







1.Learning a Deep Convolutional Network for Image Super-Resolution(SRCNN 2014 ECCV )
1、总结
第一篇用深度学习做超分的文章,就是用深度学习来表示传统方式。结构比较简单。
源码地址:
SRCNN CODE
2、思路
先用 bicubic interpolation把图像scale到目标大小,然后通过提特征,非线性映射,然后恢复成图像。
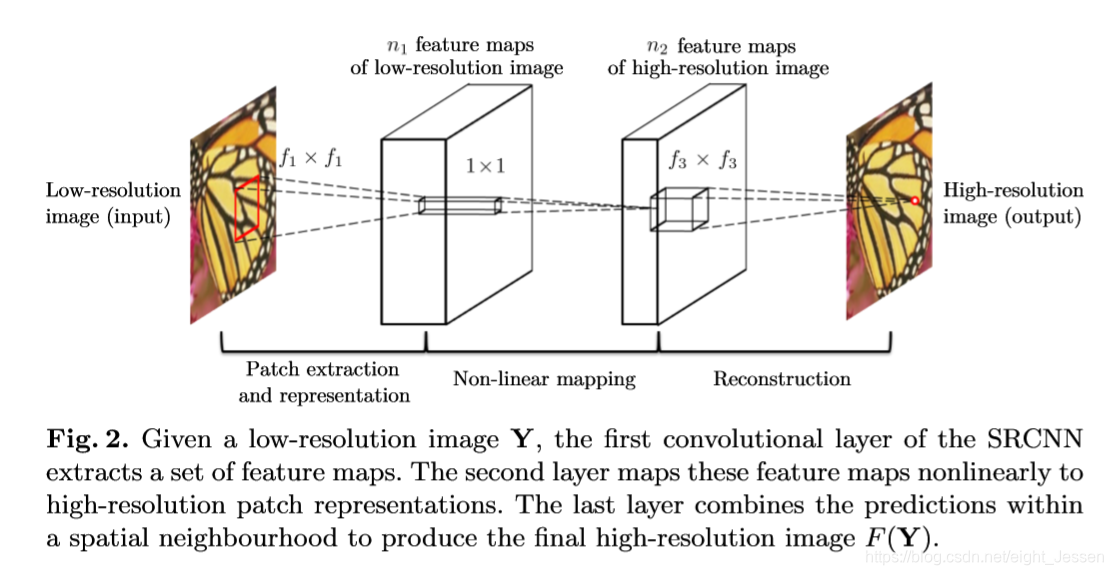
网络结构代码表示:
import tensorflow as tf
from tensorflow.contrib import slim
class SRCNN:
def __init__(self):
pass
def model(self, inputs, padding='VALID', name='srcnn'):
with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
inputs = inputs / 255.0
net = slim.conv2d(inputs, 64, [9, 9], padding=padding, scope='conv1_1')
net = slim.conv2d(net, 32, [1, 1], padding=padding, scope='conv2_1')
net = slim.conv2d(net, 1, [5, 5], padding=padding, activation_fn=None, scope='conv3_1')
return net
def __call__(self, inputs, padding='VALID', name='srcnn'):
return self.model(inputs, padding, name) 2.Accelerating the super-resolution convolutional neural network(2016 ECCV)
文章主页
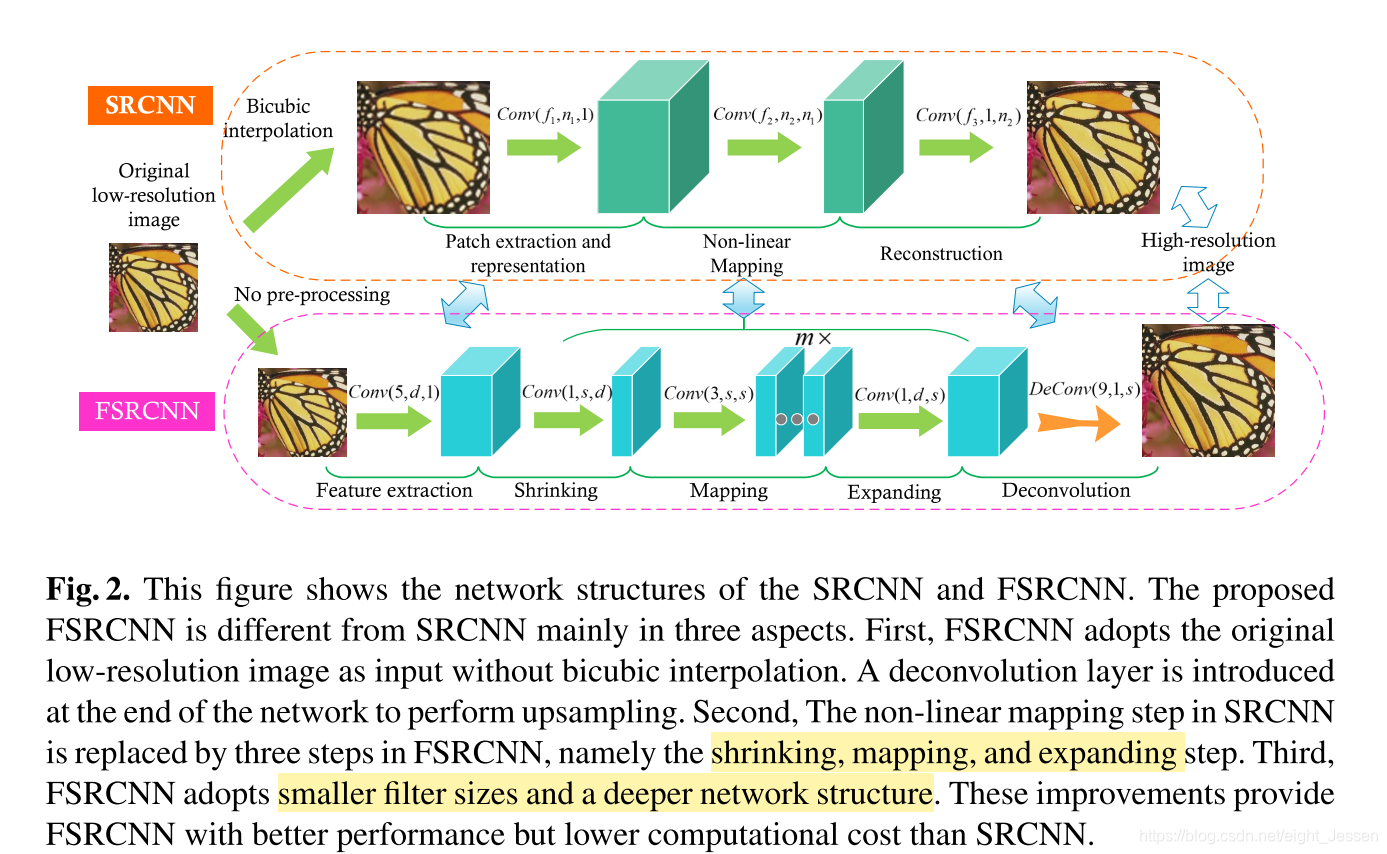
相比SRCNN,FSRCNN
- 网络参数量减少了,效果也没有下降。
- 不需要预处理做图片上采样,只需要做网络最后一层deconv的改动,网络比较好迁移训练和测试。
思路
网络分为了
feature exraction—shrinking—mapping—expanding—deconvolution
1.Feature Extraction
第一步是提取特征。这一步由于没有像SRCNN先做上采样,所以 5 ∗ 5 5*5 5∗5的滤波器的感受野就相当于SRCNN 9 ∗ 9 9*9 9∗9的滤波器感受野。这一层可以表示为 C o n v ( 5 , d , 1 ) Conv(5,d,1) Conv(5,d,1)
2.Shrinking
这一步降低了计算消耗。用了 1 ∗ 1 1*1 1∗1的filter,这一层可以表示为 C o n v ( 1 , s , d ) , s < < d Conv(1,s,d), s<<d Conv(1,s,d),s<<d,对LR的特征实现了降维。
3. Non-linear mapping
这一层最重要的是深度(depth, the number of layers)和宽度(width, the number of filters in a layer)。这一部分可以表示为 m ⋅ C o n v ( 3 , s , s ) m \cdot Conv(3, s, s) m⋅Conv(3,s,s)
4.Expanding
这一层就像是shrinking的逆操作。直接从前面的LR特征做超分结果是不理想的,所以多加了这一层去扩展HR层的维度。这一层是 C o n v ( 1 , d , s ) Conv(1,d,s) Conv(1,d,s)。
5.Deconvolution
D
e
C
o
n
v
(
9
,
1
,
d
)
DeConv(9,1,d)
DeConv(9,1,d)
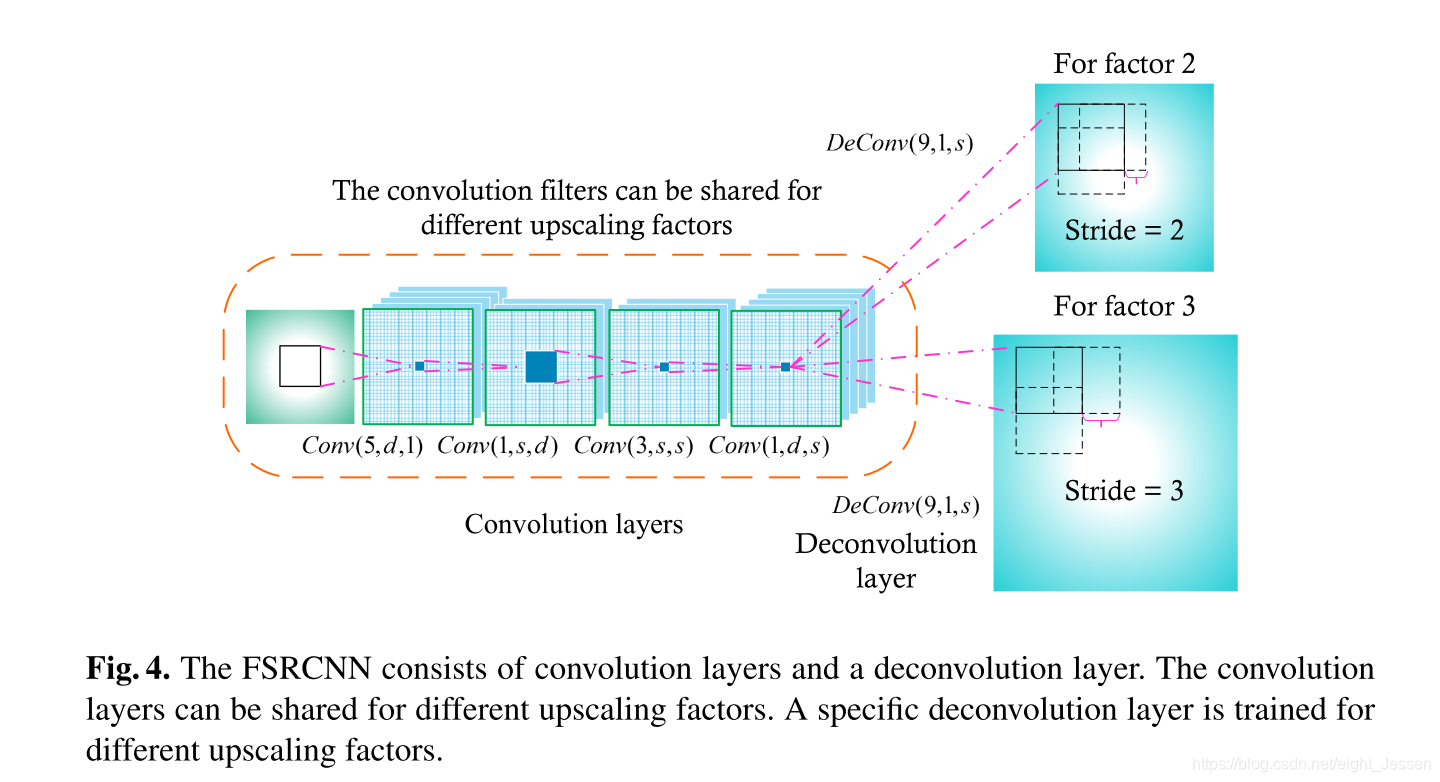
6.PReLU
Parametric Rectified Linear Unit
ReLU和PReLU可以表示为:
f
(
x
i
)
=
m
a
x
(
x
i
,
0
)
+
a
i
m
i
n
(
0
,
x
i
)
f(x_i) = max(x_i,0) + a_imin(0, x_i)
f(xi)=max(xi,0)+aimin(0,xi)
如果
a
i
=
0
a_i = 0
ai=0就是ReLU
7.Overall structure
C
o
n
v
(
5
,
d
,
1
)
−
P
R
e
L
U
−
C
o
n
v
(
1
,
s
,
d
)
−
P
R
e
L
U
−
m
∗
C
o
n
v
(
3
,
s
,
s
)
−
P
R
e
L
U
−
C
o
n
v
(
1
,
d
,
s
)
−
P
R
e
L
U
−
D
e
C
o
n
v
(
9
,
1
