







目录
类加载
类加载过程
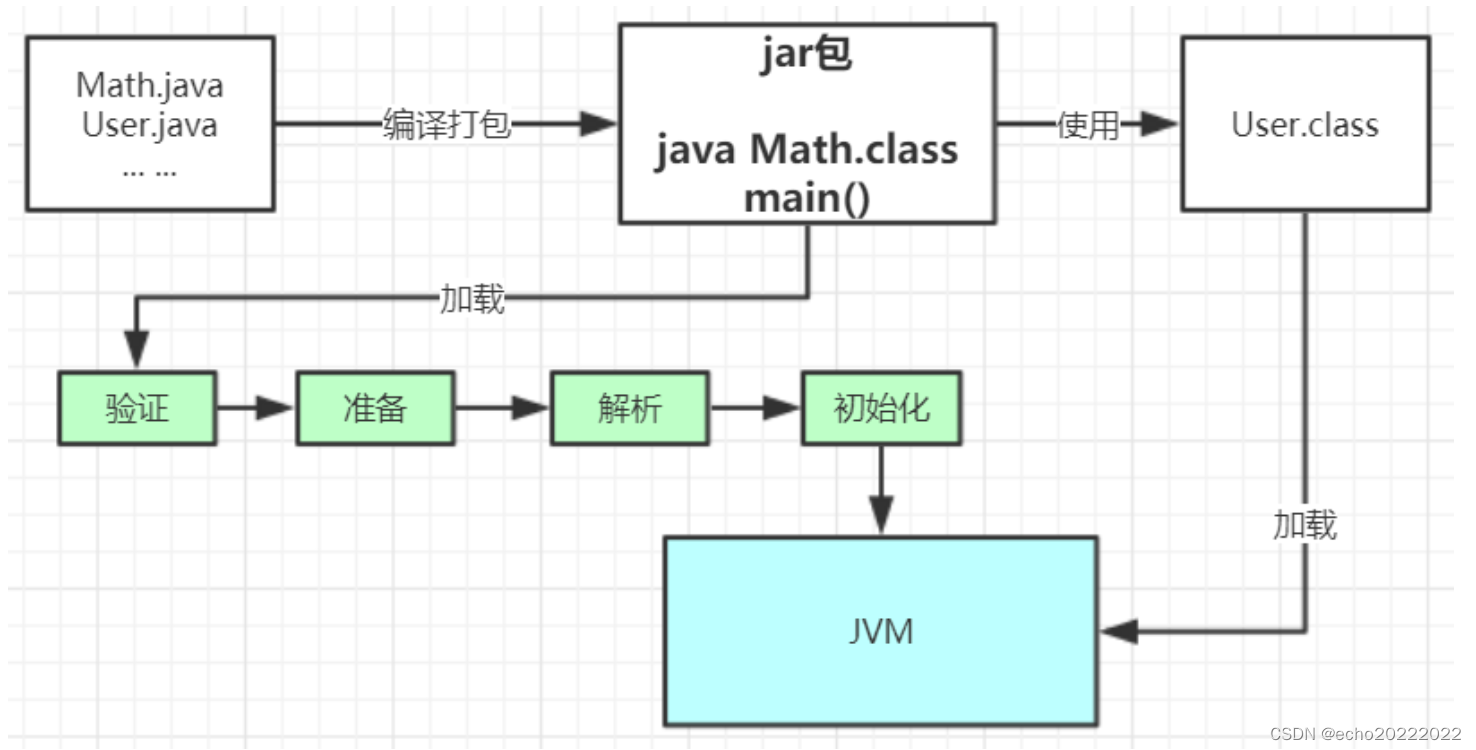
程序运行前,需要将相关的class字节码文件加载到jvm中,但并不是所有的class文件都需要加载,而是使用到哪些加载哪些。整个加载和使用过程包括加载、验证、准备、解析、初始化、使用、卸载。
- 加载阶段主要是把class文件的二进制字节流加载到jvm中;
- 验证阶段是对字节码的合法性进行验证,以避免不符合规范的字节码文件对jvm造成破坏;
- 准备阶段为静态变量分配内存并赋予初始值;
- 解析阶段将静态方法对应的符号引用替换成直接引用;
- 初始化阶段为静态变量赋予指定的值,执行静态代码块;
双亲委派机制

类的加载过程采用双亲委派机制,主要包含四种类型的加载器,分别是启动类加载器、扩展类加载器、应用类加载器和自定义类加载器,启动类加载器负责加载jre/lib目录下的核心jar包,比如rt.jar,扩展类加载器负责加载jre/lib/ext目录下的扩展jar包,应用类加载器负责加载classpath下的类,通常是第三方jar包和我们自己编写的程序。
双亲委派加载机制的过程其实很简单,在加载一个类的时候,入口通常是应用类加载器,之后应用类加载器会把加载请求逐层转给父类加载器,如果所有的父类加载器都加载不到的话,再由应用类加载器进行加载。简单的说,就是如果有类加载需求,则先让老子干,如果老子干不了儿子再自己干。
双亲委派机制的好处有两点:
- 第一是可以防止核心类库被恶意篡改;
- 第二是可以避免重复加载,如果父类加载器能够加载的话,就不会将加载请求再次转给子类加载去加载;
但是并不是在所有场景下都能使用双亲委派机制,比如tomcat这种web容器,由于web容器中存在多个应用程序,每个应用程可能依赖了不同的jar包或相同jar包的不同版本,另外tomcat本身的类库也不能与应用的类型相混淆,所以对于tomcat来说,它在某种程度上必须通过自定义类加载器的方式来打破双亲委派机制。
内存结构
整体结构

Jvm内存结构主要包括五个部分,分别是程序计数器、线程栈、本地线程栈、方法区、和堆内存五个部分。
- 其中堆是jvm最大的一块内存区域,也是进行jvm优化的主要内存区域,主要用来存储对象实例;
- 程序计数器用来记录每个线程当前运行的字节码行号,以便从线程上下文切换中恢复过来以后,程序能够回到正确的位置继续执行;
- 方法区早期称为永久代,现在称为元数据区空间,主要用来存储常量、静态变量和类的Class对象以及JIT编译后的代码;
- 线程栈主要用来存储当前线程方法调用的栈帧,栈帧是方法调用的抽象,里面包含了局部变量表、操作数栈、动态链接、方法出口等信息,在一个线程内,每一次方法调用和退出都对应了一个栈帧的入栈和出栈;
- 本地线程栈的作用和线程栈一样,只不过是针对本地方法调用的;
对于这五个部分,程序计数器、线程栈和本地线程栈都是线程私有的,不存在线程安全问题,而堆和方法区是所有线程共享的。
堆内存区域是jvm最重要的一块内存区域,jvm优化和常见故障都发生在这块内存区域中,整个堆总体分为两个部分:新生代和老年代,大小比例为2:1,其中新生代又分为一个Eden区和两个Servivor区,大小比例为8:1:1,在新生代发生的GC称为Minor GC或Young GC,Minor GC非常频繁并且执行速度会比较快,对于老年代发生的GC称为Major GC或Full GC,会出现Stop The World,Full GC发生的不频繁,但速度比较慢(避免出现Full GC有时候会作为JVM优化的一个目标)。新创建的对象一般会被分配到Eden区,发生Young GC时,要么被回收,要么在两个Servivor区来回移动,当到达最大GC年龄时,就会被移动到老年代中。
对象分配策略
- 对象优先分配在年轻代的Eden区;
- 大对象直接进入老年代(大对象的标准可以由jvm参数配置);
- 长期存活的对象进入老年代(默认GC分代年龄上限是15,可以通过参数配置);
- 动态年龄判断,在当前Servivor中,有一批对象的大小超过了Servivor大小的50%,那么GC年龄大于这批对象中GC年龄的最大值的对象将被直接放入老年代,这主要是为了使得能够长期存活的对象尽快的进入到老年代;
- Young GC后存活的对象如果Survivor放不下的话,把部分对象移动到老年代;
- 老年代内存分配担保机制,在进行Young GC时,会比较老年代剩余大小和新生代所有存活的对象的大小,如果小于,则会判断每次进行Minor GC后进入老年代的对象的平均大小,如果老年代剩余空间大小比这个平均大小大,那么就不会触发full GC,否则儿就会提前触发Full GC,当然,如果Minor GC后剩余的对象大小仍然大于老年大空间剩余大小,仍然会触发Full GC;
内存泄漏
- 长生命周期对象引用短生命周期对象;
- 没有将无用对象设置为null;
垃圾回收
可回收性判断
引用计数和可达性分析,引用计数无法解决循环依赖问题,所以已经不再被使用,可达性分析是从一系列的GC Root根对象出发,查找引用链,如果一个对象到GC Root根对象之间没有引用链,那么这个对象就会被标记为可回收,但是如果这个对象实现了Object的finalize方法,则这个对象在回收的时候会被放入一个队列中,jvm后台启动一个优先级比较低的线程去处理,如果在finalize方法中重新与GC Root根对象建立了引用链,那么将不会被回收。
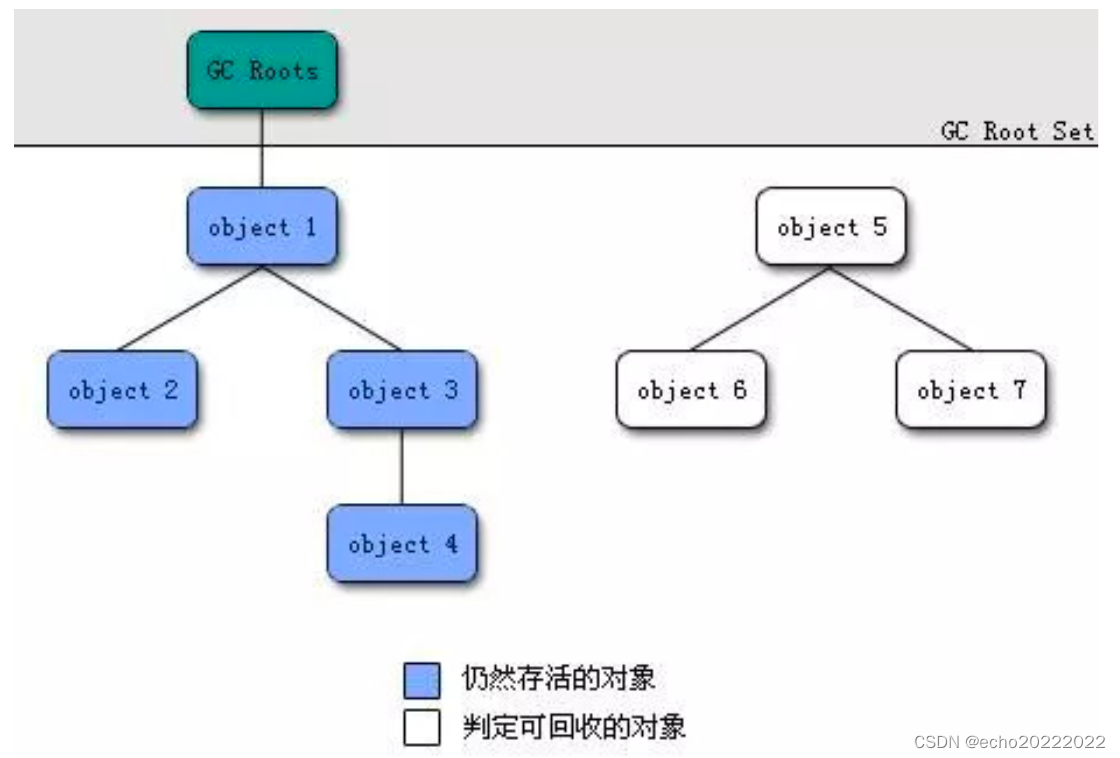
GC Root根对象包括线程栈和本地方法栈中的变量以及方法区中的常量或静态变量 。
引用类型
- 强引用:任何GC都不会把它回收;
- 软引用:发生GC后仍然没有可用空间,则会被回收,一般用在一些缓存框架上;
- 弱引用:发生GC后会被立即回收;
- 虚引用:最弱的一种引用,不知道是干什么的;
Class对象被回收的条件
- 类的所有对象都已经被回收;
- 加载该类的ClassLoader也已被回收;
- Class对象没有任何地方引用;
垃圾回收算法
现在jvm中常见的垃圾收集算法有标记清除算法、复制算法、标记整理算法、分代收集算法。
标记清除算法
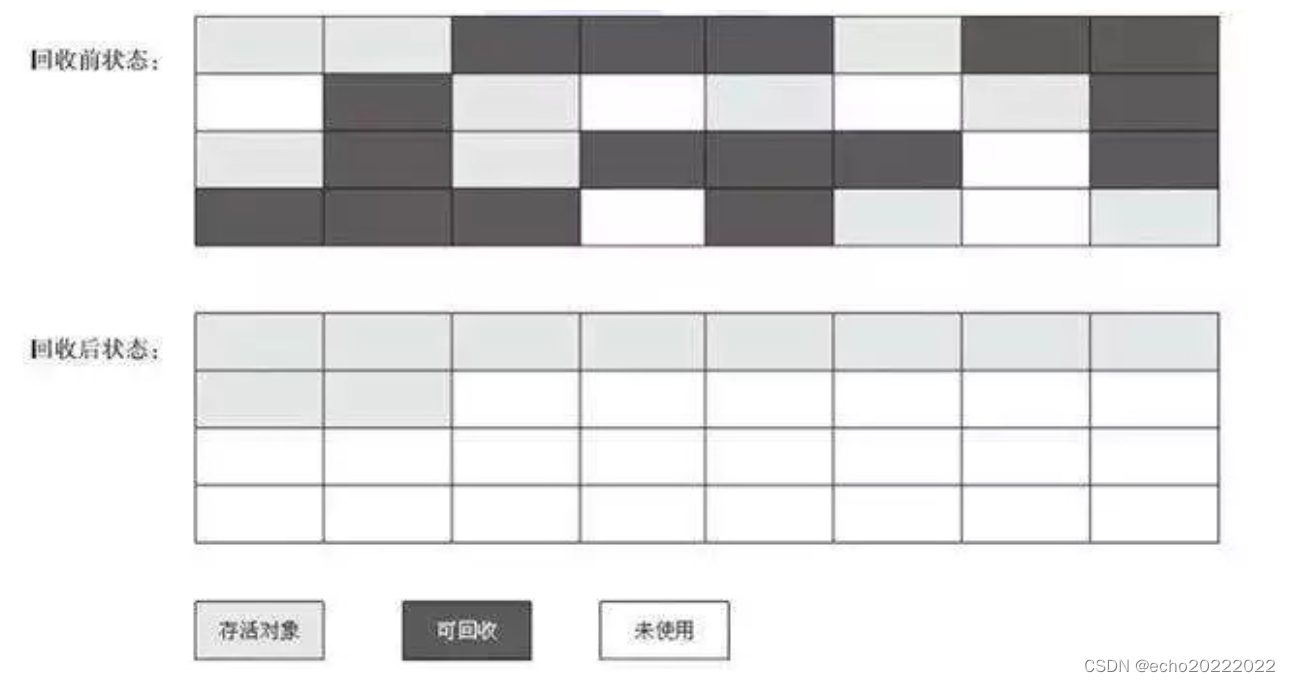
标记清除算法分为两个阶段:标记阶段和清除阶段,标记阶段标记哪些对象能够被回收,清除阶段将可以被清除的对象从内存中清除。这种算法会产生内存碎片。
