







 本文提供了Hadoop作业性能调优的7个建议,包括压缩输出文件、应对数据倾斜、增加内存、避开资源竞争等,旨在提高作业效率和减少资源消耗。通过调整相关参数,如使用Lzo压缩、合并小文件、优化内存分配等,可以有效解决性能问题。
本文提供了Hadoop作业性能调优的7个建议,包括压缩输出文件、应对数据倾斜、增加内存、避开资源竞争等,旨在提高作业效率和减少资源消耗。通过调整相关参数,如使用Lzo压缩、合并小文件、优化内存分配等,可以有效解决性能问题。
作者:Shu, Alison
Hadoop作业性能调优的两种场景:
一、用户观察到作业性能差,主动寻求帮助。
(一)eBayEagle作业性能分析器
1. Hadoop作业性能异常指标
2. Hadoop作业性能调优7个建议
(二)其它参数调优方法
二、Hadoop集群报告异常,发现个别作业导致集群事故。
一、用户观察到作业性能差,主动寻求帮助。
(一)eBay Eagle作业性能分析器
对一般作业性能调优,eBay Eagle[i]的作业性能分析器已经能满足用户大部分需求。eBayEagle作业性能分析包含两个部分,第一部分是根据定量指标,捕捉性能异常的作业。在本文中,我们不考虑Hadoop集群或者节点故障造成作业性能的普遍下降,因此我们认为这些性能指标异常只与Hadoop作业有关,可以通过性能调优来改善。第二部分是调优建议。根据Hadoop作业性能异常指标判断作业是否需要调优,再综合采用第二部分的建议。第二部分也可以作为Hadoop作业开发的指引,并在后期性能测试中检查。
1. Hadoop作业性能异常指标
参阅《Hadoop作业性能指标及参数调优实例(一)Hadoop作业性能异常指标》
2. Hadoop作业性能调优的7个建议
§ 压缩输出文件
压缩可以节省磁盘和网络的IO,提高作业性能。Gzip/Snappy/Lzo/Bzip2都是常用的压缩格式,根据需要选用。
四种常用压缩格式的特征[ii]:
| 压缩格式 | split | native | 压缩率 | 速度 | Hadoop自带 | linux命令 | 换成压缩格式后,原来的应用程序是否要修改 |
| Gzip | 否 | 是 | 很高 | 比较快 | 是 | 有 | 和文本处理一样,不需要修改 |
| Lzo | 是 | 是 | 比较高 | 很快 | 否 | 有 | 需要建索引,还需要指定输入格式 |
| Snappy | 否 | 是 | 比较高 | 很快 | 否 | 没有 | 和文本处理一样,不需要修改 |
| Bzip2 | 是 | 否 | 最高 | 慢 | 是 | 有 | 和文本处理一样,不需要修改 |
参数调优(用lzo压缩):
mapreduce.output.fileoutputformat.compress=true
mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.LzoCodec
mapreduce.map.output.compress=true
mapreduce.map.output.compress.codec=com.hadoop.compression.lzo.LzoCodec
§ 应对数据倾斜
如果一些Reduce比其它Reduce明显耗时更多,我们认为发生数据倾斜,整个作业会因为数据倾斜而耗时更多。