,
d
)
Conv(5, d, 1) - PReLU - Conv(1, s, d) - PReLU - m*Conv(3, s, s) - PReLU -Conv(1, d, s) - PReLU - DeConv(9, 1, d)
Conv(5,d,1)−PReLU−Conv(1,s,d)−PReLU−m∗Conv(3,s,s)−PReLU−Conv(1,d,s)−PReLU−DeConv(9,1,d)
三个敏感变量
s
,
d
,
m
s, d, m
s,d,m
F
S
R
C
N
N
(
d
,
s
,
m
)
FSRCNN(d, s, m)
FSRCNN(d,s,m)
计算复杂度(不计PReLU)
O
(
25
d
+
s
d
+
9
m
s
2
+
d
s
+
81
d
)
S
L
R
=
O
(
9
m
s
2
+
2
s
d
+
106
d
)
S
L
R
O{(25d + sd + 9ms^2 + ds + 81d)S_{LR}} = O{(9ms^2 + 2sd + 106d)S_{LR}}
O(25d+sd+9ms2+ds+81d)SLR=O(9ms2+2sd+106d)SLR
8.Cost function
MSE
m
i
n
θ
1
n
∑
i
=
1
n
∣
∣
F
(
Y
s
i
;
θ
−
X
i
)
∣
∣
2
2
min_\theta \frac{1}{n}\sum_{i=1}^n||F(Y_s^i;\theta - X_i)||_2^2
minθn1i=1∑n∣∣F(Ysi;θ−Xi)∣∣22
Y
s
i
Y_s^i
Ysi和
X
i
X^i
Xi分别是第i个LR和HR图片对,
F
(
Y
s
i
;
θ
)
F(Y_s^i;\theta)
F(Ysi;θ)是网络的输出
3.Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network(ESPCN CVPR2016)
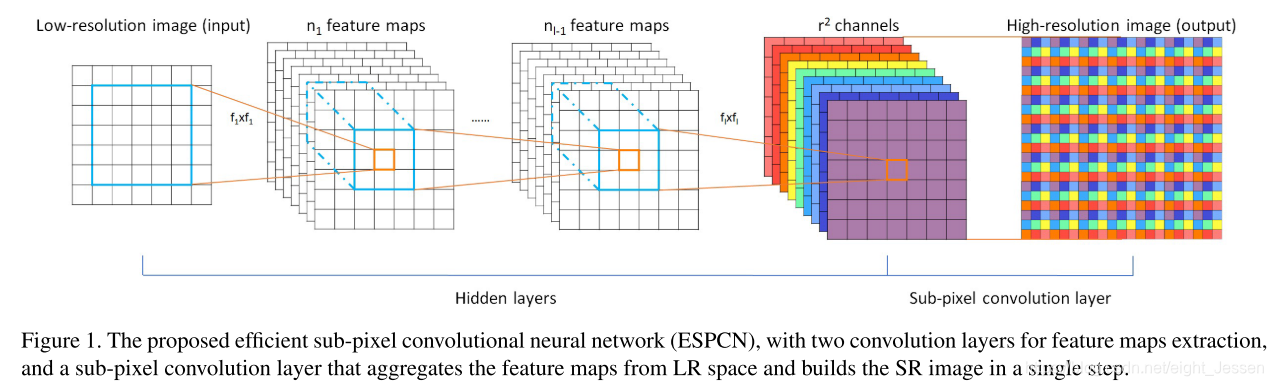
Method
1.数据处理
先对原来的图像做高斯模糊,模拟相机的点扩散,然后做下采样。
先在LR图片上过了
l
l
l层卷积,然后用一个 sub-pixel convolution layer上采样LR feature maps产生
I
S
R
I^{SR}
ISR
比如对于一个L层的网络,
L
−
1
L-1
L−1层可以描述为:
f
1
(
I
L
R
;
W
1
,
b
1
)
=
ϕ
(
W
1
∗
I
L
R
+
b
1
)
f^1(I^{LR}; W_1, b_1) = \phi(W_1 * I^{LR} + b_1)
f1(ILR;W1,b1)=ϕ(W1∗ILR+b1)
f
l
(
I
L
R
;
W
1
:
l
,
b
1
,
l
)
=
ϕ
(
W
l
∗
f
l
−
1
(
I
L
R
+
b
l
)
)
f^l(I^{LR}; W_{1:l}, b_{1,l}) = \phi(W_l * f^{l-1}(I^{LR} + b_l))
fl(ILR;W1:l,b1,l)=ϕ(Wl∗fl−1(ILR+bl))
W
l
,
b
l
,
l
∈
(
1
,
L
−
1
)
W_l, b_l, l \in (1, L-1)
Wl,bl,l∈(1,L−1),
W
l
W_l
Wl是
2
D
2D
2D卷积层,大小为
n
l
−
1
∗
n
l
∗
k
l
∗
k
l
n_{l-1}*n_l*k_l*k_l
nl−1∗nl∗kl∗kl,
n
l
n_l
nl是
l
l
l层的特征数,
ϕ
\phi
ϕ激活函数,最后一层
f
L
f^{L}
fL将LR特征映射到HR图片。
2.Deconvolution layer
使用神经网络unscale的方法之一
3.Efficient sub-pixel convolution layer
I
S
R
=
f
L
(
I
L
R
)
=
P
S
(
W
L
∗
f
L
−
1
(
I
L
R
)
+
b
L
)
I^{SR} = f^L(I^{LR}) = PS(W_L * f^{L-1}(I^{LR})+b_L)
ISR=fL(ILR)=PS(WL∗fL−1(ILR)+bL)
P
S
PS
PS这个操作就是,上一步生成的特征层为
H
∗
W
∗
C
∗
r
2
H*W*C*r^2
H∗W∗C∗r2,把他们重新排列成
r
H
∗
r
W
∗
C
rH*rW*C
rH∗rW∗C,对应于上面的第四第五张图就是这个操作
P
S
(
T
)
x
,
y
,
c
=
T
⌊
x
/
r
⌋
,
⌊
y
/
r
⌋
,
C
⋅
r
⋅
m
o
d
(
y
,
r
)
+
C
⋅
m
o
d
(
x
,
r
)
+
c
PS(T)_{x,y,c} = T_{\lfloor x/r \rfloor, \lfloor y/r\rfloor, C\cdot r \cdot mod(y,r) + C \cdot mod(x,r) + c}
PS(T)x,y,c=T⌊x/r⌋,⌊y/r⌋,C⋅r⋅mod(y,r)+C⋅mod(x,r)+c
卷积操作
W
L
W_L
WL大小为
n
L
−
1
∗