复制算法

复制算法将可用内存分为两份,每次只使用其中一份,当满了以后直接将存活的对象复制到另外一个区域中,然后清空当前内存区域,这种算法的效率很高,但会导致可用内存减半。
标记整理算法
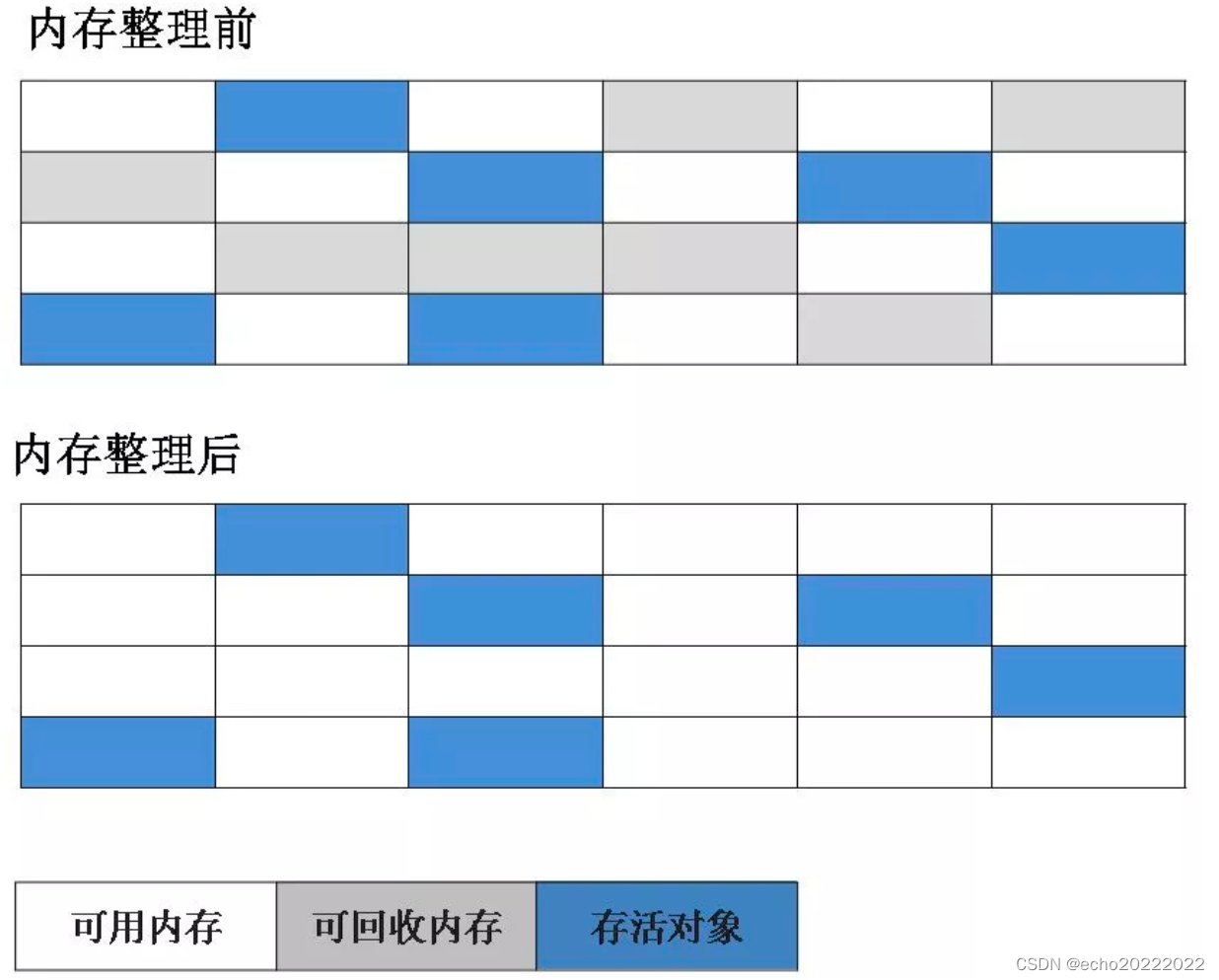
标记整理算法是在标记清除算法的基础上,对存活的对象进行整理,将其移动到内存了一边,从而避免出现内存碎片的问题。
分代回收算法
当前虚拟机都是根据对象实例的特点采用分代收集算法,分代收集算法并不是一个具体的算法,而是对已有垃圾收集算法的一种组合,虚拟机中的堆内存按照对象的特点分为新生代和老年代,新生代中的对象存活时间短,多数是朝生夕死,所以在新生代采用“复制算法”,老年代中的对象往往存活时间很长,所以采用“标记-清除算法”或“标记-整理算法”。复制算法的效率要比标记-清除或标记-整理高10倍以上。
JVM优化的思路其实就是尽量保证对象都在新生代中进行分配和回收,尽量不要让太多的对象进入老年代,从而避免对老年代进行频繁的垃圾回收,同时给JVM充足的内存大小,进一步避免新生代的垃圾回收过于频繁。
垃圾收集器
主流的垃圾收集器包括:Serial收集器、ParNew收集器、Parallel收集器、CMS收集器、G1收集器和ZGC。
如果说垃圾收集算法是方法论的话,那垃圾收集器就是方法论的具体实现,Java中并不存在一个放之四海皆准的垃圾收集器,我们能做的就是根据不同的场景选择不同的垃圾收集器。
Serial收集器

Serial收集器是jvm中最基础的、历史最悠久的垃圾收集器,从名字上来看就知道这是一个单线程的垃圾收集器,会出现“Stop The World”。Serial收集器在新生代采用复制算法,老年代采用标记-整理算法。
Serial Old收集器是Serial的老年代版本,一般是与Parallel收集器配合使用,也作为CMS收集器的降级方案,Serial收集器虽然是单线程的,但也简单高效,一般用在client模式下的jvm中。
ParNew收集器

ParNew收集器其实是Serial收集器的多线程版本,默认的垃圾收集线程数与cpu核数相同,但也可以通过参数-XX:ParallelGCThreads来调整,但一般不推荐这么干。ParNew收集器新生代采用复制算法,老年代采用标记-整理算法。ParNew收集器也能够与CMS收集器配合使用。
Parallel收集器
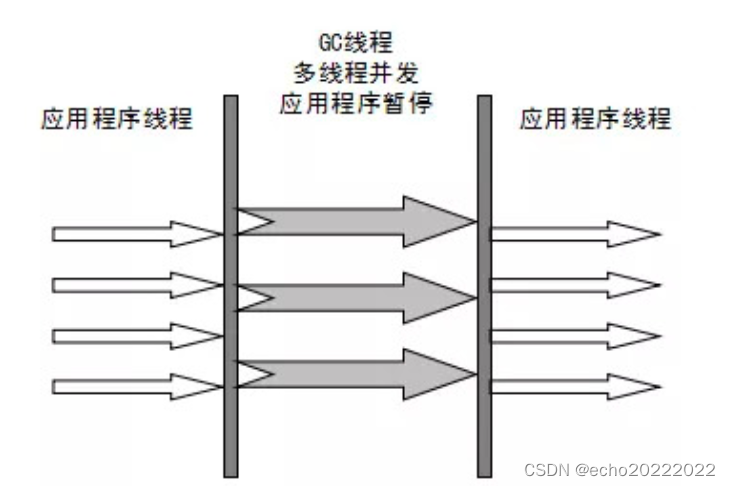
Parallel收集器是Server模式下的默认收集器,与ParNew收集器类似,它也是多线程执行,但不同的是Parallel收集器关注的是吞吐量,所谓吞吐量就是cpu用于执行用户代码的时间与cpu的总消耗时间的比值,Parallel收集器提供了很多配置参数给用户来找到最佳的平衡点,新生代采用复制算法,老年代采用标记-整理算法。Parallel Old是Parallel的老年代版本。
CMS收集器
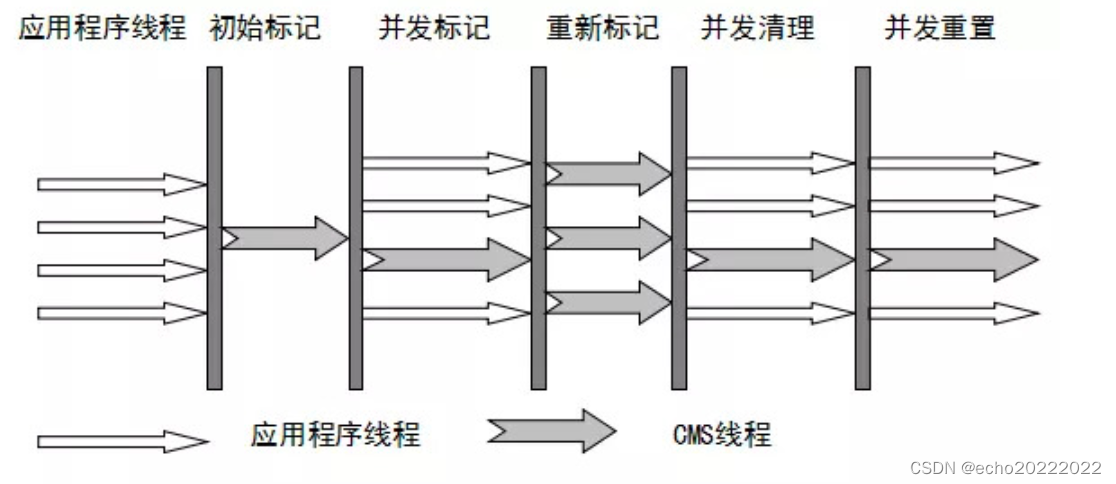
CMS是Concurrent Mark Sweep的缩写,这个收集器以最短停顿时间为目标,它非常适合在注重用户体验的应用中,是第一个真正意义上的并发收集器,能够基本上实现用户线程与GC线程同时执行。CMS收集器采用标记-清除算法(但是也可以通过配置参数来让其在执行完GC后对内存进行整理),是一个针对老年代的垃圾收集器。
整个垃圾收集过程包括初始标记、并发标记、重新标记、并发清理这几个阶段:
- 初始标记:暂停所有线程,标记处所有的GC Root根对象,速度非常快;
- 并发标记:放开所有用户线程和GC线程,使其并发执行,GC线程从GC Root根对象开始找不可达的垃圾对象;
- 重新标记:这一阶段主要标记由于用户线程执行造成的可达性发生变化的对象,这个阶段也会有stw,停顿时间比初始阶段略长,但仍然很快;
- 并发清理:用户线程和GC线程同时执行,GC线程清理所有垃圾对象;
CMS是一个非常优秀的并且非常常用的垃圾收集器,具有并发收集、低停顿时延的特点,但是它也有一些不足:
- 对cpu比较敏感(会和用户服务线程抢占资源);
- 无法处理浮动垃圾;
- 使用标记清除算法,会出现内存碎片(但可以通过配置参数让CMS进行内存整理);
- 由于无法处理浮动垃圾,可能会造成一次GC没有完成就又触发一次GC,此时jvm就会stop the world,然后将CMS降级为Serial Old;
G1收集器

G1收集器主要针对于大内存的服务,以可控GC停顿时间为目标。它将堆内存划分成多个大小相等的Region区域,最多可以有2048个Region,G1同样保留了年轻代和老年代的概念,但是没有进行物理隔离,比如一个Region之前有可能属于新生代,但在被回收再利用后,它可能变了成属于老年代的Region,也就是说Region的区域功能是动态变化的。
默认年轻代对堆内存的初始占比是5%,(也可以通过-XX:G1NewSizePercent设置新生代初始占比),在系统运行过程中,JVM会不断给新生代增加更多的Region,但是最多不超过60%(可以通过-XX:G1MaxNewSizePercent调整),新生代中,Eden:Survivor0:Survivor1的占比仍然是8:1:1。
G1收集器关于对象什么时候进入老年代的规则和其他的收集器基本一致,唯一不同的是对大对象的处理,G1中有专门用于存储大对象的Region区,叫做Humongous区,而不是让大对象直接进入老年代的Region中。在G1中,一个对象的大小如果超过了Region大小的50%,就会被放到Humongous中,如果一个对象过大,那么还有可能跨多个Region存储,这样就可以减少对老年代空间的占用,从而减少触发full gc的次数。
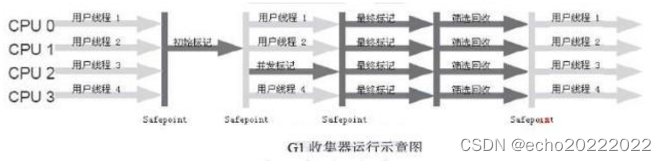
G1收集器的垃圾收集过程分为初始标记、并发标记、最终标记、筛选回收四个阶段,总体过程和CMS收集器类似,但还是有一些区别。
- 初始标记:暂停所有线程,标记GC root根对象,速度很快;
- 并发标记:与CMS的并发标记相同;
- 最终标记:与CMS的重新标记相同;
