







最近在看一本名为的书。由于我所看过的计算机理论方面的书较少,加上自己大学期间一直也不用功,所以对于计算机的工作原理以及程序的工作方式我始终只知甚少,印象也十分模糊。
不过,应该说我碰到了一本好书。至少,通过昨晚对浮点数一章的阅读(呃...我的确之前对浮点数从没弄明白过),我终于了解了C语言中为什么32位int型数据强制转换到float型会出现精度不能完全保留的现象:
首先来看看我们可爱的int型变量吧,在一台典型的32位机器上一个有符号的int型的取值范围为-2147483648 ~ 2147483647(-2^31 ~ (2^31-1))(注1)。也就是说,在一个4字节(32位2进制),除去首位用于符号位表示正负外,其余的31位都是数字的有效位。
下面再来看看“万恶的”float型变量:根据IEEE的浮点标准,一个浮点数应该用下述形式来表示:
V=(-1)^s * M * 2^E (公式1)
在C语言中,32位的float型变量有着这样的规定:首位表示符号位s,接下来的8位(指数域)用于表示2的指数E,剩余的23位(小数域)表示M(取值范围为[1,2)或[0,1))。除了上述规定以外,根据指数域的二进制表示情况不同,被编码的float型数字又可以分成三种情况——
1、规格化值。当指数域的8个二进制数字既非全零又非全1时,float数值就是这种情况。设指数域的八位二进制所表示的十进制数为e, 则公式1中的E就是 E = e - (2^7 - 1) (公式2);
而且此时,将小数域所表示的二进制假设为(f22)(f21)...(f1)(f0) (注2) ,则该小数域所表示的值即为f = 0.(f22)(f21)...(f1)(f0).于是M = 1 + f
2. 非规格化值。当指数域的8个二进制数字为全0时,float数值就为这种情况。这时指数域所表示的十进制数为0,规定指数值为 E = 1 - (2^7 - 1),也就是E为定值-126;此时小数域的值仍表示f = 0.(f22)(f21)...(f1)(f0),但是M的值却变成M = f。
3. 特殊值。当指数域的8个二进制数字为全1时即为这种情况。当小数域为全零时,该float值根据符号位的不同表示正无穷或者负无穷;当小数域为非全零时,该float值为NaN(Not a Number)。
以上,只是在C语言中对int和float的规约。具体在代码中执行强制类型转化究竟会发生什么?从下面两句很简单的语句开始:
float b = (float)a;
那么在内存中a和b究竟存放的是什么值呢?
将a展开为二进制,其值为0000 0000 0011 0101 0100 0011 0010 0001,其十六进制即为0x00354321。 因为要转化为float型,所以首先要对上述二进制的表示形式改变为 M * 2^E 的形式.由于该数明显大于1,所以按照IEEE的标准,其浮点形势必然为规格化值。因此 ,转化后的形式为
a = 1.101010100001100100001 * 2^21
根据 规格化值的定义,M = 1 + f. 所以f = 0.101010100001100100001.因为float型变量的小数域一共23位。所以b的最后23位可以得出,其值为10101010000110010000100
下面再演绎指数域的值:因为a的指数表示法中,指数E = 21。根据公式2,e = E + (2^7 -1) = 148.所以可以得出b的指数域的二进制表示为:10010100。在加上原数为正,所以符号位s=0。
所以,可以得出b的二进制表示为0 10010100 10101010000110010000100。转化为十六位进制则是0x4A550C84。换句话说,它存储在内存中的值是与a是完全不同的。但是其间还是有关联性的——a的首位为1的数值位后的二进制表示是与b的小数域完全相同的。
很快,问题就出现了。int型的有效位数是31,而float型小数域的有效位只有23位,也就是说如果上面的a的二进制的有效位超过了24位,那么float型的小数域的精度就不够了。因此必须进行舍入。比如:如果上面的a的二进制为0000 0001 1111 0101 0100 0011 0010 0001。这时b的小数域必须有24位才够,但是,这显然是不现实的,因此必须舍入到23位,舍入的原则是:所得结果的最低有效位为0。因此这个a在转换到float时,其精度就会丢失,因为该float的最后23位变成了11110101010000110010000——这显然是与原值不符的。
实际上,C语言中对于double型在32位机器上的小数域有52位,对于int型的31位有效位是绰绰有余了。这就是为什么大部分C语言教材上鼓励读者在执行强制类型转换时将int型转换成double。同时,这可能也是为什么int型能够直接隐式转换到double型的缘故。
注1:x ^ y表示 x的y次方
注2:(fn)取0或1