r
2
C
∗
k
L
∗
k
L
n_{L-1} * r^2C * k_L * k_L
nL−1∗r2C∗kL∗kL,当
K
L
=
k
s
r
K_L = \frac{k_s}{r}
KL=rks还有
m
o
d
(
k
s
,
r
)
=
0
mod(k_s,r)=0
mod(ks,r)=0时,相当于在LP空间上的 sub-pixel convolution卷积
4.Loss
pixel-wise mean squared error(MSE)
l
(
W
1
:
L
,
B
1
:
L
)
=
1
r
2
H
W
∑
x
=
1
r
H
∑
x
=
1
r
W
(
I
x
,
y
H
R
−
f
x
,
y
L
(
I
L
R
)
)
2
l(W_{1:L}, B_{1:L}) = \frac {1}{r^2HW}\sum_{x = 1}^{rH}\sum_{x=1}^{rW}(I_{x,y}^{HR} - f_{x,y}^L(I^LR))^2
l(W1:L,B1:L)=r2HW1x=1∑rHx=1∑rW(Ix,yHR−fx,yL(ILR))2
4.Accurate Image Super-Resolution Using Very Deep Convolutional Networks(VDSR CVPR2016)
4.1、总结
这篇文章提出了一个very deep网络结构,通过在深层网络结构中多次级联小滤波器,有效利用大图像区域上的上下文信息。还有通过之学习残差加快训练。
作者提出了SRCNN的几个缺点:
- 只依赖与图像小区域的上下文信息
- 训练收敛太慢
- 网络只能实现 single scale
作者的创新点在: - 利用大图像区域的上下文信息
- 只依靠残差学习,同时用大的学习率,梯度裁剪实现
- 解决single network multe-scale SR problem
4.2 Method
4.2.1 网络结构

使用了d层,除了第一层和最后一层,都用了
3
∗
3
∗
6
3*3*6
3∗3∗6的滤波器,第一层作用于输入图片,最后一层输出图片。做了pad zeros处理。
4.2.2 训练
输入图像
x
x
x,输出
y
y
y,训练集
{
x
(
i
)
,
y
(
i
)
}
i
=
1
N
\{x^{(i)}, y^{(i)}\}_{i=1}^N
{x(i),y(i)}i=1N
y
^
=
f
(
x
)
\hat y = f(x)
y^=f(x),
y
^
\hat y
y^ estimate
训练目标,最小化MSE
1
2
∣
∣
y
−
f
(
x
)
∣
∣
2
\frac{1}{2}||y - f(x)||^2
21∣∣y−f(x)∣∣2
Residual-Learning
在SRCNN中,输入的信息从输入传到了输出,由于有许多权重层,这就变成了一种端到端的关系,需要非常长的内存。对于这个原因,消失/爆炸梯度问题是至关重要的。通过residual-learning解决这个问题。
残差图片可以表示为
r
=
y
−
x
r = y -x
r=y−x,很多为0或者很小,loss function就是
1
2
∣
∣
r
−
f
(
x
)
∣
∣
2
\frac{1}{2}||r - f(x)||^2
21∣∣r−f(x)∣∣2,
f
(
x
)
f(x)
f(x)是网络的预测结果。
网络的loss层有三个输入:residual estimate, network input (ILR image) and ground truth HR image。 Loss是重建图像和gt的欧氏距离。
High Learning Rates
使用比较高的学习率,同时用一个可调的梯度裁剪最大限度地提高速度,同时抑制爆炸梯度。
Adjustable Gradient Clipping,裁剪到
[
−
θ
,
θ
]
[-\theta, \theta]
[−θ,θ]。为了最大化收敛,梯度裁剪范围为
[
−
θ
γ
,
θ
γ
]
[-\frac {\theta}{\gamma},\frac {\theta}{\gamma}]
[−γθ,γθ],
γ
\gamma
γ是当前的学习率。
Multi-Scale
训练集有多种scale的图像
5.Deeply-Recursive Convolutional Network for Image Super-Resolution(DRCN CVPR 2016 Oral)
5.1 总结
网络越深,就能更大的感受野,但是网络越大,于是作者提出了deeply-recurisive convolution network(DRCN),不需要引入太多的网络参数。但是DRCN会比较男训练,于是通过recursive-supervision和skip-connection来解决。
- recursive-supervision 每一次递归出来的特征都会重建出HR图像,计算结果
- skip-connection from input to the reconstruction layer. LR图像和HR图像包含的信息是相同的,但是LR图像在网络的前向传播过程中,信息会丢失,所以加上skip-connection.