eBay Eagle对数据倾斜的定义:
(WorstReduceTime - avgReduceTime > 30 minutes)and (WorstReduceInputRecords / avgReduceInputRecords > 5)
有很多解决方案,例如写MapReduce作业时,合并中间数据,避免大量小文件。在工作中,我们碰到数据倾斜的咨询集中在Hive查询,参数调优如下:
-合并小文件((文件再小,Block再大,每个小文件都会占用一个Block)
hive.merge.mapfiles=true
hive.merge.size.per.task=256000000
-利用Map端聚合,达到Reduce负载均衡
hive.groupby.skewindata=true
hive.optimize.skewjoin=true
hive.map.aggr=true
hive.groupby.mapaggr.checkinterval = 100000
§ 增加内存,减少GC时间
当Map或Reduce内存不够时,需要更多的GC时间,从而影响作业性能。
eBay Eagle对GC时间过长的定义:
GC_TIME_MILLIS / CPU_MILLISECONDS > 0.1
作业参数调优,提高Heap size:
mapreduce.map.java.opts=-Xmx4g
mapreduce.reduce.java.opts=-Xmx4g
在提高Heap Size参数时,注意Heap Size不得超过物理内存。
mapreduce.map.memory.mb > mapreduce.map.java.opts
mapreduce.reduce.memory.mb >mapreduce.reduce.java.opts
§ 避开资源竞争
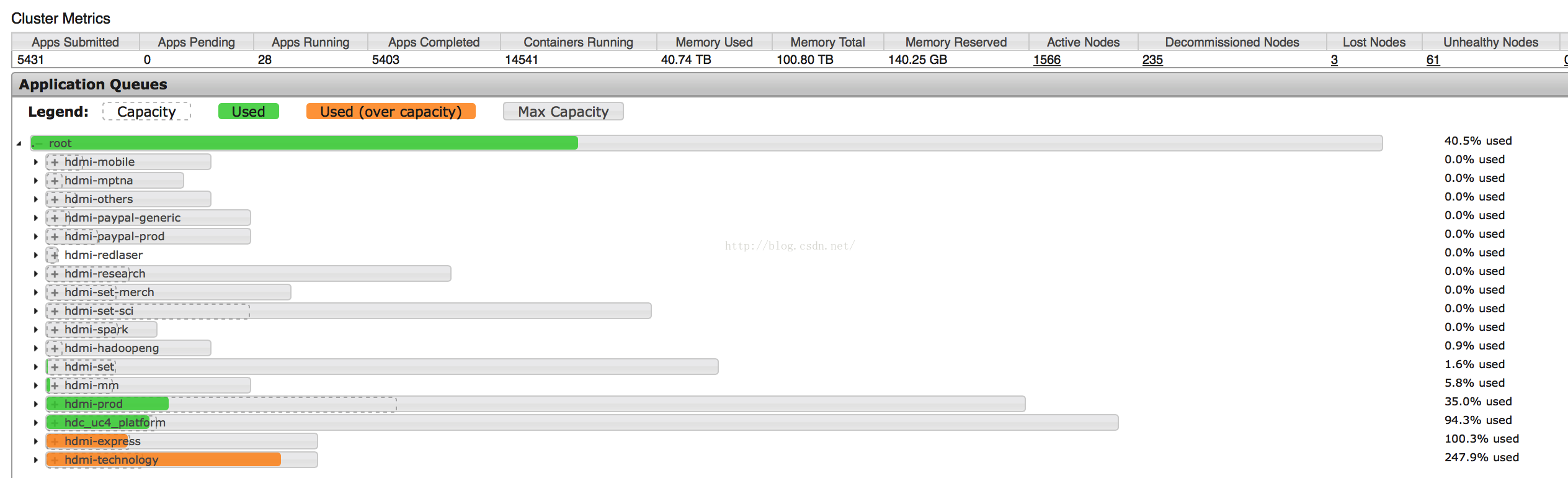
系统资源紧张会造成Map或Reduce进展缓慢。用户可以从Scheduler中观察不同queue的资源使用情况,避开繁忙的窗口。如果作业有多个queue可以选择,选择资源空闲的queue。
设置queue:
mapreduce.queue.jobname=<queue_name>
示例:通过ResourceMananger web URL 观察系统资源使用情况
§ 增加内存,减少磁盘溢出
设置以下作业参数减少磁盘溢出:(适当大于默认值)
mapreduce.map.sort.spill.percent=1
mapreduce.task.io.sort.mb=1024
mapreduce.map.java.opts=-Xmx4096M
§ 保留系统默认的最小分片大小
有些人会设置split.minsize作业参数以控制Map数量,但这种做法会削弱数据本地性,降低作业性能,建议保留系统默认设置。在默认配置下,split大小和block大小是相同的,防止一个split如果对应的多个block而且这些block大多不在本地。
保留作业参数默认值:
mapreduce.input.fileinputformat.split.minsize=0
§ 控制Map和Reduce数量
