






文章目录
前言
hashmap底层原理及扩容机制一直是java核心知识之一。其源码相当复杂程度精妙复杂,,因而hashmap源码也被称做最值得学习的源码。
一、hashmap的底层原理和扩容机制是什么
hashmap由数组链表加红黑树组成,每添加一个键值对,计算键的hash值,将获取到的值高16位和低16位进行异或处理,得到的值与数组长度减一进行按位与运算,获取到的最终值即该元素所在数组位置,若该位置有元素,即存在hash冲突,采用链式存储法存储该元素,当链表长度超过8时,链表转为红黑树以增加其查询效率。当hashmap当前所占数组数量超过hashmap容量乘以装载因子时,且其新加的元素出现了hash冲突,触发扩容机制。扩容长度为两倍扩容。将每个键的hash值与新的数组长度减一进行按位与运算,所得的值如果与原位值一样,则放于原位置,反之则放于原位置加旧容量。后续会详细说明每一步的作用。下面进行hashmap源码解读。
二、源码解析
1.新建hashmap调用put方法

2.点击进入put方法

onlyifAbsent表示是否覆盖,默认是覆盖,evict是为linkedhashmap服务,这里用不到。hash(key)即计算key的hash值。
`
3.点击进入hash(key)方法

如果key是空则返回零,非空则调用object类中hashcode方法,与自身逻辑右移16位(高位补零)进行异或运算。这里的形参key是object型,采用父类应用指向子类对象,即多态方式创建对象。如果子类重写过hashcode方法,则会调用子类覆盖重写后的方法。
前三部主要在干一件事,调用key的hashcode,高低位异或运算后得到最终hash值。
4.点击进入核心源码putval方法
4.1hashmap初始化
putval方法包含了hashmap底层原理和扩容机制。该方法的源码很长,这里逐个代码块进行分析