- 筛选回收:这个阶段首先会对所有待回收的Region进行回收价值和成本的评估,根据用户期望的GC停顿时间来制定回收计划,比如说老年代有1000个Region都满了,但是因为根据预期停顿时间,本次垃圾收只能停顿200ms,那么通过之前计算的回收成本得知,可能回收其中的800个刚好需要花费200ms,那么就只回收这800个Region,尽量把停顿时间控制在用户期望的范围内,G1的垃圾收集算法是复制算法,所以效率非常高,也几乎不存在内存碎片的问题;
G1收集器在后台维护了一个优先级列表,每次根据允许的停顿时间,优先选择回收价值最大的Region,比如一个Region需要花费200ms能够回收10MB,另外一个Region花50ms就能够回收20MB,那么在回收时间有限的情况下,当然会优先回收后面的Region。
G1收集器的特点:
- 并发加并行使得垃圾收集效率更高;
- 分代收集;
- 空间整合使得各个区域没有明显的界限,总体采用标记-清除算法,局部采用复制算法;
- 可预测停顿时间(-XX:MaxGCPauseMillis);
ZGC
略。
如何选择垃圾收集器
- 优先通过调整堆的大小让服务器自己来选择;
- 如果内存小于100M(client模式),使用Serial收集器;
- 如果是单核并且没有停顿时间方面的要求,选择Serial收集器;
- 如果是多核但对停顿时间没有明确要求,选择ParNew + CMS;
- 如果响应时间敏感,则使用ParNew + CMS;
- 对于大内存、高并发,采用G1;
VM参数
-Xmx 最大堆大小
-Xms 最小堆大小
-Xmn 新生代大小
-XX:MetaspaceSize 元数据空间大小
-XX:MaxMetaspaceSize 最大元数据空间大小
-XX:+PrintGCDetails #打印GC详情
-XX:+HeapDumpOnOutOfMemory -XX:HeapDumpPath=./ #内存一出事dump日志的存放位置
-XX:+UseSerialGC/-XX:+UseSerialOldGC
-XX:+UseParNewGC
-XX:+UseParallelGC/-XX:+UseParallelOldGC
-XX:+UseConcMarkSweepGC启用CMS
-XX:+ConcGCThreads并发的GC线程数
-XX:+UseCMSCompactAtFullCollectionFullGC之后做压缩整理
-XX:CMSFullGCsBeforeCompaction多少次FullGC之后压缩一次,默认是0
-XX:CMSInitiatingOccupancyFraction当老年代使用达到指定比例时触发Full GC
-XX:+CMSScavengeBeforeRemark在CMS GC前启动一次Minor GC,目的在于减少对老年代对象的引用,降低CMS GC在并发标记阶段的开销
-XX:+UseG1GC开启G1 GC
-XX:MaxGCPauseMillis指定G1 GC的停顿时间GC日志
对于java应用我们可以通过一些配置把程序运行过程中的gc日志全部打印出来,然后分析gc日志得到关键性指标,分析GC原因,调整JVM参数。
打印GC日志可以通过以下参数来开启:
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintGCDateStamps
-Xloggc:./gc.log//Young GC
2020-01-12T18:44:12.524-0800: 0.783:
[GC (Allocation Failure)
//新生代GC情况,GC前占用65536K,GC后占用5962K,新生代总大小76288K
[PSYoungGen: 65536K->5962K(76288K)]
//整个堆内存GC前被占用65536K,GC后被占用5978K,总对内存大小251392K
65536K->5978K(251392K),
//本次GC总耗时
0.0075097 secs]
[Times: user=0.02 sys=0.00, real=0.01 secs]
//Young GC
2020-01-12T18:44:12.741-0800: 1.001:
[GC (Allocation Failure)
[PSYoungGen: 71498K->7583K(76288K)]
71514K->7607K(251392K),
0.0095106 secs]
[Times: user=0.02 sys=0.01, real=0.01 secs]
//元空间GC
2020-01-12T18:44:13.000-0800: 1.259:
[GC (Metadata GC Threshold)
[PSYoungGen: 67335K->8855K(76288K)]
67359K->8887K(251392K),
0.0080355 secs]
[Times: user=0.03 sys=0.00, real=0.00 secs]
2020-01-12T18:44:13.008-0800: 1.267:
//这是一次Full GC,原因是元空间内存不足
[Full GC (Metadata GC Threshold)
//新生代回收情况,回收前占用8855K,回收后占用0K,整个新生代大小76288K
[PSYoungGen: 8855K->0K(76288K)]
//老年代回收情况,GC前占用32K,GC后8479K,整个老年代大小105472K,
[ParOldGen: 32K->8479K(105472K)]
//8887K表示GC前整个堆内存被占用的大小,8479K表示GC后整个堆内存被占用的大小
8887K->8479K(181760K),
//GC前元空间的占用大小20627K,GC后元空间的占用大小20626K,元空间总大小1067008K
[Metaspace: 20627K->20626K(1067008K)],
//本次GC总耗时
0.0310216 secs]
[Times: user=0.11 sys=0.01, real=0.03 secs]
2020-01-12T18:44:14.905-0800: 3.164: [GC (Metadata GC Threshold) [PSYoungGen: 66899K->14847K(154112K)] 79666K->29321K(259584K), 0.0140711 secs] [Times: user=0.06 sys=0.01, real=0.01 secs]
