






一些思考
不知不觉做程序员已经快10年了,回顾这10年的开发历程,从一开始的小公司,到后来的互联网公司,负责的项目也从简单的Servlet服务到后来的分布式系统,再到后来的基础架构,接触的事情越来越复杂,经验也越来越丰富,但总有一种感觉:徒有其表。其实原因就在于得来这十年的工作经验都是由外界驱动的,被无数个产品需求和技术需求推着往前走,而从内向外主动思考的时候并不占大多数。
如果想在这条路上再继续走下去,向内挖掘自己是必不可少的过程,这需要有从头开始的心态,就像所有的开发者都是从hello world开始的一样,要再一次从hello world出发。抛开复杂的框架、方案、概念等等,从代码出发,精进自己的技艺,所以《代码整洁之道》是一个很适合的“hello world”,一切从代码出发,再向外扩展。
看起来干净的代码更不容易存在bug,且更容易扩展和维护”。
先想想自己心目中的整洁代码,在问自己这个问题的时候,被震惊了,因为只要稍加思考,就能想出很多编写整洁代码的方式,但是在很长的一段时间里,自己只是机械的完成需求,已经很长时间没有思考如何更优雅的编写代码了。
-
功能单一的类和功能单一的方法;
-
清晰的命名;
-
更好的代码结构;
-
充分&全面的单元测试;
-
清晰的接口定义;
但是当要把这些看似正确的准则付诸落地的时候,好像又少了抓手,不知道应该从何做起,这其实就是以前在这方面少有总结的缘故。
格式
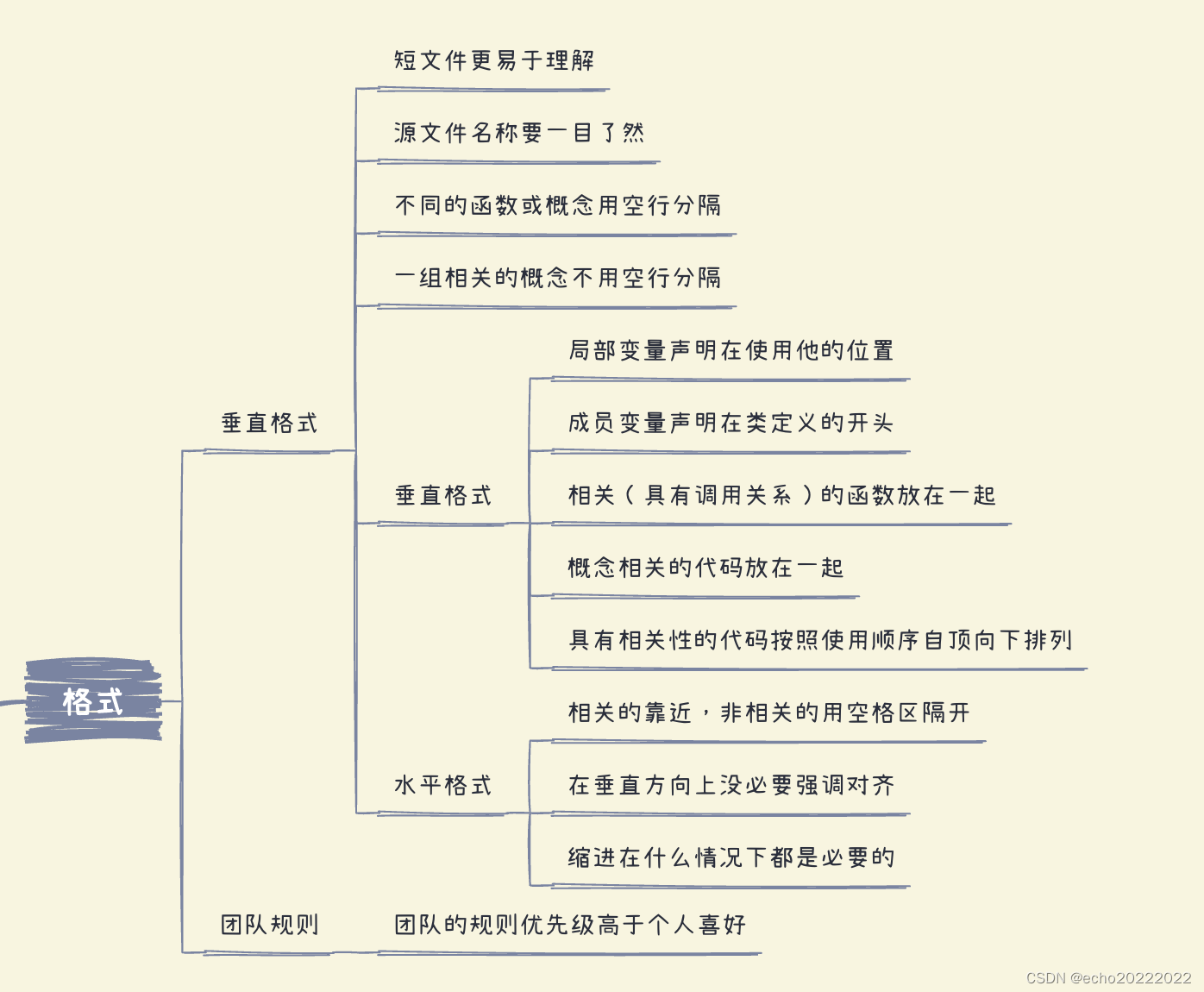
代码格式关乎沟通,而沟通是专业开发者的头等大事。原始代码的风格对以后可能发生的修改行为产生深远的影响,原始代码被修改后很久,其风格和可读性仍会影响到可维护性和扩展性,即便代码已经不复存在,你的风格和律条仍然存活。
| 垂直格式 | 短文件通常比长文件易于理解 |
| 源文件的名称应该直接了当,一目了然 | |
| 在垂直方向上,不同的函数或概念要用明显的空行进行分隔 | |
| 在垂直方向上,相同的概念或一组动作没必要放置额外的空行进行分隔 | |
| 垂直距离: 1. 局部变量声明在使用他的位置 2. 成员变量声明在类定义的开头 3. 相关(具有调用关系)的函数放在一起 4. 概念相关的代码放在一起 5. 具有相关性的代码按照使用顺序自顶向下排列 | |
| 横向格式 | 水平方向上,相关性的靠近,非相关性的空格区隔,赋值、运算符、多参数等 |
| 在垂直方向上没必要强调对其,因为那是在强调根本不重要的东西 | |
| 缩进在什么情况下都是必要的 | |
| 团队规则 | 每个开发者都有自己喜欢的格式规则,但在一个团队中,就是团队锁了算,每个人都要遵守 |
有意义的命名

