩展的 VS Code 等),无需频繁切换到文档网站。
先试试直接让 AI 乱写代码
口说无凭,我们来实际对比下使用 Context7 前后的效果。首先,我们测试一下在没有 Context7 的情况下,AI 是否能够写出 Bug free 的代码。需求非常简单:使用 elasticsearch-rs 库,通过编写 Rust 代码与 Elasticsearch 进行交互,先创建一个索引,然后写入几条文档。
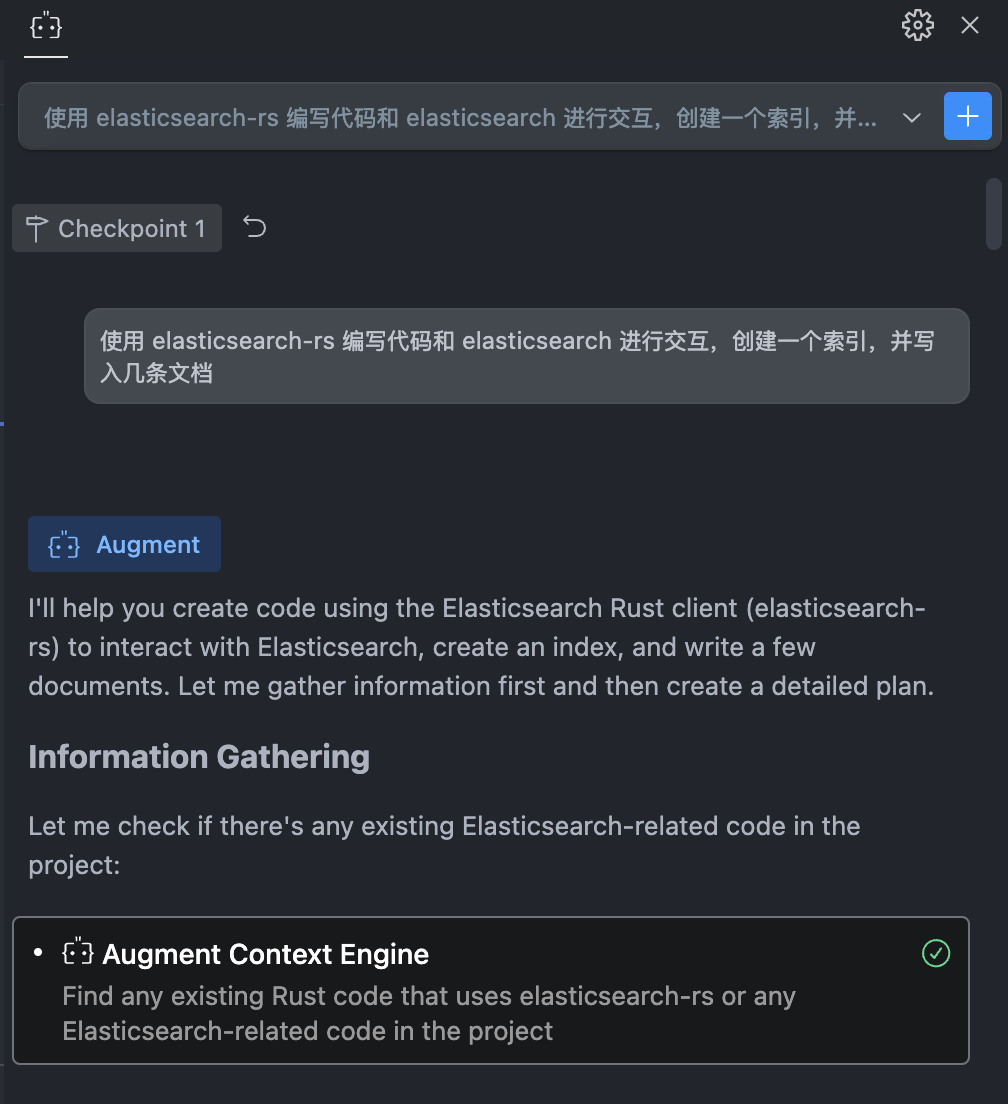
AI 接到指令以后,就开始洋洋洒洒地生成代码了,不到 1 分钟就已经写完了。
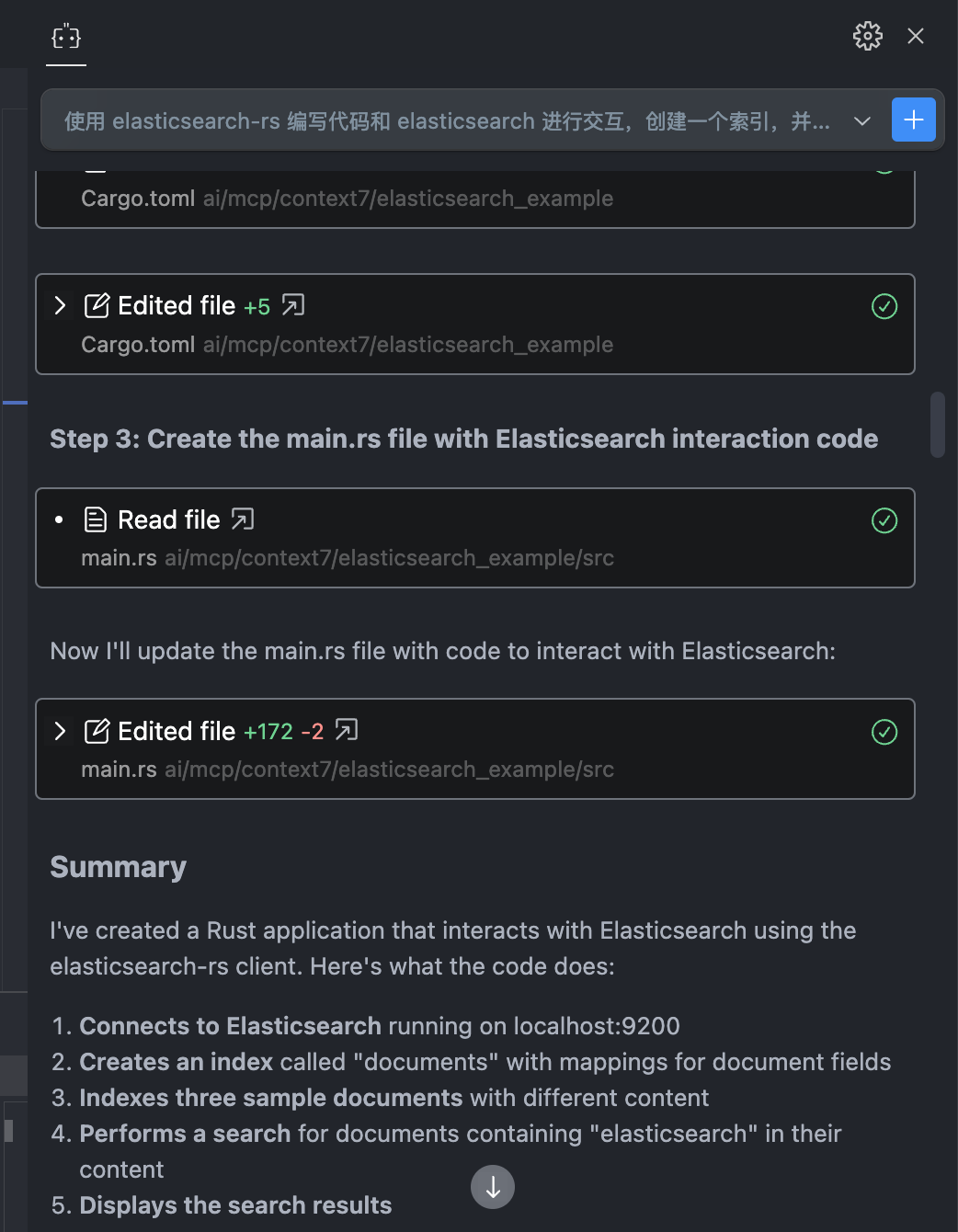
但是吧。。。 生成的代码显然无法正常运行,甚至连编译都通过不了,因为肉眼可见就已经能看到有 4 个报错的红线。。。
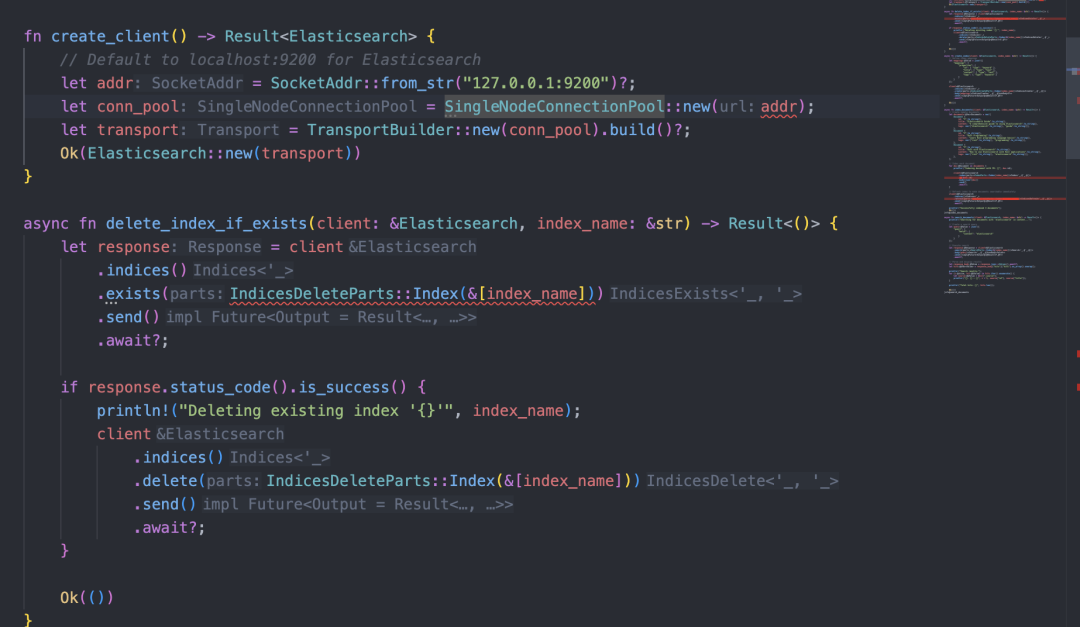
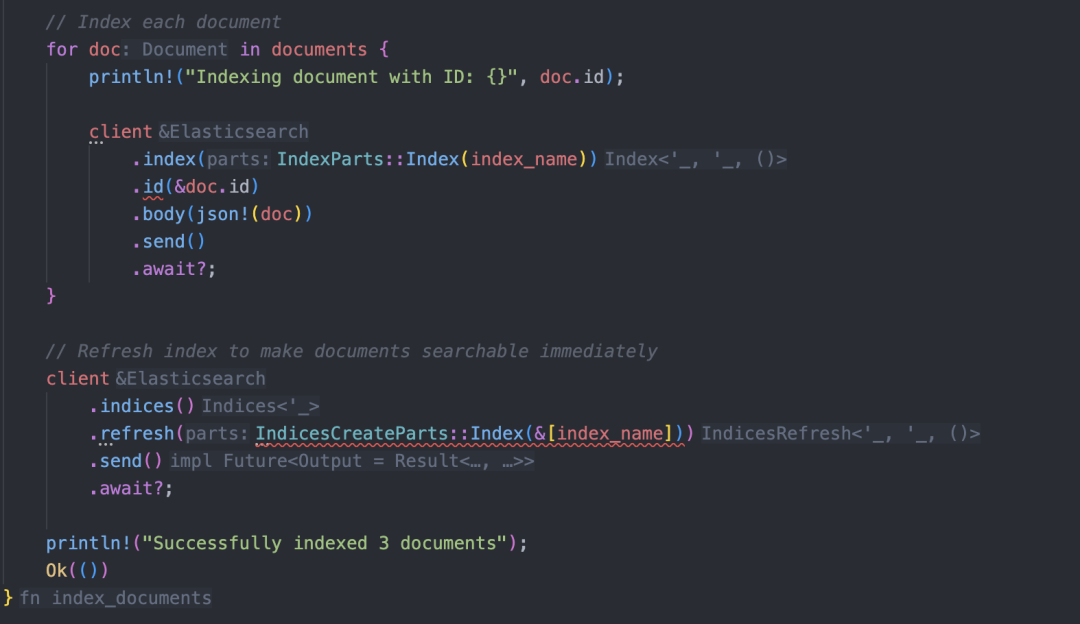
使用 cargo run 运行程序后,报错信息也清楚地显示出来,主要问题是调用函数时传入的参数类型不正确。
error[E0308]: mismatched types
--> src/main.rs:133:44
|
133 | .refresh(IndicesCreateParts::Index(&[index_name]))
| ------------------------- ^^^^^^^^^^^^^ expected `&str`, found `&[&str; 1]`
| |
| arguments to this enum variant are incorrect
|
= note: expected reference `&str`
found reference `&[&str; 1]`
note: tuple variant defined here
--> /Users/seven/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/elasticsearch-8.5.0-alpha.1/src/indices.rs:1022:5