2020-01-12T18:44:14.919-0800: 3.178: [Full GC (Metadata GC Threshold) [PSYoungGen: 14847K->0K(154112K)] [ParOldGen: 14474K->21740K(167936K)] 29321K->21740K(322048K), [Metaspace: 33815K->33815K(1079296K)], 0.0512850 secs] [Times: user=0.22 sys=0.01, real=0.06 secs监控工具
辅助工具
#实时查看磁盘io(每2秒钟采样一次,循环1000次)
>iostat -dxk 2 1000
# 查看物理CPU个数
>cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 查看物理CPU个数
>cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 查看每个物理CPU中core的个数(即核数)
>cat /proc/cpuinfo| grep "cpu cores"| uniq
# 查看逻辑CPU的个数
>cat /proc/cpuinfo| grep "processor"| wc -l
#查看CPU信息(型号)
>cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
#查看Linux 内核
>cat /proc/version
#查看linux 系统版本
>cat /etc/issue
>free -h #查看内存使用情况
top - 23:43:48 up 230 days, 6:57, 1 user, load average: 0.00, 0.02, 0.00
Tasks: 194 total, 1 running, 193 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.1%us, 0.1%sy, 0.0%ni, 99.9%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 16333884k total, 10743876k used, 5590008k free, 292856k buffers
Swap: 0k total, 0k used, 0k free, 5408124k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
31876 work 20 0 8206m 1.2g 15m S 2.0 7.6 48:43.68 java
1 root 20 0 19360 1536 1228 S 0.0 0.0 0:02.47 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.70 kthreadd
3 root RT 0 0 0 0 S 0.0 0.0 0:01.23 migration/0
>top -Hp pid #查看某些进程内的线程的资源消耗排名
top - 23:44:53 up 230 days, 6:59, 1 user, load average: 0.00, 0.02, 0.00
Tasks: 433 total, 0 running, 433 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.1%us, 0.1%sy, 0.0%ni, 99.9%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 16333884k total, 10746728k used, 5587156k free, 292856k buffers
Swap: 0k total, 0k used, 0k free, 5408144k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
31876 work 20 0 8206m 1.2g 15m S 0.0 7.6 0:00.00 java
31882 work 20 0 8206m 1.2g 15m S 0.0 7.6 0:32.99 java
31883 work 20 0 8206m 1.2g 15m S 0.0 7.6 0:02.14 java
#通过ps页可以查看消耗资源最多的线程id
>ps -mp 3878 -o THREAD,tid,time
USER %CPU PRI SCNT WCHAN USER SYSTEM TID TIME
work 0.4 - - - - - - 00:04:41
work 0.0 19 - futex_ - - 3878 00:00:00
work 0.0 19 - futex_ - - 3879 00:00:24
work 0.0 19 - futex_ - - 3880 00:00:00
work 0.0 19 - futex_ - - 3881 00:00:00
work 0.0 19 - futex_ - - 3882 00:00:00
work 0.0 19 - futex_ - - 3883 00:00:00
work 0.0 19 - futex_ - - 3884 00:00:00
#(tid) #将线程id转成16进制
>printf "%x\n" 31882
7c8a
>jstack 31876 | grep 7c8a -A60 #根据线程id(16进制)查看某些线程在干什么
"DestroyJavaVM" #201 prio=5 os_prio=0 tid=0x00007f28c800a800 nid=0x7c8a waiting on condition [0x0000000000000000]GC表示新生代GC,Full GC表示老年代GC,后面括号内的内容表示发生GC的原因,Allocation Failure表示Eden区内存不足导致新对象创建失败,Metadata GC Threshold表示元空间不足导致的GC,对于GC日志的分析,也可以通过Universal JVM GC analyzer - Java Garbage collection log analysis made easy自动分析。