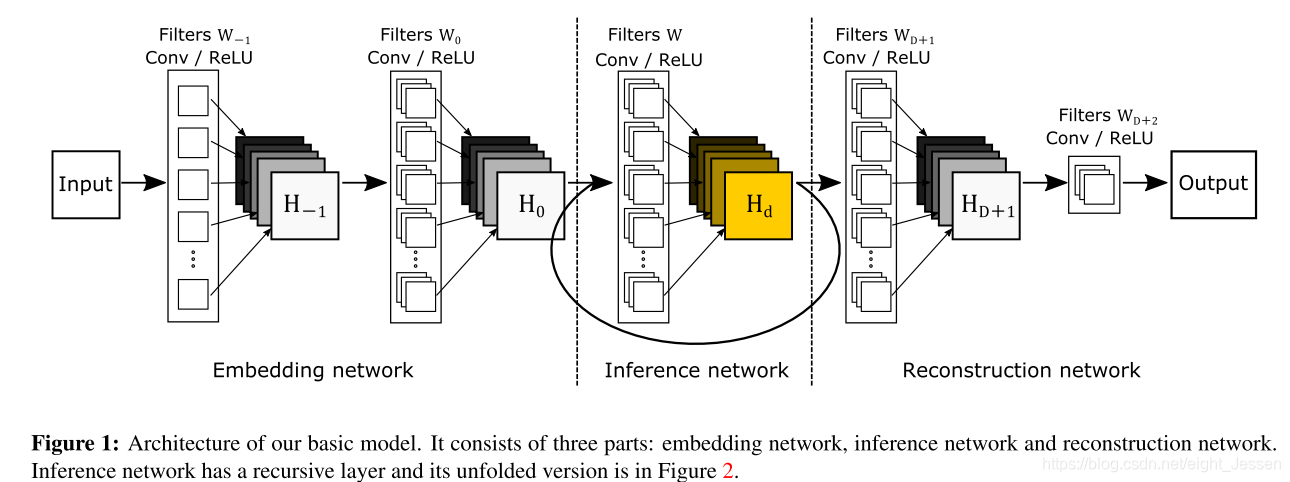

5.2 Method
网络的输入是插值图像
5.2.1 Basic Model
就是上面的两张图,网络分成了三个部分:embedding, inference and reconstruction
- embedding net 将输入图像表示成特征
- inference net 主要解决SR部分,不断地recursive,感受野变大
- reconstruction 将最后的特征转换到图片空间
每个子网络只有一层,每一层就像是MLP,使用 3 ∗ 3 3*3 3∗3的卷积核。对于embedding net, 使用 3 ∗ 3 3*3 3∗3卷积核是因为对于超分辨率,图像梯度的信息比强度更丰富。对于其他的两个网络,就是考虑了邻近的像素信息。
数学公式
网络的输入是插值后的图片
x
x
x,预测目标图片
y
y
y,网路输出是
y
^
=
f
(
x
)
\hat y = f(x)
y^=f(x),分别用
f
1
f_1
f1,
f
2
f_2
f2,
f
3
f_3
f3表示三个子网络,那么
f
(
x
)
=
f
3
(
f
2
(
f
1
(
x
)
)
)
f(x) = f_3(f_2(f_1(x)))
f(x)=f3(f2(f1(x)))。
对于embedding,
f
1
f_1
f1
假设
f
1
(
x
)
f_1(x)
f1(x)的输出是矩阵
H
0
H_0
H0,把隐藏层记成
H
−
1
H_{-1}
H−1,有
H
−
1
=
m
a
x
(
0
,
W
−
1
∗
x
+
b
−
1
)
H_{-1} = max(0, W_{-1}*x + b_{-1})
H−1=max(0,W−1∗x+b−1)
H
0
=
m
a
x
(
0
,
W
0
∗
H
−
1
+
b
0
)
H_0 = max(0, W_0*H_{-1}+b_0)
H0=max(0,W0∗H−1+b0)
f
1
(
x
)
=
H
0
f_1(x) = H_0
f1(x)=H0
对于inference,
f
2
f_2
f2
输入为
H
0
H_0
H0,输出为
H
D
H_D
HD。用相同的权重和偏差
W
W
W,
b
b
b做所有的操作。
H
d
=
g
(
H
d
−
1
)
=
m
a
x
(
0
,
W
∗
H
d
−
1
+
b
)
H_d = g(H_{d-1}) = max(0, W*H_{d - 1} + b)
Hd=g(Hd−1)=max(0,W∗Hd−1+b)
g
g
g是单一 一层的操作,
d
=
1
,
.
.
.
,
D
d = 1,...,D
d=1,...,D
f
2
=
(
g
∗
g
∗
.
.
.
∗
)
g
(
H
)
=
g
D
(
H
)
f_2 = (g * g * ... *)g(H) = g^D(H)
f2=(g∗g∗...∗)g(H)=gD(H)
∗
*
∗表示一个函数组合,
g
d
g^d
gd表示 g的
d
−
f
o
l
d
d-fold
d−fold积。
对于重建网络reconstructin,
f
3
f_3
f3
H
D
+
1
=
m
a
x
(
0
,
W
D
+
1
∗
H
D
+
b
D
+
1
)
H_{D+1} = max(0, W_{D+1} * H_D + b_{D+1})
HD+1=max(0,WD+1∗HD+bD+1)
y
^
=
m
a
x
(
0
,
W
D
+
2
∗
H
D
+
1
+
b
D
+
2
)
\hat y = max(0, W_{D+2} * H_{D+1} + b_{D+2})
y^=max(0,WD+2∗HD+1+bD+2)
f
3
(
H
)
=
y
^
f_3(H) = \hat y
f3(H)=y^
模型属性
梯度会出现问题
5.2 Advanced Model

Recuisive-Supervision
监督每一次的结果消除梯度爆炸或者消失的问题,inferece网络出来的每一次结果,reconstruction网络都会重建,最终有
D
D
D个结果。用所有的
D
D
D计算最终的结果。测试中求平均。
训练过程中监测信号直接从loss传到早期递归
思考:反向传播,梯度是怎么回传的
Skip-Connection
直接将输入引入到reconstruction层。这样reconstruction就有两个信息来源
Mathematical Formulation
y
^
d
=
f
3
(
x
,
g
(
d
)
(
f
1
(
x
)
)
)
\hat y_d = f_3(x , g^{(d)}(f_1(x)))
y^d=f3(x,g(d)(f1(x)))
d
=
1
,
2
,
.
.
.