|
1022 | Index(&'b str),
| ^^^^^
error[E0308]: mismatched types
--> src/main.rs:133:18
|
133 | .refresh(IndicesCreateParts::Index(&[index_name]))
| ------- ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected `IndicesRefreshParts<'_>`, found `IndicesCreateParts<'_>`
| |
| arguments to this method are incorrect
|
note: method defined here
--> /Users/seven/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/elasticsearch-8.5.0-alpha.1/src/indices.rs:9654:12
|
9654 | pub fn refresh<'b>(&'a self, parts: IndicesRefreshParts<'b>) -> IndicesRefresh<'a, 'b, ()> {
| ^^^^^^^
error[E0308]: mismatched types
--> src/main.rs:48:51
|
48 | let conn_pool = SingleNodeConnectionPool::new(addr);
| ----------------------------- ^^^^ expected `Url`, found `SocketAddr`
| |
| arguments to this function are incorrect
|安装 Context7 MCP Server
接下来,让我们试试使用 Context7,看看它是否能提升 LLM 生成的代码质量。关于 Context7 MCP Server 的安装方式,可以参考:https://github.com/upstash/context7
目前,常见的 AI 编程助手(如 Cursor、Windsurf、Augment Code 等)都支持配置 MCP Server。以我使用的 Augment Code 为例,只需要添加 Context7 MCP Server 的安装命令即可。
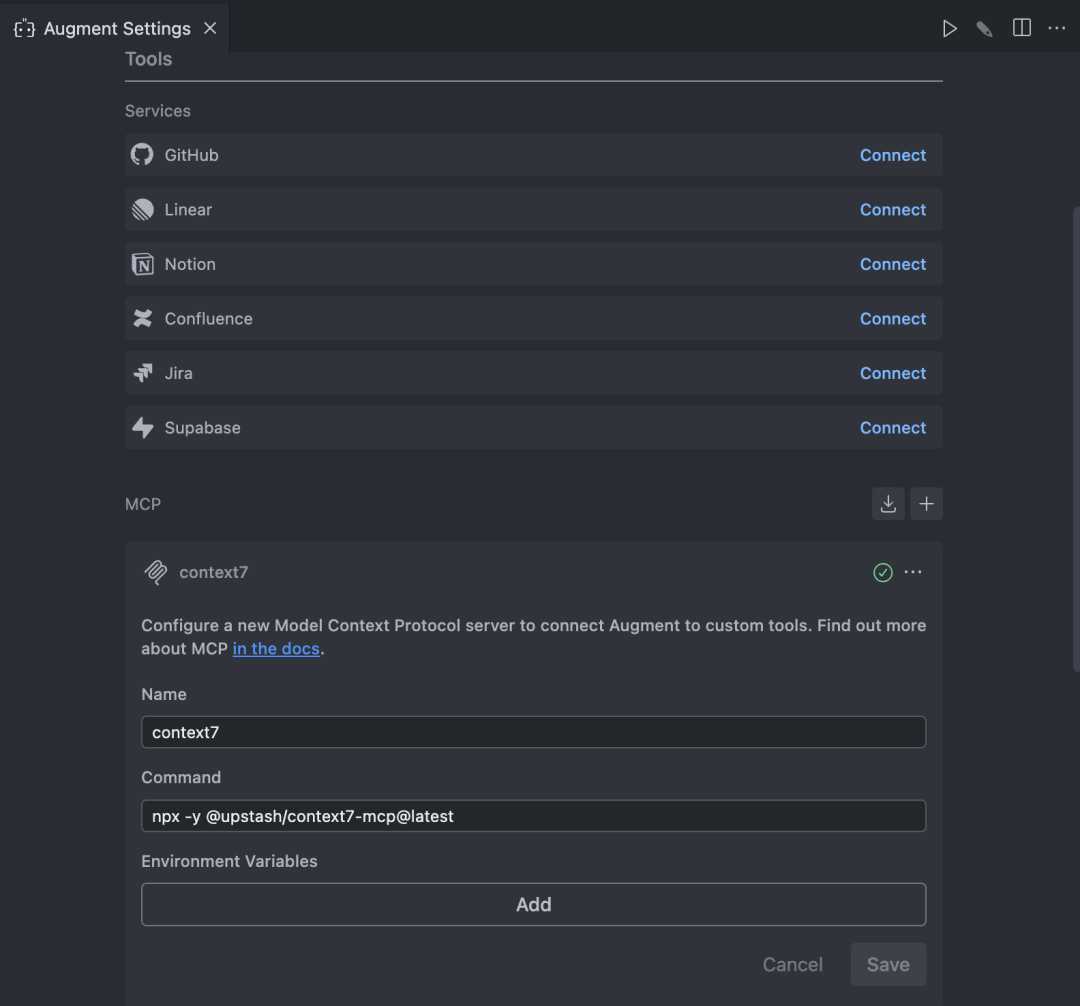
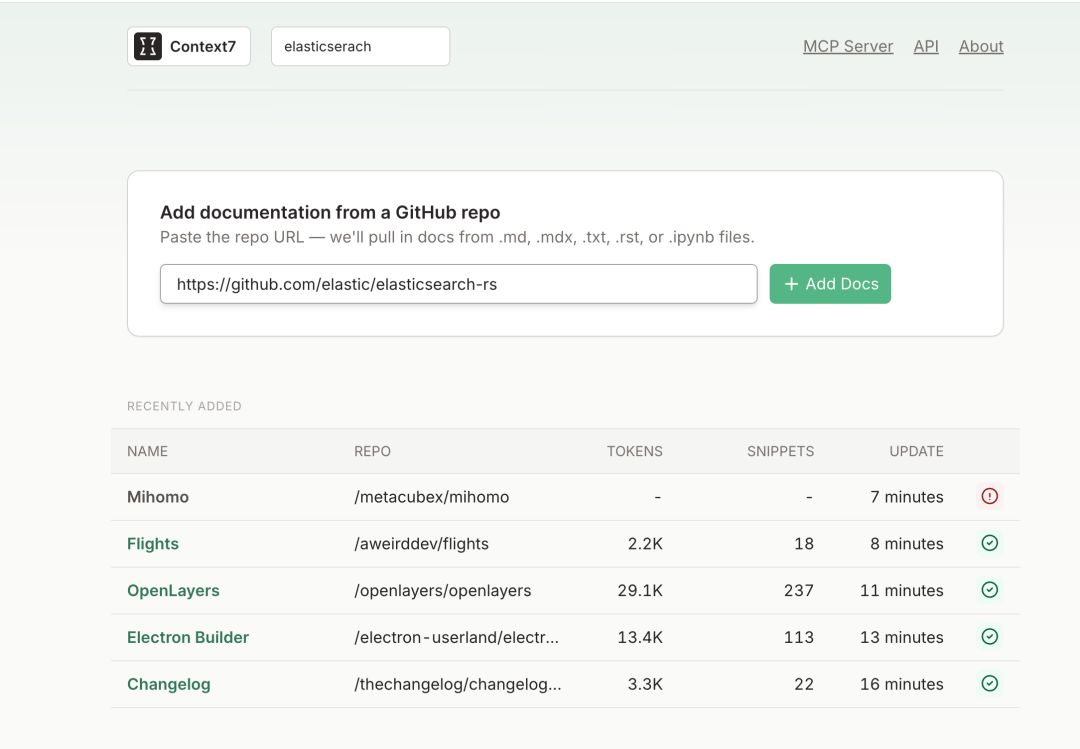
如果你想使用的库在 Context7 网站中还没有被索引,你可以手动添加。在本文中,我手动添加了 elasticsearch-rs 库。以后如果需要使用该库,就无需再手动添加了。
使用 Context7 提升 AI 代码质量
安装完成后,我们让 AI 编程助手重新尝试完成相同的任务,只不过这次我们让 AI 编程助手在开始之前先使用 Context7 查阅代码文档。提示词如下:
先使用 context7 mcp server 查询 elasticsearch-rs 的代码文档,
然后使用 elasticsearch-rs 编写代码和 Elasticsearch 进行交互,
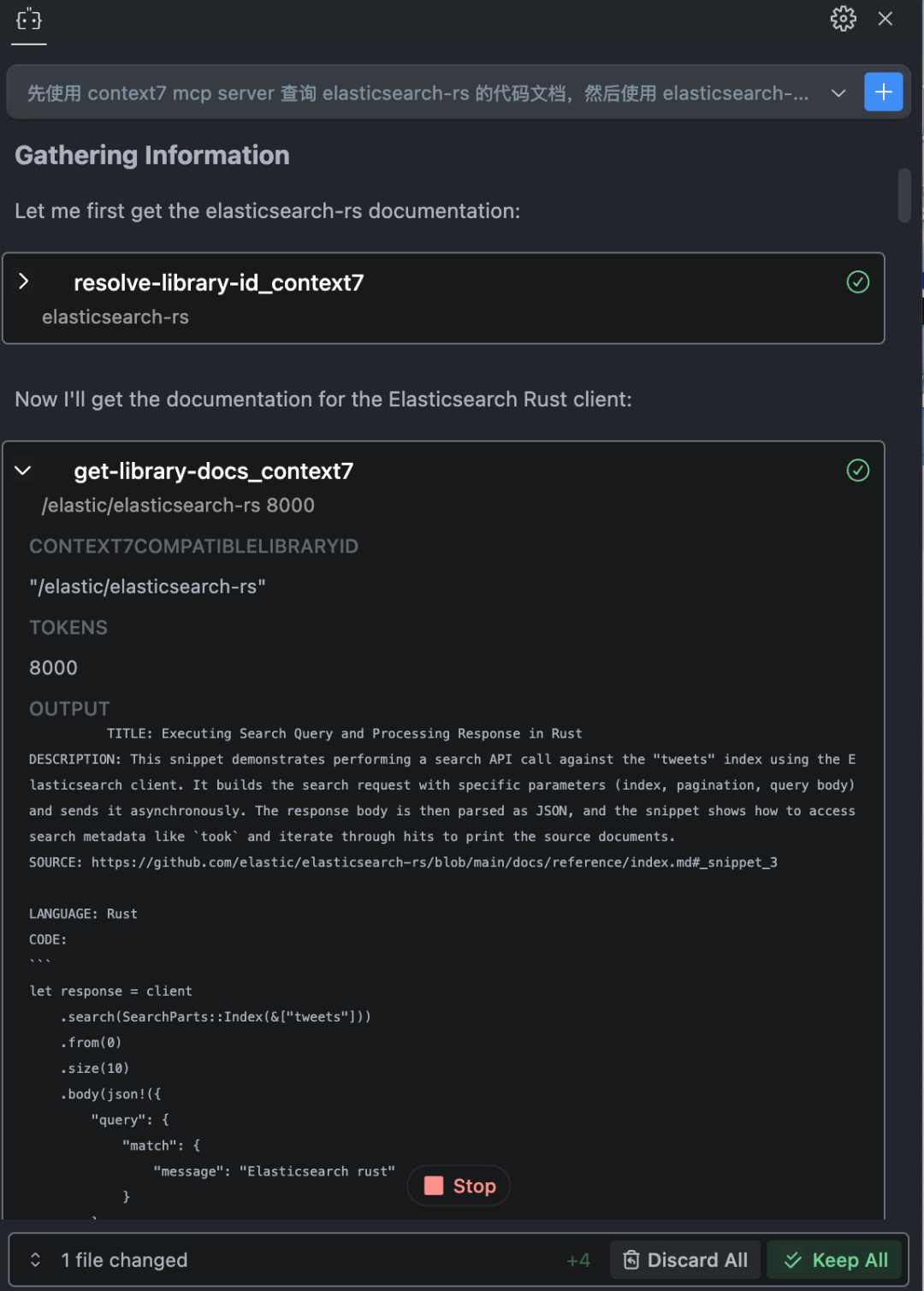
首先创建一个索引,然后写入几条文档,再查询这几条文档从下图可以看到,Augment Code 首先调用了 Context7 MCP Server,获取了基于 elasticsearch-rs 库整理的提示词,然后根据最新的代码进行编程。
生成的代码如下所示:
use elasticsearch::{
Elasticsearch,
indices::IndicesCreateParts,
SearchParts,
IndexParts,
http::transport::Transport,
};
use serde::{Deserialize, Serialize};
use serde_json::{json, Value};
#[derive(Debug, Serialize, Deserialize)]
struct Document {
id: u32,
title: String,
content: String,
}
#[tokio::main]