IBM HeapAnalyzer
#导出dump
>jmap -dump:format=b,file=./eureka.hprof 3087
>java -Xmx2g -jar ha*.jar
导入dump文件useful-scripts
https://github.com/oldratlee/useful-scripts
>git clone git://github.com/oldratlee/useful-scripts.git
>cd useful-scripts
# 使用Release分支的内容
>git checkout release-2.x
# 更新脚本
>git pull
>./show-busy-java-threads pid
>./tcp-connection-state-counterarthas
#阿里云视频教程
https://start.aliyun.com/handson-lab?category=arthas
#github地址
https://github.com/alibaba/arthas
#arthas说明书
https://arthas.aliyun.com/en/doc/web-console.html#scrollback-url-parameters
>/data/tools/arthas/as.sh pid #进入当前进程的监控环境
>dashborad #进入dashboard监控概览
ID NAME GROUP PRIORITY STATE %CPU DELTA_TIME TIME INTERRUPTED DAEMON
-1 C2 CompilerThread2 - -1 - 0.0 0.000 0:29.388 false true
-1 C2 CompilerThread0 - -1 - 0.0 0.000 0:27.664 false true
8 DataCarrier.DEFAULT.Consumer.0.Thread main 5 TIMED_WAITING 0.0 0.000 0:26.544 false true
-1 C2 CompilerThread1 - -1 - 0.0 0.000 0:25.344 false true
240 DestroyJavaVM main 5 RUNNABLE 0.0 0.000 0:25.269 false false
118 DataPublisher main 5 TIMED_WAITING 0.0 0.000 0:20.475 false true
-1 VM Thread - -1 - 0.0 0.000 0:18.780 false true
-1 VM Periodic Task Thread - -1 - 0.0 0.000 0:15.006 false true
-1 C1 CompilerThread3 - -1 - 0.0 0.000 0:12.408 false true
10 SkywalkingAgent-6-JVMService-produce-0 main 5 TIMED_WAITING 0.0 0.000 0:7.176 false true
117 PollingServerListUpdater-0 main 5 WAITING 0.0 0.000 0:5.446 false true
122 PollingServerListUpdater-1 main 5 TIMED_WAITING 0.0 0.000 0:5.407 false true
243 DiscoveryClient-CacheRefreshExecutor-0 main 5 WAITING 0.0 0.000 0:4.380 false true
26 grpc-nio-worker-ELG-1-3 main 5 RUNNABLE 0.0 0.000 0:3.631 false true
15 SkywalkingAgent-10-ProfileSendSnapshotServi main 5 TIMED_WAITING 0.0 0.000 0:2.611 false true
38 Catalina-utility-1 main 1 WAITING 0.0 0.000 0:2.351 false false
39 Catalina-utility-2 main 1 TIMED_WAITING 0.0 0.000 0:2.159 false false
7 SkywalkingAgent-1-LogFileWriter-0 main 5 TIMED_WAITING 0.0 0.000 0:1.632 false true
244 DiscoveryClient-HeartbeatExecutor-0 main 5 WAITING 0.0 0.000 0:1.590 false true
110 http-nio-20062-ClientPoller main 5 RUNNABLE 0.0 0.000 0:1.526 false true
11 SkywalkingAgent-7-JVMService-consume-0 main 5 WAITING 0.0 0.000 0:1.411 false true
99 http-nio-20062-BlockPoller main 5 RUNNABLE 0.0 0.000 0:1.270 false true
12 SkywalkingAgent-8-ServiceManagementClient-0 main 5 WAITING 0.0 0.000 0:1.227 false true
100 http-nio-20062-exec-1 main 5 WAITING 0.0 0.000 0:1.135 false true
91 I/O dispatcher 1 main 5 RUNNABLE 0.0 0.000 0:1.129 false false
-1 Concurrent Mark-Sweep GC Thread - -1 - 0.0 0.000 0:1.075 false true
78 Abandoned connection cleanup thread main 5 TIMED_WAITING 0.0 0.000 0:1.065 false true
96 I/O dispatcher 6 main 5 RUNNABLE 0.0 0.000 0:1.007 false false