,
D
d = 1, 2, ..., D
d=1,2,...,D
输出可以堪称是输入和特征
H
d
H_d
Hd的叠加,
f
3
(
x
,
H
d
)
=
x
+
f
3
(
H
d
)
f_3(x, H_d) = x + f_3(H_d)
f3(x,Hd)=x+f3(Hd)
最后的输出是所有中间预测的权值平均
y
^
=
∑
d
=
1
D
w
d
⋅
y
^
d
\hat y = \sum_{d = 1}^D w_d \cdot \hat y_d
y^=d=1∑Dwd⋅y^d
w
d
w_d
wd是递归期间从每个中间隐藏状态重建的预测的权重。
w
d
w_d
wd是怎么得到的
5.3 训练
目标函数
训练集
{
x
(
i
)
,
y
(
i
)
}
i
=
1
N
\{x^{(i)}, y^{(i)}\}_{i=1}^N
{x(i),y(i)}i=1N,目标准确预测
y
^
=
f
(
x
)
\hat y = f(x)
y^=f(x)
对于中间输出,有loss:
l
1
(
θ
)
=
∑
d
=
1
D
∑
i
=
1
N
1
2
D
N
∣
∣
y
(
i
)
−
y
^
d
(
i
)
∣
∣
2
l_1(\theta) = \sum_{d = 1}^D\sum_{i=1}^N \frac{1}{2DN}||y^{(i)} - \hat y_d^{(i)}||^2
l1(θ)=∑d=1D∑i=1N2DN1∣∣y(i)−y^d(i)∣∣2
对于最后的输出,有loss:
l
2
(
θ
)
=
∑
i
=
1
N
1
2
N
∣
∣
y
(
i
)
−
∑
d
=
1
D
w
d
⋅
y
^
d
(
i
)
∣
∣
2
l_2(\theta) = \sum_{i=1}^N \frac{1}{2N}||y^(i) - \sum_{d=1}^D w_d \cdot \hat y_d^{(i)}||^2
l2(θ)=∑i=1N2N1∣∣y(i)−∑d=1Dwd⋅y^d(i)∣∣2
总的loss:
L
(
θ
)
=
α
l
1
(
θ
)
+
(
1
−
α
)
l
2
(
θ
)
+
β
∣
∣
θ
∣
∣
2
L(\theta) = \alpha l_1(\theta) + (1-\alpha)l_2(\theta) + \beta||\theta||^2
L(θ)=αl1(θ)+(1−α)l2(θ)+β∣∣θ∣∣2
α
\alpha
α前期比较大有利于训练收敛,后面逐渐变小。
6.Residual Dense Network for Image Super-Resolution(RDN 2018CVPR)
用上分层的信息做图像的超分重建,代码地址
- 提出了一个RDN(residual dense network),网络用上了LR图片的多层特征,并且有多种退化的模型
- 提出了RDB(residual dense block)模块,用了CM(contiguous memory)机制,用了LFF(local feature fusion)
- 用了global feature fusion
6.1 Method
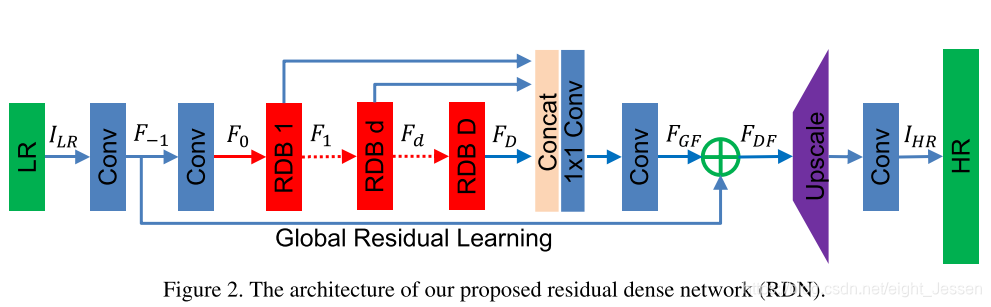
6.1.1 网络结构
网络输入记为 I L R I_{LR} ILR和 I S R I_{SR} ISR,整体结构包括了四部分:
- shallow featre extraction net(SFENet)
- residual dense blocks (RDBs)
- dense feature fusion (DFF)
- up-sampling net (UPNet)
I
S
R
=
H
R
D
N
(
I
L
R
)
I_{SR} = H_{RDN}(I_{LR})
ISR=HRDN(ILR)
第一层提取了LR输入的特征
F
−
1
F_{-1}
F−1,
F
−
1
=
H
S
F
E
1
(
I
L
R
)
F_{-1} = H_{SFE1}(I_{LR})
F−1=HSFE1(ILR),
F
0
=
H
S
F
E
2
(
F
−
1
)
F_0 = H_{SFE2}(F_{-1})
F0=HSFE2(F−1)
假设有
D
D
D个RSB, 第
d
d
d个输出
F
d
F_d
Fd ,
F
d
=
H
R
D
B
,
d
(
F
d
−
1
)
=
H
R
D
B
,
d
(
H
R
D
B
,
d
−
1
(
.
.
.
(
H
R
D
B
,
1
(
F
0
)
)
.
.
.
)
)
F_d = H_{RDB,d}(F_{d-1}) = H_{RDB,d}(H_{RDB,d-1}(...(H_{RDB,1}(F_0))...))
Fd=HRDB,d(Fd−1)=HRDB,d(HRDB,d−1(...(HRDB,1(F0))...))
H
R
D
B
,
d
H_{RDB,d}
HRDB,d是一个函数的组合操作,比如卷积和修正线性函数
然后进行DFF(dense feature fusion) ,包括了GFF(global feature fusion)和GRL(global residual learning)
F
D
F
=
H
D
F
F
(
F
−
1
,
F
0
,
F
1
,
.
.
.
,
F
D
)
F_{DF} = H_{DFF}(F_{-1}, F_0, F_1, ... , F_D)
FDF=HDFF(F−1,F0,F1,...,FD)
然后上采样,用了ESPCN。
6.1.2 Residual Dense Block

RDB 包括了dense connected layers, local feature fusion(LFF), local residual learning, 学了了一个contiguous memory(CM)机制。
CM
第d个RDB的输入,输出分别记为
F
d
−
1
F_{d-1}
Fd−1,
F
d
F_d
Fd,各自都有
G
0
G_0
G0个feature maps,有
F
d
,
c
=
σ
(
W
d
,
c
[
F
d
−
1
,
F
d
,
.
.
.
,
F
d
,
c
−
1
]
)
F_{d,c} = \sigma(W_{d,c}[F_{d-1}, F_d, ... ,F_{d, c-1}])
Fd,c=σ(Wd,c[Fd−1,Fd,...,Fd,c−1])
σ
\sigma
σ是ReLU函数,假设
F
d
,
c
F_{d,c}
Fd,c有G个feature maps,
[
F
d
−
1
,
F
d
,
.
.
.
,
F
d
,
c
−
1
]
[F_{d-1}, F_d, ... ,F_{d, c-1}]
[Fd−1,Fd,...,Fd,c−1]表示里面第
(
d
−
1
)
(d-1)
(d−1)个RDB的特征和第
d
d
d个RDB的第
1
,
.
.
.
,
(
c
−
1
)
1,...,(c-1)
1,...,(c−1)卷积特征的结合,最终有
G
0
+
(
C
−
1
)
∗
G
G_0 + (C-1)*G
G0+(C−1)∗G个特征。
LFF
F
d
,
L
F
=
H
L
F
F
d
(
[
F
d
−
1
,
F
d
,
1
,
.
.
.
,
F
d
,
c
,
.
.
.
,
F
d
,
C
]
)
F_{d,LF} = H_{LFF}^d([F_{d-1}, F_{d,1},...,F_{d,c},...,F_{d,C}])
Fd,LF=HLFFd([Fd−1,Fd,1,...,Fd,c,...,Fd,C])
H
L
F
F
d
H_{LFF}^d
HLFFd是第
d
d
d个RDB的
1
∗
1
1*1
1∗1卷积。
LRL Local residal learning
为了提高信息流。
F
d
=
F
d
−
1
+
F
d
,
L
F
F_d = F_{d-1}+F_{d,LF}
Fd=Fd−1+Fd,LF
6.1.3 Dense Feature Fusion
DFF包含了global feature fusion(GFF)和global residual learning
GFF
F
G
F
=
H
G
F
F
(
[
F
1
,
.
.
.
,
F
D
]
)
F_{GF} = H_{GFF}([F_1,...,F_D])
FGF=HGFF([F1,...,FD])
[
F
1
,
.
.
.