asyncfn main() -> Result<(), Box<dyn std::error::Error>> {
println!("Connecting to Elasticsearch...");
println!("Note: This example requires Elasticsearch to be running on http://localhost:9200");
println!("If Elasticsearch is not running, you will see connection errors.");
// Create a client connected to localhost using HTTP
let transport = Transport::single_node("http://localhost:9200")?;
let client = Elasticsearch::new(transport);
// Index name
let index_name = "test_index";
// Create an index with mapping
println!("Creating index '{}'...", index_name);
let _response = client
.indices()
.create(IndicesCreateParts::Index(index_name))
.body(json!({
"mappings": {
"properties": {
"id": { "type": "integer" },
"title": { "type": "text" },
"content": { "type": "text" }
}
}
}))
.send()
.await?;
println!("Index creation successful!");
// Create some documents
let documents = vec![
Document {
id: 1,
title: "First document".to_string(),
content: "This is the content of the first document".to_string(),
},
Document {
id: 2,
title: "Second document".to_string(),
content: "This is the content of the second document".to_string(),
},
Document {
id: 3,
title: "Third document".to_string(),
content: "This is the content of the third document".to_string(),
},
];
// Index the documents
println!("Indexing documents...");
for doc in &documents {
// Create document ID
let doc_id = doc.id.to_string();
// Index with document ID in the URL path
let _response = client
.index(IndexParts::IndexId(index_name, &doc_id))
.body(doc)
.send()
.await?;
println!("Document indexed with ID: {}", doc.id);
}
// Refresh the index to make the documents searchable immediately
client
.indices()
.refresh(elasticsearch::indices::IndicesRefreshParts::Index(&[index_name]))
.send()
.await?;
// Search for documents
println!("Searching for documents...");
let search_response = client
.search(SearchParts::Index(&[index_name]))
.body(json!({
"query": {
"match_all": {}
}