93 I/O dispatcher 3 main 5 RUNNABLE 0.0 0.000 0:1.006 false false
92 I/O dispatcher 2 main 5 RUNNABLE 0.0 0.000 0:0.985 false false
Memory used total max usage GC
heap 351M 1981M 1981M 17.72% gc.parnew.count 39
par_eden_space 253M 532M 532M 47.66% gc.parnew.time(ms) 886
par_survivor_space 4M 66M 66M 7.26% gc.concurrentmarksweep.count 0
cms_old_gen 92M 1382M 1382M 6.68% gc.concurrentmarksweep.time(ms) 0
nonheap 177M 183M 1776M 10.01%
code_cache 51M 51M 240M 21.44%
metaspace 111M 116M 512M 21.84%
compressed_class_space 14M 15M 1024M 1.41%
direct 498K 498K - 100.00%
mapped 0K 0K - 0.00%
#查看某个线程的具体信息
>thred tid
#查看top n占用cpu的线程信息
>thread -n 3
#查看阻塞了其他线程的线程信息
>thread -b
#dump堆内存
>heapdump /path/dump.hprof内置的工具
jmap
查看堆内地使用情况
>jmap -heap pid
#堆内存配置
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 2147483648 (2048.0MB)
NewSize = 697892864 (665.5625MB)
MaxNewSize = 697892864 (665.5625MB)
OldSize = 1449590784 (1382.4375MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 536870912 (512.0MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 536870912 (512.0MB)
G1HeapRegionSize = 0 (0.0MB)
#堆内存使用情况
Heap Usage:
## 新生代
New Generation (Eden + 1 Survivor Space):
capacity = 628162560 (599.0625MB)
used = 460635896 (439.29662322998047MB)
free = 167526664 (159.76587677001953MB)
73.33068306395083% used
## 新生代-Eden区
Eden Space:
capacity = 558432256 (532.5625MB)
used = 435952440 (415.7566452026367MB)
free = 122479816 (116.80585479736328MB)
78.06720247907742% used
## 新生代From区
From Space:
capacity = 69730304 (66.5MB)
used = 24683456 (23.53997802734375MB)
free = 45046848 (42.96002197265625MB)
35.39846319901316% used
## 新生代To区
To Space:
capacity = 69730304 (66.5MB)
used = 0 (0.0MB)
free = 69730304 (66.5MB)
0.0% used
CMS(老年代)
concurrent mark-sweep generation:
capacity = 1449590784 (1382.4375MB)
used = 86460360 (82.45502471923828MB)
free = 1363130424 (1299.9824752807617MB)
5.964466727735488% used查看堆内存对象分布
>jmap -histo pid > ./obj_info.txt
num #instances #bytes class name
----------------------------------------------
1: 1308718 110879696 [C
2: 668395 50510096 [Ljava.lang.Object;
3: 27597 44984520 [I
4: 43498 30819728 [B
5: 784962 18839088 java.lang.String
6: 725375 17409000 java.util.ArrayList
7: 1012467 16557672 [Ljava.lang.Class;
8: 294890 11795600 java.util.HashMap$KeyIterator
9: 127449 11641712 [Ljava.util.HashMap$Node;
10: 492312 11502688 [Ljava.lang.String;
11: 450652 10815648 java.util.concurrent.ConcurrentLinkedQueue$Node
12: 293937 9405984 java.util.AbstractList$Itr
13: 284704 9110528 java.util.HashMap$Node
14: 136308 6542784 java.util.concurrent.locks.ReentrantReadWriteLock$NonfairSync
15: 122961 5902128 java.util.HashMap
16: 86607 5542848 java.util.stream.ReferencePipeline$2