先看局部变量tab,[]对应hashmap底层组件之一数组,Node<K,V>有个next属性指向下一个Node<K,V>,故Node<K,V>对应hashmap底层组件之一的链表。第一个if语句表示第一次调用put方法时,对hashmap进行初始化。
第二个if语句表示将key的hash值和tab数组长度减1进行按位与运算。得到的最终值即对应在tab数组上的位置,如果这个位置没元素,则在该位置放入node节点,node存储的即传入的键值对。
4.2处理hashmap冲突
从源码第631行else开始接下来均为处理hashmap冲突
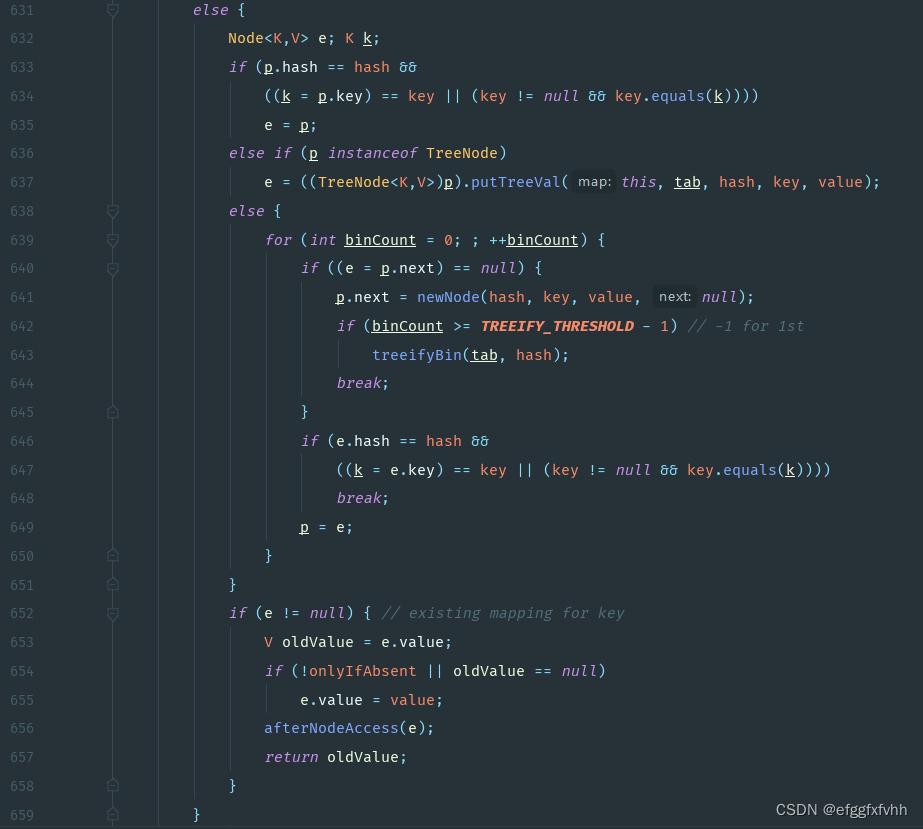
第633行到第635行表示当这个数组位已经存在元素,且新加的元素key hashcode和equals方法完全一样,直接替代。
第636到637行表示当新加入的元素是红黑树的一个实例,则将该节点挂载在该红黑树下。
第638行表示当挂载在数组该位置下的是个链表的时候,进行如下处理。
640到644行表示,如果链表中的每个元素的键都与新加的元素的键不同,则将新加的元素挂载在链表末端,如果链表长度大于等于7,将链表转换为红黑树。
646到648行表示如果链表下的某个元素的键与新加元素的键完全一样,跳出循环。
652到655行触发条件是程序通过第648行跳出循环,表示key值重复,则新加的value值取代原key值对应的value值。
660到第662行表示触发扩容。
三、 hashmap问题详解
问题一.为什么要对hashcode方法获得的值进行异或处理。
用异或处理是为了保证在length较小的时候,高位也能参与hash值的计算,用异或hash值中有任何一位改变得到的值就会改变。同时,调用hashcode方法所获得的32位数字不具备数学意义上的随机性,高16位低16位的异或处理后,最终的16位数字每位0或1的概率都是百分之50。
问题二.为什么落于数组的位置,取的的是异或处理获得的值和数组长度-1进行按位与运算,且数组长度必须是二的幂次方。
数组长度为2的幂并且按位与运算是为了保证数据均匀分布在数组上,因为二进制中2的幂次方减一所有位数均为1,按位与运算可保证获得的值位于0到数组长度减一之间。且得到的二进制值每一位0或1的概率都是百分之50,固数据落在每个格子的概率都是一样的。若容量不是2的幂数组中某个格会出现一直为空的情况,即便设置的不是2的倍数,java也会将容量更改为距离最近的2的幂。若不采用异或运算,会导致最终值超出数组界线。
问题三.JDK1.8对hashmap扩容做了什么优化
jdk1.8将hashcode方法高低16位异或运算所获取的值与新的数组长度减一进行按照位与运算,新的数组与原数组在二进制中变化是新数组比原数组多了个1,所以按位与运算后只有首位有可能发生变化,且首位发生变化的概率是百分之五十,因为原hash值是异或运算得出,每一位是零或一的概率是百分之五十),如果与原位置一样,则放在原位置,如果与原位置不一样,再放于原位置加旧容量。这样做的目的是让元素均匀分布在新数组中,因为首位变化率是百分之50,固原位置数据是否不变的概率是百分之50,而原位置加旧容量处是否有数据的概率也是百分之50。
问题四.为什么两倍扩容
是为了保证数组长度是二的幂次方。至于为什么是二的幂次方,已在问题二中详细解答。
问题五.为什么默认装载因子是0.75
装载因子太大链表过多查询效率低,太小数组利用率低,数据分散。0.75符合数学泊松分布。
四、总结
综上所述,hashmap计算元素所处位置的方式,以及扩容原理,其本质就是保证数据均匀的落在数组上。在巧妙的异或、按位与运算及扩容机制,最终尽可能得保证了数据落在数组的每个位置的概率是一样的。















 516
516











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