}))
.send()
.await?;
// Process the search response
let search_body = search_response.json::<Value>().await?;
let hits = search_body["hits"]["hits"].as_array().unwrap();
println!("Found {} documents:", hits.len());
for hit in hits {
println!("ID: {}, Source: {}",
hit["_id"].as_str().unwrap(),
hit["_source"]
);
}
// Search for specific content
println!("\nSearching for documents with 'first' in content...");
let search_response = client
.search(SearchParts::Index(&[index_name]))
.body(json!({
"query": {
"match": {
"content": "first"
}
}
}))
.send()
.await?;
// Process the search response
let search_body = search_response.json::<Value>().await?;
let hits = search_body["hits"]["hits"].as_array().unwrap();
println!("Found {} documents with 'first' in content:", hits.len());
for hit in hits {
println!("ID: {}, Source: {}",
hit["_id"].as_str().unwrap(),
hit["_source"]
);
}
println!("Done!");
Ok(())
}让我们尝试运行代码,可以到成功创建了索引,并写入了文档。借助 Context7,AI 编程助手一次就完成了 Bug free 的代码。
cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 3.70s
Running `target/debug/elasticsearch-example`
Connecting to Elasticsearch...
Note: This example requires Elasticsearch to be running on http://localhost:9200
If Elasticsearch is not running, you will see connection errors.
Creating index 'test_index'...
Index creation successful!
Indexing documents...
Document indexed with ID: 1
Document indexed with ID: 2
Document indexed with ID: 3
Searching for documents...
Found 3 documents:
ID: 1, Source: {"content":"This is the content of the first document","id":1,"title":"First document"}
ID: 2, Source: {"content":"This is the content of the second document","id":2,"title":"Second document"}
ID: 3, Source: {"content":"This is the content of the third document","id":3,"title":"Third document"}
Searching for documents with 'first'in content...
Found 1 documents with 'first'in content:
ID: 1, Source: {"content":"This is the content of the first document","id":1,"title":"First document"}