,
F
D
]
[F_1,...,F_D]
[F1,...,FD]是每个RDB的特征,
H
G
F
F
H_{GFF}
HGFF包括了
1
∗
1
1*1
1∗1和
3
∗
3
3*3
3∗3的卷积。
1
∗
1
1*1
1∗1用于自适应地融合具有不同级别的一系列功能。
Global residual learning
F
D
F
=
F
−
1
+
F
G
F
F_{DF} = F_{-1} + F_{GF}
FDF=F−1+FGF
F
−
1
F_{-1}
F−1是浅层特征,其他的是全局融合特征。
6.2 评价指标
用PSNR和SSIM对变换后的YCbCr空间的Y通道(即亮度)进行结果评估
7.Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks(LapSRN TPAMI 2018)
7.1 网络结构
基于拉普拉斯金字塔框架,有
l
o
g
2
S
log_2^S
log2S层金字塔结构,S为缩放的系数。比如如果为8倍(
S
=
8
S=8
S=8),那么就有三层结构。
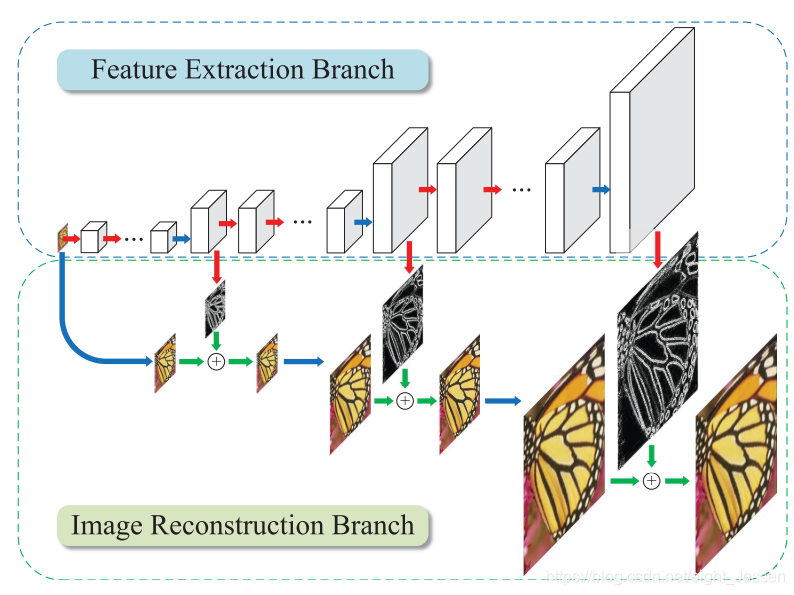
7.1.1 特征提取分支
包括了三部分:
- a feature embedding sub-network(高纬度非线性特征映射)
- a tranposed convolution layer(上采样提取的特征)
- a convolutional layer(预测sub-band残差图像)
第一个金字塔结构还有一个额外的特征提取网络从LR图像提取特征,之后的金字塔结构直接把上一层upscaled之后的特征作为输入
7.1.2 图片重建网络
图片通过一个转置卷积层(transposed convolutional layer)上采样2倍,这个卷积层初始是 4 ∗ 4 4*4 4∗4的双线性核。然后组合上采样的图和预测的残差图片产生HR图像。然后用于下一层的输入。每一层是相同的结构。
7.2 Feature embedding sub-network
网络越深,参数越多,下面用两种方法减少参数
7.2.1 金字塔层间参数共享
因为每层金字塔都是相同的任务,放大相同的倍数
最终网络参数与放大倍数无关,使用一个参数集就可以实现放大不同的倍数。
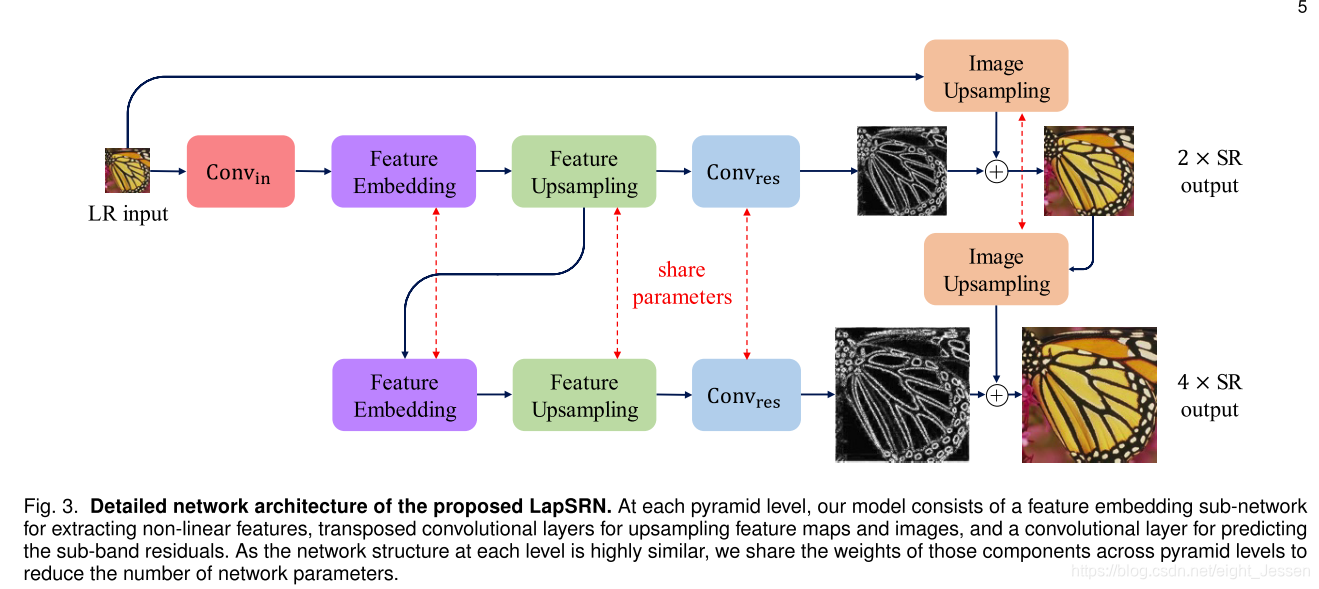
7.2.2 金字塔层内参数共享
将feature embedding sub-network扩展成深度递归层
如果每个feature embedding sub-network有
R
R
R次循环模块,模块有
D
D
D层,那么整个网络的深度为
d
e
p
t
h
=
(
D
∗
R
+
1
)
∗
L
+
2
depth = (D * R + 1) * L + 2
depth=(D∗R+1)∗L+2
L
=
l
o
g
2
S
L = log_2 S
L=log2S,括号里的1表示转置卷积层,
2
2
2表示作用与输入图片的卷积和最后一层预测残差的卷积。
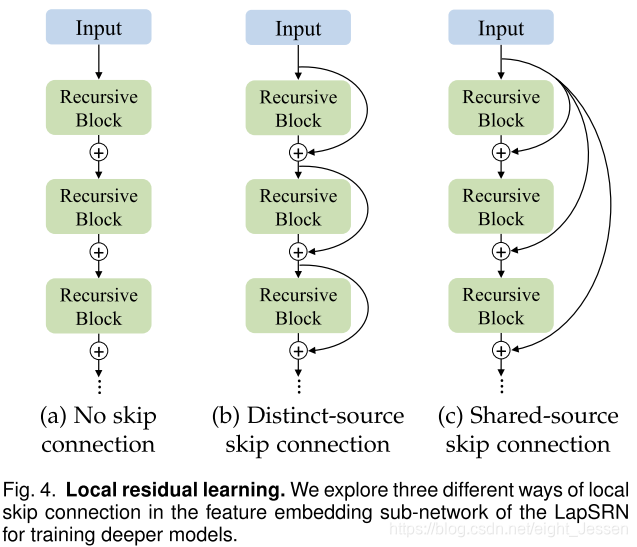
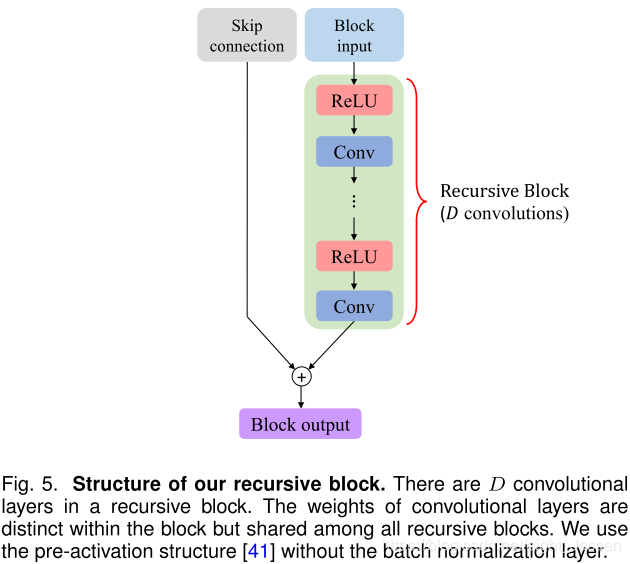
7.2.3 Local residual learning
解决梯度爆炸\消失问题,在feature embedding sub-network探索了三种方法:
- No sikp connection,表示为 L a p S R N N S LapSRN_{NS} LapSRNNS
- Distinct-source skip connection,记为 L a p S R N D S LapSRN_{DS} LapSRNDS
- Shared-source skip connection,记为 L a p S R N S S LapSRN_{SS} LapSRNSS
7.3 Loss function
输入
x
x
x,网络参数
θ
\theta
θ,输出
y
^
\hat y
y^,网络可表示为
y
^
=
f
(
x
;
θ
)
\hat y = f(x;\theta)
y^=f(x;θ),尽可能与gt
y
y
y相同。将第
l
l
l层的残差图像表示为
r
^
l
\hat r_l
r^l,upscale的图像记为