17: 137010 5480400 java.util.LinkedHashMap$Entry
18: 170179 5445728 java.util.concurrent.locks.AbstractQueuedSynchronizer$Node
19: 57054 5020752 java.lang.reflect.Method
20: 86819 4861864 java.util.stream.ReferencePipeline$Head
21: 140643 4500576 java.util.concurrent.ConcurrentHashMap$Node导出堆内存dump
>jmap -dump:format=b,file=./service.hprof pidjstack
导出进程栈
jstack pidjinfo
#查看jvm参数
>jinfo -flags pid
Attaching to process ID 7788, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.60-b23
Non-default VM flags: -XX:CICompilerCount=3 -XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:+ExplicitGCInvokesConcurrent -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=null -XX:InitialHeapSize=2147483648 -XX:MaxHeapSize=2147483648 -XX:MaxMetaspaceSize=536870912 -XX:MaxNewSize=348913664 -XX:MaxTenuringThreshold=6 -XX:MetaspaceSize=536870912 -XX:MinHeapDeltaBytes=196608 -XX:NewSize=348913664 -XX:OldPLABSize=16 -XX:OldSize=1798569984 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+ScavengeBeforeFullGC -XX:+UseCMSInitiatingOccupancyOnly -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseFastUnorderedTimeStamps -XX:+UseParNewGC
Command line: -Xms2g -Xmx2g -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -javaagent:/data/skywalking/skywalking-agent.jar -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+CMSClassUnloadingEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+ScavengeBeforeFullGC -XX:+ExplicitGCInvokesConcurrent -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/base-gongshang/runtime/../jvm/dump/ -Dclient.encoding.override=UTF-8 -Dfile.encoding=UTF-8 -Djava.security.egd=file:/dev/./urandom -Xloggc:/data/base-gongshang/runtime/../jvm/gc//gc.log -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./gc/heap_%p.hprof -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=20110 -Djava.util.concurrent.ForkJoinPool.common.parallelism=100 -DSW_AGENT_NAME=base-gongshang -DSW_AGENT_INSTANCE_NAME=host132
#查看系统变量
>info -sysprops pidjstat
查看垃圾收集情况(频率为每秒钟一次)
jstat -gc pid 1000
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
15872.0 22016.0 15871.0 0.0 380416.0 196887.1 131072.0 24833.9 48304.0 46270.9 6576.0 6121.6 6 0.097 2 0.062 0.160
15872.0 22016.0 15871.0 0.0 380416.0 196887.1 131072.0 24833.9 48304.0 46270.9 6576.0 6121.6 6 0.097 2 0.062 0.160
>jstat -gccapacity 54726 1000
NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC
87040.0 1397760.0 463872.0 15872.0 22016.0 380416.0 175104.0 2796544.0 131072.0 131072.0 0.0 1091584.0 48304.0 0.0 1048576.0 6576.0 6 2
87040.0 1397760.0 463872.0 15872.0 22016.0 380416.0 175104.0 2796544.0 131072.0 131072.0 0.0 1091584.0 48304.0 0.0 1048576.0 6576.0 6 2
#新生代垃圾收集信息
>jstat -gcnew 54726 1000
S0C S1C S0U S1U TT MTT DSS EC EU YGC YGCT