Done!总结
本文通过实际案例演示了如何利用 Context7 MCP Server 解决 AI 编程助手中的代码幻觉问题和使用过时 API 的问题。借助 Context7 获取最新、最准确的代码建议,显著提升了 AI 生成的代码质量,从而有效提高了开发效率。
参考资料
Context7: https://context7.com/
upstash/context7: https://github.com/upstash/context7
How to Install Context7 MCP Server: https://huggingface.co/blog/lynn-mikami/context7-mcp-server
Get Accurate, Up-to-Date Code with the Context7 MCP Server: Your Setup and Usage Guide: https://sebastian-petrus.medium.com/context7-mcp-server-8609aa20add9
备注
本文的相关代码可以在 Github 上找到:https://github.com/cr7258/hands-on-lab/tree/main/ai/mcp/context7/elasticsearch
你可以使用 docker-compose up -d 命令来启动一个单节点的 Elasticsearch 集群。通过 http://localhost:9200 进行访问,没有设置用户名和密码。

最近,我们建立了一个技术交流微信群。目前群里已加入了不少行业内的大神,有兴趣的同学可以加入和我们一起交流技术,在 「奇妙的 Linux 世界」 公众号直接回复 「加群」 邀请你入群。

你可能还喜欢
点击下方图片即可阅读

点击上方图片,『美团|饿了么』外卖红包天天免费领

更多有趣的互联网新鲜事,关注「奇妙的互联网」视频号全了解!

















 124
124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