x
l
x_l
xl和对应的
y
^
l
\hat y_l
y^l,第
l
l
l层输出的图像为
y
^
l
x
l
+
r
^
l
\hat y_l x_l + \hat r_l
y^lxl+r^l,使用双三次插值算法将gt下采样到
y
l
y_l
yl大小。鲁棒损失函数来处理异常值
L
S
(
y
,
y
^
;
θ
)
=
1
N
∑
i
=
1
N
∑
l
=
1
L
ρ
(
y
l
(
i
)
−
y
^
l
(
i
)
)
=
1
N
∑
i
=
1
N
∑
l
=
1
L
ρ
(
(
y
l
(
i
)
−
x
l
(
i
)
)
−
r
^
l
(
i
)
)
L_S(y, \hat y ; \theta) = \frac{1}{N}\sum_{i=1}^N\sum_{l=1}^{L}\rho(y_l^{(i)} - \hat y_l^{(i)}) = \frac{1}{N}\sum_{i=1}^N\sum_{l=1}^{L}\rho((y_l^{(i)} - x_l^{(i)}) - \hat r_l^{(i)})
LS(y,y^;θ)=N1i=1∑Nl=1∑Lρ(yl(i)−y^l(i))=N1i=1∑Nl=1∑Lρ((yl(i)−xl(i))−r^l(i))
ρ
(
x
)
=
(
x
2
+
ϵ
2
)
\rho(x) = \sqrt{(x^2 + \epsilon^2)}
ρ(x)=(x2+ϵ2),Charbonnier penalty function L1范数的一个可微变量,通常设
ϵ
\epsilon
ϵ为
1
e
−
3
1e-3
1e−3。
在提出的模型中,每个level,
s
s
s都有他loss方程和对应的gt,这种multi-scale的监督使网络重建图像实现了coarse-to-fine的模式,减少空间混叠伪影。
7.4 Multi-scale training
使用了不同的scale去训练网络,同时不同的unsampling scale samples由不同的层输出。最终组合的loss为:
L
(
y
,
y
^
;
θ
)
=
∑
S
∈
{
2
,
4
,
8
}
L
s
(
y
,
y
^
;
θ
)
L(y, \hat y ;\theta) = \sum_{S\in\{2,4,8\}}L_s(y, \hat y; \theta)
L(y,y^;θ)=∑S∈{2,4,8}Ls(y,y^;θ)
但是对于基于pre-upsampling的方法,图片可以缩放在任意的scale,但是对于LapSRN,只能是
2
n
∗
S
R
2^n * SR
2n∗SR,
n
n
n为整数。
8. Image Super-Resolution Using Dense Skip Connections(SRDenseNet ICCV2017)
使用DenseNet作为网络的基础模块,通过dense skip connections实现SISR
8.1 Method
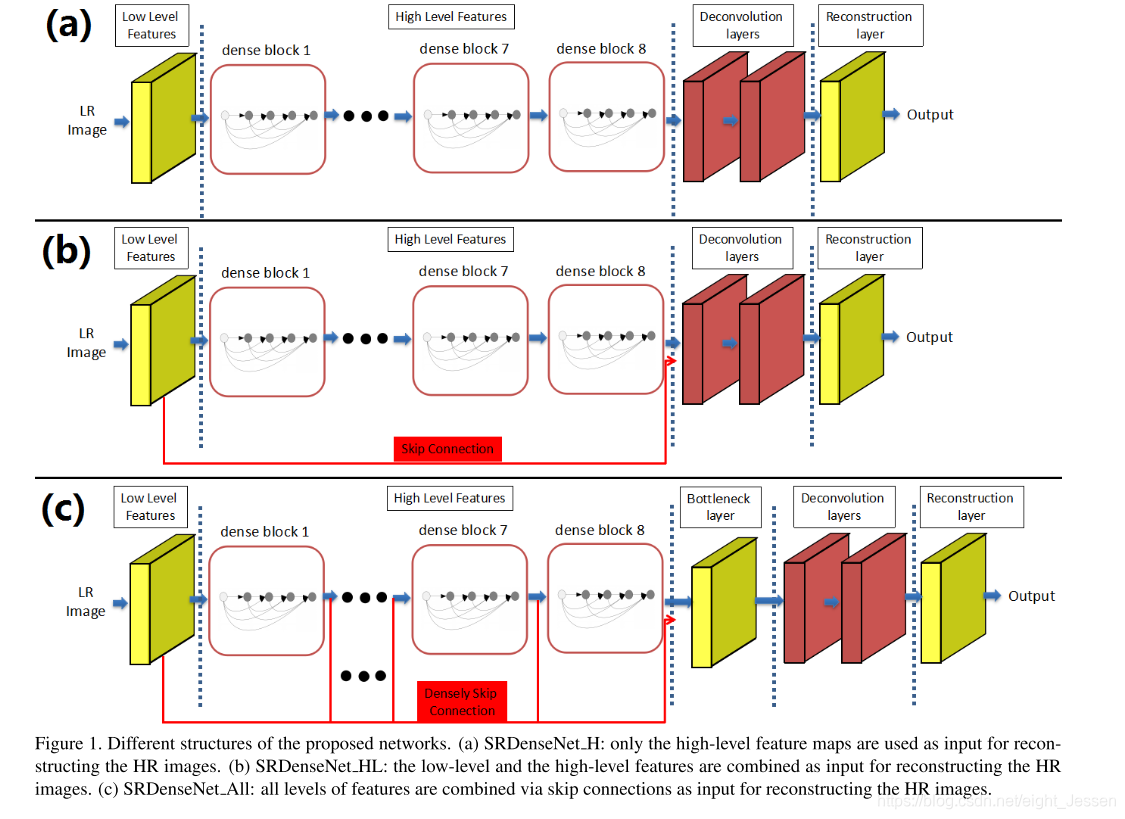
网络可以分解为几个部分:
- 一个用于学习low-level特征的卷积
- DenseNet模块,用于提取高层信息
- deconvolution反卷积层,用于上采样
每个卷积后面都加上ReLU做非线性映射,除了重建层,第i层卷积的输入表示为 X i − 1 X_{i - 1} Xi−1,输出可表示为 X i = m a x ( 0 , w i ∗ X i − 1 + b i ) X_i = max(0, w_i * X_{i-1} + b_i) Xi=max(0,wi∗Xi−1+bi)
对于给定的训练图片
{
I
L
k
,
I
H
k
}
\{I_L^k, I_H^k\}
{ILk,IHk},最小化MSE
l
(
Θ
)
=
1
N
∑
k
=
1
N
∣
∣
F
(
I
K
m
,
Θ
)
−
I
H
k
∣
∣
2
2
l(\Theta) = \frac{1}{N}\sum_{k=1}^N||F(I_K^m,\Theta) - I_H^k||_2^2
l(Θ)=N1k=1∑N∣∣F(IKm,Θ)−IHk∣∣22
8.2 DenseNet blocaks
第i层活接受之前所有层的特征作为输入
X
i
=
m
a
x
(
0
,
w
i
∗
[
X
1
,
X
2
,
.