合理的Map和Reduce数量,有利于提高作业性能。我们可以通过参数直接设置Reduce的数量,但无法直接指定Map的数量。参考computeSplitSize()方法,当输入文件指定时,Map的数量由SplitSize决定,我们可以通过修改dfs.blocksize和split.minsize来设定Split Size。上文我们建议使用保留系统默认的最小分片大小,所以我们只能通过修改dfs.blocksize参数来控制Map数量。值得注意的是我们可以有若干办法控制输入文件。
当Map平均输入很大,或者用时太长,通过以下办法可以增加Map数量
-事先采用Splittable的压缩格式,比如Lzo格式压缩输入文件。
-设置较小的Block Size
当Map平均输入过小,或者用时太短,通过以下办法可以减少Map数量
-事先合并输入文件,减少小文件 (小文件太多,就算Block Size再大,每个小文件都会占用一个Block)
-设置较大的Block Size
computeSplitSize()方法说明[i]:
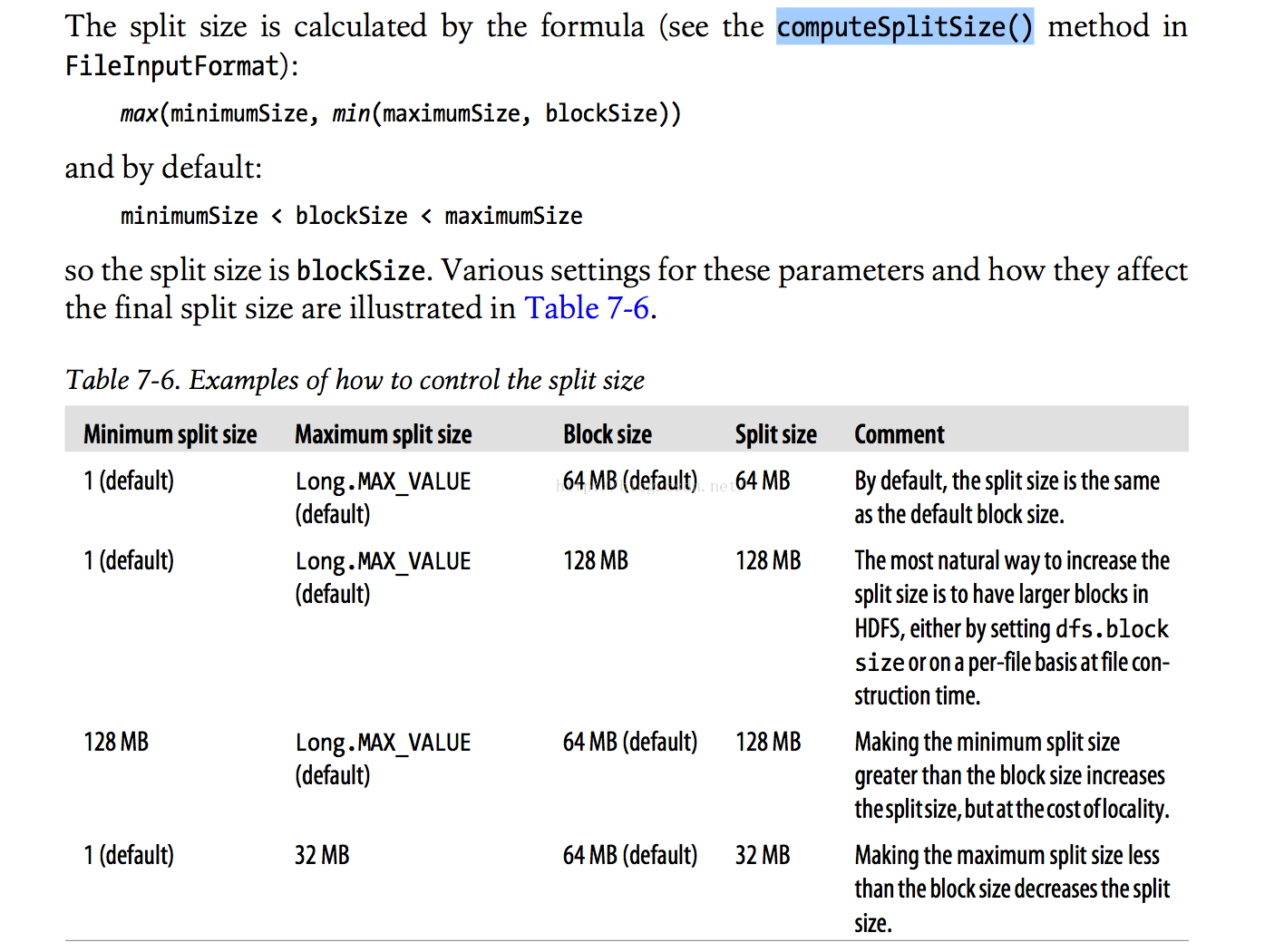
*上图为引用Hadoop The Definitive Guide 3rd Edition[i], 所列属性为Hadoop 1。在Hadoop 2中,部分属性名称已更新,比如Hadoop 1中dfs.block.size在Hadoop2中更新为dfs.blocksize.
eBay Eagle有关Map和Reduce数量的标杆:
Map作业满足以下条件之一,认为Map数量太多:
-输入 < 5 MB且用时 < 30秒
-用时 < 10秒
Map作业满足以下条件之一,认为Map数量太少:
-输入 > 1GB
-用时 > 10分钟
Reduce作业满足以下条件之一,认为Reduce数量不合理:
-输入 < 256MB 且总用时(包括Shuffle) < 5分钟 且 输出 < 256MB
-输入 > 10GB 且总用时(包括Shuffle) > 30分钟
-总用时(包括Shuffle) < 60秒
-总用时(包括Shuffle) > 1小时 且 用时(不包括Shuffle) > 30分钟
-输入 < 10MB 且用时(不包括Shuffle) < 5分钟 且 输出 < 2GB
-输出 > 10GB 且用时(不包括Shuffle) > 30分钟
Reduce数量推荐方案:
Reduce number=Max(input / 3 G, output / 2 GB,reduceTime / 10 minute)
指定Reduce数量的作业参数:
mapreduce.job.reduces=<Reduce number>
[i] eBay Eagle是eBay自主研发的系统,用于大型Hadoop集群管理,集监控、警示和智能修复功能于一体。eBayEagle即将开源,有望成为Apache的孵化项目。
[ii] http://my.oschina.net/mkh/blog/335395
[iii] Hadoop: TheDefinitive Guide, Third Edition. Hadoop: The Definitive Guide, Third Edition,ISBN: 9781449328917














 3732
3732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









