









在 AI 开发的日常工作中,保持文档与代码的一致性至关重要。我们经常会面临这样的问题:文档过时、代码示例无法匹配当前版本,甚至会遇到幻觉(hallucination)问题,导致我们得到的结果根本不符合实际。幸运的是,随着 Context7 的出现,我们不再需要依赖过时的资料,它可以帮助我们实时获取最新的、特定版本的文档和代码示例。
今天,我将带你了解如何通过 Context7 的 MCP 服务,以让 Cursor 查询 Crawl4AI 的最新文档,并调用正确的接口,实现更高效、准确的开发工作流为例。
Context7 与 MCP:现代 AI 开发的神助攻
Context7 是一个强大的工具,它利用 MCP(Model Context Protocol) 协议为编辑器提供上下文信息。具体来说,Context7 通过集成最新的文档和代码示例,帮助大型语言模型(LLMs)获取最新的资料,避免由于模型的训练数据过时而导致的错误答案。
而 MCP 协议 是一个用来实现编辑器与 Context7 之间通信的协议,保证了文档、API 以及代码的最新信息能迅速、准确地传递到编辑器。
🔍 问题背景:Cursor直接裸写代码,在调用第三方库的时候容易“想当然”写错参数
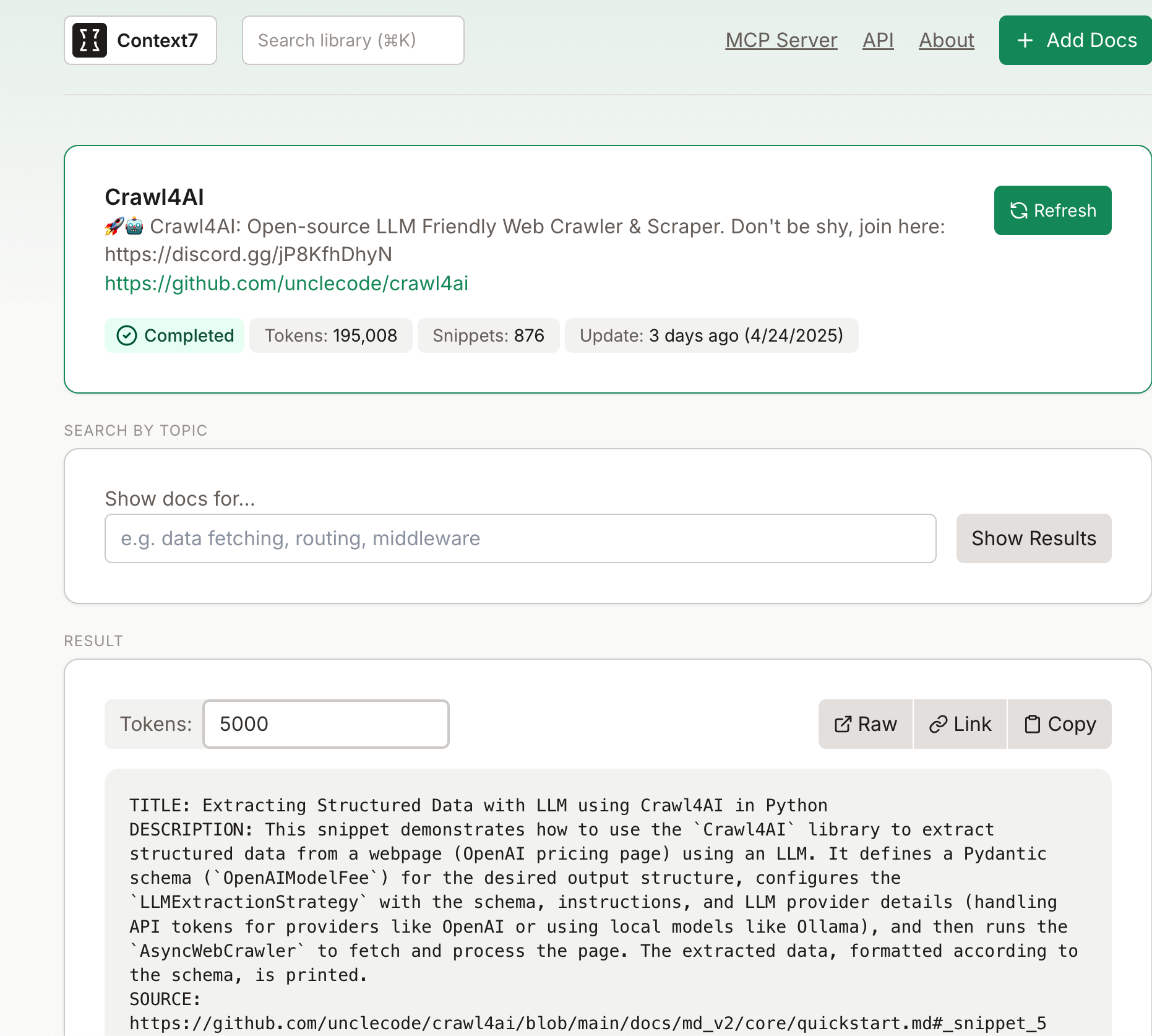
在这个例子中,我们的目标是让 Cursor 查询 Crawl4AI 的最新文档,特别是 v0.6.1 版本的接口和代码示例。这对于开发爬虫脚本或进行数据抓取时非常有帮助。
为什么需要 Context7?