.
.
,
X
i
−
1
]
+
b
i
)
X_i = max(0, w_i * [X_1, X_2, ... ,X_{i-1}] + b_i)
Xi=max(0,wi∗[X1,X2,...,Xi−1]+bi)
[
X
1
,
X
2
,
.
.
.
,
X
i
−
1
]
[X_1, X_2, ... ,X_{i-1}]
[X1,X2,...,Xi−1]表示concatenation,如果对于每一个block,有8个卷积层,每层有
k
k
k个特征输出,那么每个Dense Block输出的特征是
k
∗
8
k*8
k∗8,这里
k
k
k就是指增长率,表示每层能为最终重建层提供多少信息。
8.3 Deconvolution layers
两个 3 ∗ 3 3*3 3∗3的反卷积核,feature map为256
8.4 Combination of feature maps
见上图
8.5 Bottleneck and Reconstruction layers
如果所有的block出来的特征信息送入到反卷积网络,会增加计算消耗和增大模型。所以需要先较小输入的特征信息。故用了 1 ∗ 1 1*1 1∗1的卷积核作为bottleneck。最终送入到deconvolution层的特征层为256.然后使用 3 ∗ 3 3*3 3∗3的网络做反卷积。
9.Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
图片超分是一个一对多的问题
之前的方法对超分比例比较大的图片无法恢复出精细的纹理细节。之前只要用MSE PSNR
作者用GAN的方法,得到更精细的图片细节,引入了一个perceptual loss function,包括了对抗loss和内容loss两部分。

9.1 Method
I
L
R
I^{LR}
ILR由
I
H
R
I^{HR}
IHR经过高斯滤波然后下采样倍数
r
r
r得到。如果低像素图片
I
L
R
I^{LR}
ILR是
W
∗
H
∗
C
W*H*C
W∗H∗C,上采样结果是
r
W
∗
r
H
∗
C
rW*rH*C
rW∗rH∗C。我们的最终目标是训练一个生成函数G来估计给定的LR输入图像对应的HR对应图像。
于是训练一个generator ,CNN
G
θ
G
G_{\theta_G}
GθG,
θ
G
=
{
W
1
:
L
;
b
1
:
L
}
\theta_G = \{W_{1:L};b_{1:L}\}
θG={W1:L;b1:L}表示L层网络的权重和方差,通过
l
S
R
l^{SR}
lSR 优化,对于
I
n
H
R
,
n
=
1
,
.
.
.
,
N
I_{n}^{HR}, n = 1,...,N
InHR,n=1,...,N对应的
I
n
L
R
,
n
=
1
,
.
.
.
,
N
I_n^{LR}, n = 1, ... , N
InLR,n=1,...,N
θ
^
G
=
a
r
g
m
i
n
θ
G
1
N
∑
n
=
1
N
l
S
R
(
G
θ
G
(
I
n
L
R
)
,
I
n
H
R
)
\hat \theta_G = argmin_{\theta_G} \frac{1}{N}\sum_{n=1}^N l^{SR}(G_{\theta_G}(I_n^{LR}), I_n^{HR})
θ^G=argminθGN1n=1∑NlSR(GθG(InLR),InHR)
作者设计了一个perceptual loss
l
S
R
l^{SR}
lSR 最为几个loss的组合。对恢复后的SR图像进行了清晰的特征建模。
9.1.1 Adversarial Network Architecture
m i n θ G m a x θ D E I H R ∼ p t r a i n ( I H R ) [ l o g D θ D ( I H R ) ] + E I L R ∼ p G ( I L R ) [ l o g ( 1 − D θ D ( G θ G ( I L R ) ) ) ] \begin{aligned} min_{\theta_G} max_{\theta_D} E_{I^{HR} \sim p_{train}(I^{HR})}[log D_{\theta_D}(I^{HR})] + \\E_{I^{LR} \sim p_G(I^{LR})}[log(1 - D_{\theta_D}(G_{\theta_G}(I^{LR})))] \end{aligned} minθGmaxθDEIHR∼ptrain(IHR)[logDθD(IHR)]+EILR∼pG(ILR)[log(1−DθD(GθG(ILR)))]
9.1.2 Perceptual Loss
给了权重参数 γ i , i = 1 , . . . , K \gamma_i,i=1,...,K γi,i=1,...,K。定义 l S R = ∑ i = 1 K γ i l i S R l^{SR} = \sum_{i=1}^K \gamma_i l_i^{SR} lSR=∑i=1KγiliSR 作为单个损失函数的加权和。
- Content Loss
pixel-wise MSE loss可以由下面计算 l M S E S R = 1 r 2 W H ∑ x = 1 r W ∑ y = 1 r H ( I x , y H R − G θ G ( I L R ) x , y ) 2 l_{MSE}^{SR} = \frac{1}{r^2WH}\sum_{x=1}^{rW}\sum_{y=1}^{rH}(I_{x,y}^{HR} - G_{\theta_G}(I^{LR})_{x,y})^2 lMSESR=r2WH1x=1∑rWy=1∑rH(Ix,yHR−GθG(ILR)x,y)2作者设计了VGG loss, ϕ i , j \phi_{i,j} ϕi,j表示由第i个最大池化层后第j个卷积层出来的特征。定义为一个欧拉距离。
I V G G / i , j S R = 1 W i , j H i , j ∑ x = 1 W i , j ∑ j = 1 H i , j ( ϕ i , j ( I H R ) ) x , y − ϕ i , j ( G θ G ( I L R ) x , y ) 2 I_{VGG/i,j}^{SR} = \frac{1}{W_{i,j}H_{i,j}}\sum_{x=1}^{W_{i,j}}\sum_{j=1}^{H_{i,j}}(\phi_{i,j}(I^{HR}))_{x,y} - \phi_{i,j}(G_{\theta_G}(I^{LR})_{x,y})^2 IVGG/i,jSR=Wi,jHi,j1x=1∑Wi,jj=1∑Hi,j(ϕi,j(IHR))x,y−ϕi,j(GθG(ILR)x,y)2 - Adversarial Loss
generative loss,基于所有数据在discriminator D θ D ( G θ G ( I L R ) ) D_{\theta_D}(G_{\theta_G}(I^{LR})) DθD(GθG(ILR))上的概率分布
l G e n S R = ∑ n = 1 N − l o g D θ D ( G θ G ( I L R ) ) l_{Gen}^{SR} = \sum_{n=1}^N -logD_{\theta_D}(G_{\theta_G}(I^{LR})) lGenSR=n=1∑N−logDθD(GθG(ILR)) - Regularization Loss
- 基于总体的方差
l T V S R = 1 r 2 W H ∑ x = 1 r W ∑ y = 1 r H ∣ ∣ ∇ G θ G ( I L R ) x , y ∣ ∣ l_{TV}^{SR} = \frac{1}{r^2WH}\sum_{x=1}^{rW}\sum_{y=1}^{rH}||∇G_{\theta_G}(I^{LR})_{x,y}|| lTVSR=r2WH1x=1∑rWy=1∑rH∣∣∇GθG(ILR)x,y∣∣














 4177
4177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