| 原则 | 说明 |
| 名副其实 | 词要达意,能清晰地表明被命名对象的意思 |
| 避免误导 |
|
| 做有意义的区分 |
|
| 使用读得出来的名字 | 可读的名字更容易记忆和与人讨论; |
| 避免使用编码 | 在命名中使用特定的前缀大多数时候是没用的,开发人员很快就会通过后面的名字来了解含义; |
| 每个概念对应一个词 | 一以贯之的命名简直是天降福音; |
| 不同类型的命名对象的一些命名规则 |
|
命名对象
注释

注释的恰当用法是弥补我们在用代码表达意图时遭遇到的失败,要极力避免注释,因为程序员很难一直保持注释的正确性,如果注释与代码不符,将会带来更大的麻烦。
唯一的好注释是想办法不去写注释,不好的注释一般都是糟糕代码的支撑或借口,或者对错误决策的修正。
| 规则 | 说明 | 反例 |
| 注释不能美化糟糕的代码 | 与其提供注释,不如重构你的代码 | |
| 用代码来阐述意图 | ||
| 好注释 | 法律信息 | |
| 提供信息的注释。但更好的办法是通过函数名来传达信息 | ||
| 对意图的解释 | ||
| 阐释。对某些晦涩难懂的内容进行解释 | ||
| 警示。警告可能会出现某种后果的注释 | ||
| TODO注释 | ||
| 坏注释 | 喃喃自语 | |
| 多余的注释。读代码能理解的就不要写注释了 | ||
| 误导性的注释。 | ||
| 过度的java doc真没什么用 | ||
| 日志式的注释不能给理解代码逻辑带来帮助 | ||
| 废话注释 | ||
| 注释掉的代码 | ||
| 非公共代码中的java doc |
函数
大师级程序员把系统当故事来讲,而不是当程序来写,编程的真正目的在于讲述系统故事,而你编写的函数必须干净利落的拼装在一起,形成一种精确而清晰的语言,帮助你讲好故事。