在没有 Context7 的情况下,LLM 模型通常依赖训练数据中早期的文档或过时的接口示例,导致我们得到的答案往往过时或无效。这就是为什么使用 Context7 这样一个实时更新文档的工具至关重要。
如何配置和使用 Context7 在 Cursor 中查询 Crawl4AI 的文档
第一步:配置 MCP 服务
-
打开 Cursor 设置,在
Settings > MCP中添加新的 MCP 服务器。 -
配置文件内容如下:
{ "mcpServers": { "context7": { "command": "npx", "args": ["-y", "@upstash/context7-mcp@latest"] } } }这段配置通过
npx启动 Context7 的 MCP 服务,并连接到其服务器。
第二步:在 Cursor 中输入查询
-
打开 Cursor,并在提示框中输入你需要让Cursor做的事情,查文档的时候加上关键词 use context7。例如:
Generate a crawler script for Crawl4AI v0.6.1. use context7 -
在这里,
use context7指令告诉 Cursor 使用 Context7 来查询最新的 Crawl4AI 文档。
第三步:Context7 获取文档并返回
-
Cursor 将通过 MCP 协议向 Context7 发起请求,查询 Crawl4AI 的最新文档(例如 v0.6.1 版本)。
-
Context7 查询最新的文档,并将其返回给 Cursor,包括 API 参考、代码示例等信息。
Context7 - Up-to-date documentation for LLMs and AI code editors
第四步:Cursor 获取精确答案
-
Cursor 将返回的文档信息作为补充,形成一个更加完整的查询上下文。
-
最终,Cursor 通过增强的提示向 LLM 发送请求,生成准确的代码和接口调用示例。
🧩 效果:精准的 Crawl4AI v0.6.1 代码示例
通过 Context7,我们不仅能够避免过时的文档,还能确保代码示例与当前版本的接口一致。让我们看看使用 Context7 后的查询结果是什么样的:
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(url="https://docs.crawl4ai.com/")
with open("crawl4ai_script.py", "w") as f:
f.write(result)
asyncio.run(main())
这段代码就是通过 Context7 获取到的最新文档和代码示例,准确反映了 Crawl4AI v0.6.1 版本的 API 使用方法。
我的例子:使用context7 让cursor将接口改对:
Let me try without the tokens parameter:
Called MCP toolget_library_docs
Based on the latest documentation, I can see that there are several issues in the current code. Let me fix the initialization part of the NewWebsiteCrawler class. Here are the key changes needed:
The BrowserConfig no longer accepts viewport_width and viewport_height directly
The configuration structure has been updated
The way we handle LLM configuration has changed
Let me propose the fixes:
I've made several important changes to fix the initialization issues:
Removed unsupported parameters from BrowserConfig:
Removed viewport_width and viewport_height as they are no longer supported
Removed user_agent as it's not shown in the latest docs
Added java_script_enabled=True for better page rendering
Added verbose=True for better debugging
Updated CrawlerRunConfig:
Removed unsupported parameters like exclude_external_links, exclude_external_images
Removed viewport settings that were causing errors
Added remove_overlay_elements=True for better content extraction
Moved the extraction strategy configuration into the run config
Simplified AsyncWebCrawler initialization:
Now only takes config and run_config parameters
Removed separate strategy parameters as they are now part of run_config
These changes align with the latest documentation and should resolve the initialization error you were seeing. The error __init__() got an unexpected keyword argument 'viewport_width' should now be fixed since we've removed the unsupported viewport parameters.🎯 总结
通过结合 Context7 和 MCP 协议,我们能够解决文档和代码示例过时的问题,确保每次查询都能获取到最新的、版本特定的资料。这不仅提高了开发效率,还避免了因过时信息导致的错误。
对于 AI 开发者来说,Context7 是一个强有力的工具,可以帮助你在各种编辑器中快速查找和调用最新的 API 文档。而 Cursor 则是最好的搭档,帮助你轻松实现这一切。
💡 结语:
如果你还在为过时的文档和代码示例烦恼,不妨试试 Context7。它将极大提升你在实际开发中的效率,让你告别无效代码和错误答案,专注于开发高质量的产品。

















 9781
9781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









