






1 背景
团队:Waymo
时间:2023.9
代码:
简介:把【自动驾驶中多agents的轨迹序列预测】比作【大语言模型中多user的语言预测】,采用交互+自回归的方式做轨迹生成,能够更好地建模交互,且避免模态坍缩,在数据集达到了SOTA。
2 存在的问题与本模型的优势
2.1 问题
- 边缘预测不准确。多agent联合预测分解为各个agent的单独预测,虽然更简单,但是对于预测可以,对于规划任务来说不足,maginal predictions are insufficient as inputs to a planning system。
- 多模态边缘预测 marginal trajectory generation +交互打分 interactive scoring。并没有显式explicitly地建模时间上的依赖特征temporal dependencies within trajectories,所以这样的轨迹是似是而非的spurious
本模型优势
- 轨迹滚动预测rollouts,提升预测性能。Joint models that do not preserve temporal dependencies may have a limited ability to predict realistic agent reactions. minADE下降1.2%,mAP提高3.7%。
- 轨迹分布有限,降低预测难度。之前是在连续空间预测,本方案将xy离散化,在有限的离散空间中做预测(其实是分类),难度更低。
- 轨迹输出分布更加均匀:原本xy预测认为空间过大,有的xy很大(t大速度快的时候),有的xy很小(t小速度慢的时候),导致xy分布差异大,分布不均匀。本方案回归dx dy,和t无关,分布更均匀。
- loss设计简单。之前是算回归损失,现在是算分类损失。(其实我觉得都不麻烦)
- 多agent轨迹联合预测,轨迹更贴近真实情况more realistic
- 多模态特性更好。之前多模态要通过多queries来查询,本方案通过分类概率的随机采样即可实现 multimodality emerges solely as a characteristic of sampling。
3 具体方案
Encoder采用了之前的论文Wayformer的Encoder。本文具体关注解码器Decoder。
轨迹转运动序列
该文章的一个主要创新点是把每一个时刻的位移认为是vocabulary运动序列的一个运动token(motion token)。由此把位移回归问题变成了运动序列的token分类问题。这个过程会牺牲一些精度,但是会带来更小的预测空间,降低预测难度。
- 先做轨迹差分,落在-18到18m的范围内,然后分别对x和y划分成128个区间,那么xy都在0-127int的范围内。
- 但是考虑到上一个时刻是127,下一个时刻不可能是0,所以只针对上一时刻附近的做量化,获得增量级别的xy
- 每个方向各13个,得到动作空间为169的verlet-wrapped action space。

该模型并不是直接输出轨迹,而是输出分类结果,从而滚动重建轨迹。
agent centric
为了预测每个agent的轨迹,把每个agent当作一次ego,把feature都转到该agent坐标系下。比较取巧的一点是,为了能够保证训练和推理速度,每个agent(包含ego在内)并到batch维度下进行 collapsing the ego agents into the batch dimension allows parallelization during training and inference.
轨迹去重和聚类
kmeans聚类成6条。
loss
采用teacher-force的方法,每个回归出来的点都是加在上一时刻的真值上,得到这个时刻的输出,模型收敛更快。
comment:可以前一段训练用teacher-force,后一段直接用自回归的累积结果。
4 verlet积分
verlet积分是一种数值积分方法,想解决的是计算物体运动中欧拉法能量不稳定/计算更复杂的问题。
欧拉法计算位移如下:
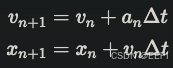
这带来2个问题:
- 能量不守恒。用这个公式计算弹簧振动,振幅会逐渐增大或减小。
- 需要计算中间变量v,需要额外存储空间。
因此采用verlet积分:
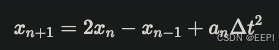
应用:在【我的世界】中,方块掉落的轨迹更加真实。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