15872.0 22016.0 15871.0 0.0 5 15 22016.0 380416.0 196887.1 6 0.097
15872.0 22016.0 15871.0 0.0 5 15 22016.0 380416.0 196887.1 6 0.097
#老年代垃圾收集信息
>jstat -gcold 54726 1000
MC MU CCSC CCSU OC OU YGC FGC FGCT GCT
48304.0 46270.9 6576.0 6121.6 131072.0 24833.9 6 2 0.062 0.160
48304.0 46270.9 6576.0 6121.6 131072.0 24833.9 6 2 0.062 0.160
#堆内存使用情况
>jstat -gccapacity 54726 1000
NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC
87040.0 1397760.0 463872.0 15872.0 22016.0 380416.0 175104.0 2796544.0 131072.0 131072.0 0.0 1091584.0 48304.0 0.0 1048576.0 6576.0 6 2
87040.0 1397760.0 463872.0 15872.0 22016.0 380416.0 175104.0 2796544.0 131072.0 131072.0 0.0 1091584.0 48304.0 0.0 1048576.0 6576.0 6 2
#新生代内存使用情况
jstat -gcnewcapacity 54726 1000
NGCMN NGCMX NGC S0CMX S0C S1CMX S1C ECMX EC YGC FGC
87040.0 1397760.0 463872.0 465920.0 15872.0 465920.0 22016.0 1396736.0 380416.0 6 2
87040.0 1397760.0 463872.0 465920.0 15872.0 465920.0 22016.0 1396736.0 380416.0 6 2
#老年代内存使用情况
jstat -gcoldcapacity 54726 1000
OGCMN OGCMX OGC OC YGC FGC FGCT GCT
175104.0 2796544.0 131072.0 131072.0 6 2 0.062 0.160
175104.0 2796544.0 131072.0 131072.0 6 2 0.062 0.160
#元空间内存使用情况
>jstat -gcmetacapacity 54726 1000优化案例
如何解决内存泄漏问题
- 使用一些城市的缓存框架(内部有比较成熟的内存淘汰策略)
- 不再使用的对象及时置为null
总体优化方向
运行期间jvm对于外界来说是一个黑盒,所以需要一些工具和方法来勾画出jvm的运行情况。利用jstat可以得到每个区域的gc情况和内存使用情况,有了这些数据做支撑就可按照一定的思路优化jvm,比如调整对内存大小、新生代大小、Eden区和Servivor区的比例、老年代大小、大对象阈值、进入到老年代的gc年龄等参数。
举例来说,可以通过jstat -gc pic 1000 10来观察Eden区的内存变化来预估每秒钟对象增长情况,但是也要根据具体的情况来选择合理的时间段(比如很多系统都是有使用高峰时间的),然后根据对象增长速率和Eden区的大小评估出Young GC发生的频率,同时配合GC log来确认。
对jvm的优化可以从两个方面来看,一个是对于还未发布的服务的jvm的优化,另一个是对线上正在运行的jvm的优化。对于未上线的服务来说其实更多的是一种评估和测试,以此来找到一个能够让程序高效、稳定运行的平衡点,通常的做法是找一条主线业务,然后梳理出走完一个完整业务流程涉及的对象实例并根据对应的数据类型来评估创建对象的总大小,但是一个完整的系统不可能只包含主线业务还会包含一些周边功能,所以一般要对评估结果放大20倍进行兜底,然后参考或评估线上流量就可以计算出单位时间内产生的对象的总大小,这样基本就可以评估出堆内存的总大小、Eden和Servivor大小比例,因为要确保新生代能撑住业务流量同时也要保证young gc不能过于频繁,最后再在准生产环境进行压测,反复调整相关参数以此找到一个最合理的配置。而对于线上服务的jvm优化,与其说是优化不如说是救火,因为正常情况下程序员们很少会去碰那些运行良好的服务除非出现了故障,线上jvm故障最常见的就是发生OOM溢出和用户响应变慢的情况。
内存溢出一般有两种原因,一是线上流量突增导致内存撑不住(但如果服务做了限流 这种原因就可以排除),这种情况只能通过增加及其的配置或对服务进行水平扩容来解决,另外一个原因是由于代码原因导致内存泄漏,造成无用对象大量占用老年代空间,最终导致内存溢出,这些情况可先通过jmap -histo pid来分析内存中的对象实例分布情况,看是否存在某个数量很多的对象,然后再结合业务代码来分析造成内存泄漏的原因。
对于响应变慢这种情况一般有两个原因,一个是因有线程大量占用cpu资源,一个是full gc过于频繁导致jvm停顿。cpu被线程大量占用的情况是比较常见的,当服务器负载过高时一般会第一时间触发报警,这个时候需要登录服务器查看消耗cpu的进程,如果是java进程那么通过top命令找到占用cpu最多的线程,然后将线程id转成16进制后通过jstack找到线程栈,查看线程正在做什么,然后结合业务代码找出具体的原因。
- young gc过于频繁并且新生代大小,导致young gc后存活的对象太多都进入到了老年代;
- servivor太小且young gc后存活的对象太多,触发动态年龄判断机制导致对象进入老年代;
- 没有开启老年代分配担保机制;
- 对于大内存服务没有使用G1收集器导致GC过程太慢;
其他
#Understanding Linux CPU Load - when should you be worried?
https://scoutapm.com/blog/understanding-load-averages














 2387
2387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