| 规则 | 说明 | 反例 |
| 短小 | 一个函数控制在3-5行,最多不要超过10行 | |
| 只做一件事 | 一个函数只做一件事,不要多件事混在一起 | |
| 每个函数一个抽象层次 | 同一个抽象层次的逻辑是有前后关联的,一个函数内只包含同一个层次的抽象,便于理解 | |
| 使用描述性的名称 | 1. 描述性的名称具有注释的作用; 2. 函数约短小,功能月集中,就越便于取个好名字; 3. 长的、具有描述性的名字好过短的、没有描述性的名字; | |
| 函数参数 | 参数要尽量少,最好不好超过三个,超过三个是,用对象作为入参 | |
| 参数越多,就越需要使用者了解一些内部的细节 | ||
| 参数越多,越难进行单元测试 | ||
| 不应该利用函数参数来返回结果,例如引用传递 | ||
| 一元函数的两种形式: 1. 对参数进行转换; 2. 事件函数(副作用函数); | ||
| 使用boolean类型的参数是一种不明智的选择,因为这说明了函数不止做了一件事 | ||
| 二元和三元函数虽然也比较容易理解,但是应该努力将其转换成一元函数 | ||
| 如果函数的参数过多,就应该将其封装为对象 | ||
| 无副作用 | 1. 不做与函数对外提供的功能不相符的一些隐藏动作; 2. 不使用输出参数; | |
| 分隔指令与询问 | 函数要么做什么事,要么回答什么事,二者不可兼得,否则回导致混乱 | |
| 使用异常替代返回错误码 | 1. 把try..catch从主流程中分离; 2. 错误处理就是一件事,try..catch就是一件事; 3. 返回错误码意味着对Error Code枚举的依赖; |
类

| 类的组织 | 1. 按照静态变量、实例变量、方法的顺序组织类的内容; 2. 要尽量保持类的封装性; |
| 类应该短小 | 1. 不要让过多的权责集中在一个类中; 2. 保持内聚,如果不够内聚,就要拆分出新的类; 3. 以修改为前提去组织,将修改的影响控制到最小; |
对象和数据结构
| 数据抽象,getter/setter并不是简单的函数隔离,而是这关乎抽象,隔离具体实现 |
| 对象就是隐藏数据,暴露操作 |
| 对象不应该利用存取其暴露其内部的数据结构 |
| 用DTO/Bean来实现数据的跨模块传输 |
编码
对象与数据结构
| 数据抽象,getter/setter并不是简单的函数隔离,而是这关乎抽象,隔离具体实现 |
| 对象就是隐藏数据,暴露操作 |
| 对象不应该利用存取其暴露其内部的数据结构 |
| 用DTO/Bean来实现数据的跨模块传输 |
错误处理
错误处理很重要,但如果它搞乱了代码逻辑,就是错误的做法。整洁的代码是可读的,同时也要强固,尽量减少各种异常的出现。
| 使用异常而非返回错误码 | 遇到错误时,最好抛出一个异常,这样调用者的代码就不会被各种处理错误码的逻辑搞乱 |
| 尽量减小try..cactch的作用范围 | 这样既有助于定位问题,同时还可以让代码逻辑更加清晰 |
| 使用不可控异常 | 1. 破坏了开闭原则 2. 如果是编写类库checked exception可能有用,但对于一般应用开发成本高于收益 |
| 给出异常发生的环境说明 | 给出抛出异常时明确的操作和原因 |
| 对那些会抛出很多异常的类库进行打包,屏蔽掉复杂的异常处理 | |
| 别返回null值 | 1. 返回null不仅是给自己找麻烦,还是给调用者找麻烦 2. 可以通过对会返回null的方法进行打包,屏蔽null值的判断,并抛出异常; 3. 尽量避免给别人造成NullPointerException |
| 别传递null值 | 传递null值同样会引起NullPointerException,调用者和被调用这应该共同努力避免出现null值 |
单元测试
单元测试的目的有三个:
- 测试业务代码的每一个角落,保证他们能够正确的运行;
- 给使用者快速了解代码逻辑的途径;
- 在对业务代码进行修改时能够对其进行快速测试,保证不出现新的bug;
单元测试代码也要和业务代码一样保持整洁,遵循 构造-操作-检测(断言) 的三步构建测试代码,测试代码要遵循以下几个原则:
| 快速 | 保证执行速度足够的快 |
| 独立 | 每一个单元测试都应该能够独立运行,不应该依赖其他单元测试的结果 |
| 可重复 | 能够在不同的环境、不同的时间重复执行 |
| 自足验证 | 最终输出应该是布尔值,能够进行正确性断言 |
| 及时 | 测试代码应该随着业务代码的开发及时编写, |















 489
489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