http://seapalace.blog.sohu.com/1586858.html
对文中关于e的描述不是很理解,如上文标红色部分。我按照上述描述可以做到整数2,3的手动转换到浮点数,就是不能对1做手动转换。后来又找到了维基上的描述:
http://zh.wikipedia.org/wiki/IEEE_754
贴出部分:
整体呈现[编辑]

二进制浮点数是以符号数值表示法的格式存储——最高有效位被指定为符号位(sign bit);“指数部份”,即次高有效的e个比特,存储指数部分;最后剩下的f个低有效位的比特,存储“尾数”(significand)的小数部份(在非规约形式下整数部份默认为0,其他情况下一律默认为1)。
指数偏移值[编辑]
指数偏移值(exponent bias),是指浮点数表示法中的指数域的编码值为指数的实际值加上某个固定的值,IEEE 754标准规定该固定值为2e-1 - 1[2],其中的e为存储指数的比特的长度。
以单精度浮点数为例,它的指数域是8个比特,固定偏移值是28-1 - 1 = 128−1 = 127.单精度浮点数的指数部分实际取值是从128到-127。例如指数实际值为1710,在单精度浮点数中的指数域编码值为14410,即14410 = 1710 + 12710.
采用指数的实际值加上固定的偏移值的办法表示浮点数的指数,好处是可以用长度为e个比特的无符号整数来表示所有的指数取值,这使得两个浮点数的指数大小的比较更为容易。
规约形式的浮点数[编辑]
如果浮点数中指数部分的编码值在0 < exponent < 2e-1之间,且尾数部分最高有效位(即整数字)是1,那么这个浮点数将被称为规约形式的浮点数。
非规约形式的浮点数[编辑]
如果浮点数的指数部分的编码值是0,尾数为非零,那么这个浮点数将被称为非规约形式的浮点数。IEEE 754标准规定:非规约形式的浮点数的指数偏移值比规约形式的浮点数的指数偏移值大1.例如,最小的规约形式的单精度浮点数的指数部分编码值为1,指数的实际值为-126;而非规约的单精度浮点数的指数域编码值为0,对应的指数实际值也是-126而不是-127。实际上非规约形式的浮点数仍然是有效可以使用的,只是它们的绝对值已经小于所有的规约浮点数的绝对值;即所有的非规约浮点数比规约浮点数更接近0。规约浮点数的尾数大于等于1且小于2,而非规约浮点数的尾数小于1且大于0.
IEEE 754-1985标准采用非规约浮点数,源于70年代末IEEE浮点数标准化专业技术委员会酝酿浮点数二进制标准时,Intel公司对渐进式下溢出(gradual underflow)的力荐。当时十分流行的DEC VAX机的浮点数表示采用了突然式下溢出(abrupt underflow)。如果没有渐进式下溢出,那么0与绝对值最小的浮点数之间的距离(gap)将大于相邻的小浮点数之间的距离。例如单精度浮点数的绝对值最小的规约浮点数是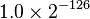 ,它与绝对值次小的规约浮点数之间的距离为
,它与绝对值次小的规约浮点数之间的距离为 。如果不采用渐进式下溢出,那么绝对值最小的规约浮点数与0的距离是相邻的小浮点数之间距离的
。如果不采用渐进式下溢出,那么绝对值最小的规约浮点数与0的距离是相邻的小浮点数之间距离的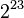 倍!可以说是非常突然的下溢出到0。这种情况的一种糟糕后果是:两个不等的小浮点数X与Y相减,结果将是0.训练有素的数值分析人员可能会适应这种限制情况,但对于普通的程序员就很容易陷入错误了。采用了渐进式下溢出后将不会出现这种情况。例如对于单精度浮点数,指数部分实际最小值是(-126),对应的尾数部分从
倍!可以说是非常突然的下溢出到0。这种情况的一种糟糕后果是:两个不等的小浮点数X与Y相减,结果将是0.训练有素的数值分析人员可能会适应这种限制情况,但对于普通的程序员就很容易陷入错误了。采用了渐进式下溢出后将不会出现这种情况。例如对于单精度浮点数,指数部分实际最小值是(-126),对应的尾数部分从 ,
, 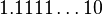 一直到
一直到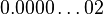 ,
,  ,相邻两小浮点数之间的距离(gap)都是;而与0最近的浮点数(即最小的非规约数)也是。
,相邻两小浮点数之间的距离(gap)都是;而与0最近的浮点数(即最小的非规约数)也是。
特殊值[编辑]
这里有三个特殊值需要指出:
- 如果指数是0并且尾数的小数部分是0,这个数±0(和符号位相关)
- 如果指数 =
 并且尾数的小数部分是0,这个数是±∞(同样和符号位相关)
并且尾数的小数部分是0,这个数是±∞(同样和符号位相关) - 如果指数 = 并且尾数的小数部分非0,这个数表示为不是一个数(NaN)。
以上规则,总结如下:
| 形式 | 指数 | 小数部分 |
|---|---|---|
| 零 | 0 | 0 |
| 非规约形式 | 0 | 非0 |
| 规约形式 |  到 到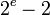 | 任意 |
| 无穷 | 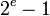 | 0 |
| NaN | | 非零 |
32位单精度[编辑]
单精度二进制小数,使用32个比特存储。
| 1 | 8 | 23 位长 |
| S | Exp | Fraction |
| 31 | 30至23 偏正值(实际的指数大小+127) | 22至0 位编号(从右边开始为0) |
S为符号位,Exp为指数字,Fraction为有效数字。 指数部分即使用所谓的偏正值形式表示,偏正值为实际的指数大小与一个固定值(32位的情况是127)的和。采用这种方式表示的目的是简化比较。因为,指数的值可能为正也可能为负,如果采用补码表示的话,全体符号位S和Exp自身的符号位将导致不能简单的进行大小比较。正因为如此,指数部分通常采用一个无符号的正数值存储。单精度的指数部分是−126~+127加上偏移值127,指数值的大小从1~254(0和255是特殊值)。浮点小数计算时,指数值减去偏正值将是实际的指数大小。
单精度浮点数各种极值情况:
| 类别 | 正负号 | 实际指数 | 有偏移指数 | 指数域 | 尾数域 | 数值 |
|---|---|---|---|---|---|---|
| 零 | 0 | -127 | 0 | 0000 0000 | 000 0000 0000 0000 0000 0000 | 0.0 |
| 负零 | 1 | -127 | 0 | 0000 0000 | 000 0000 0000 0000 0000 0000 | −0.0 |
| 1 | 0 | 0 | 127 | 0111 1111 | 000 0000 0000 0000 0000 0000 | 1.0 |
| -1 | 1 | 0 | 127 | 0111 1111 | 000 0000 0000 0000 0000 0000 | −1.0 |
| 最小的非规约数 | * | -126 | 0 | 0000 0000 | 000 0000 0000 0000 0000 0001 | ±2−23 × 2−126 = ±2−149 ≈ ±1.4×10-45 |
| 中间大小的非规约数 | * | -126 | 0 | 0000 0000 | 100 0000 0000 0000 0000 0000 | ±2−1 × 2−126 = ±2−127 ≈ ±5.88×10-39 |
| 最大的非规约数 | * | -126 | 0 | 0000 0000 | 111 1111 1111 1111 1111 1111 | ±(1−2−23) × 2−126 ≈ ±1.18×10-38 |
| 最小的规约数 | * | -126 | 1 | 0000 0001 | 000 0000 0000 0000 0000 0000 | ±2−126 ≈ ±1.18×10-38 |
| 最大的规约数 | * | 127 | 254 | 1111 1110 | 111 1111 1111 1111 1111 1111 | ±(2−2−23) × 2127 ≈ ±3.4×1038 |
| 正无穷 | 0 | 128 | 255 | 1111 1111 | 000 0000 0000 0000 0000 0000 | +∞ |
| 负无穷 | 1 | 128 | 255 | 1111 1111 | 000 0000 0000 0000 0000 0000 | −∞ |
| NaN | * | 128 | 255 | 1111 1111 | non zero | NaN |
| * 符号位可以为0或1 . | ||||||
64位双精度[编辑]
《C++类型转换方式总结 》http://www.cnblogs.com/ider/archive/2011/08/05/cpp_cast_operator_part6.html
《C++标准转换运算符dynamic_cast》http://www.cnblogs.com/ider/archive/2011/08/01/2123298.html
《C++标准转换运算符static_cast 》http://www.cnblogs.com/ider/archive/2011/07/31/2122385.html
《C++标准转换运算符reinterpret_cast》http://www.cnblogs.com/ider/archive/2011/07/30/2121953.html















 5543
5543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









