







 本文介绍了MSRA在ICCV2017发表的论文,提出了一种Flow-Guided Feature Aggregation (FGFA)方法,利用相邻帧信息增强当前帧特征,以提高视频物体检测的准确性,尤其是在快速移动物体识别上表现出色。FGFA包括光流估计、特征聚合等模块,所有模块端到端训练,解决了现有方法中仅在box-level使用时间信息的局限性。
本文介绍了MSRA在ICCV2017发表的论文,提出了一种Flow-Guided Feature Aggregation (FGFA)方法,利用相邻帧信息增强当前帧特征,以提高视频物体检测的准确性,尤其是在快速移动物体识别上表现出色。FGFA包括光流估计、特征聚合等模块,所有模块端到端训练,解决了现有方法中仅在box-level使用时间信息的局限性。
论文链接:https://arxiv.org/abs/1703.10025
代码链接:https://github.com/msracver/Flow-Guided-Feature-Aggregation
这篇是MSRA发表在ICCV2017上的VID方面的论文,算是之前的工作Deep Feature Flow的一个延续。这篇文章的亮点在于利用了前后帧的信息加强当前帧的特征,从而得到较好的识别精度。但是速度上会比较慢。那我们开始吧。
1.Abstract
视频中的物体检测会受到诸如运动模糊、视频散焦、奇特姿态等的影响。现有的工作尝试从box-level使用temporal信息,但是这种方法不能端到端地进行训练。我们提出了FGFA,在frame-level使用temporal信息。它将相邻帧在motion paths上的特征聚合到当前帧的特征中,因此提高了视频识别的精度。我们的方法极大地提升了ImageNet VID上的single-frame baselines。特别是在识别快速移动的物体方面,此方法和Deep feature flow一起赢得了ImageNet 2017
2.Introduction
物体检测一般都是二阶段结构,首先CNN提取feature map,然后检测特定的网络用于从feature maps 中生成检测结果。
这些方法对于still image效果很好,但是直接用到vedio上效果会恶化很多,例如state-of-the-art RFCN+ResNet-101在对快速运动中的物体进行识别的时候效果恶化得很厉害
然后,视频中拥有丰富的对于单个物体实例的信息,通常会在一小段时间中的多个snapshots看到,这些时间信息用在现有的视频物体检测的方法中,则表现为:首先用物体检测器在单帧上进行检测,然后通过专用的后处理方法将这些bbox组合起来,后处理通常是通过现在的motion estimation的方法,例如光流,物体跟踪等。这些方法不会提高检测质量,性能的提升是来自启发式的后处理而不是有原则的学习过程。对于这类方法没有端到端的学习过程。我们把这些方法叫做box level methods
我们希望能够利用时间信息提升检测或识别的质量,以一种有原则的方式。受图像识别的启发,特征很重要,因此我们利用时间域的聚合提升单帧特征的学习。注意,同一物体的特征用于视频运动的原因,在不同帧是空间不对齐的。盲目的特征聚合可能会使性能变差,这说明在学习过程中对运动进行良好的建模很重要。
在此工作中,我们提出了FGFA,如图1所示,特征提取的网络在单帧上提取单帧的feature maps,然后为了加强当前帧的特征,一个光流网络用于估计相邻帧和当前帧的运动。相邻帧的feature maps再根据光流运动中warp到当前帧,warp后的feature map以及它自己的feature map一起通过适应权重网络进行聚合。(在当前帧)然后聚合得到的feature map再被送到检测网络中输出当前帧的检测结果。所有模块,包括特征提取,光流估计,特征聚合,检测都是端到端进行训练的,对于快速运动中的物体,普通的方法效果很差,但我们的方法有效地利用了不同snapshot间的丰富表现信息,这也是我们的方法取得VID冠军的致胜点(对于快速运动物体识别好)
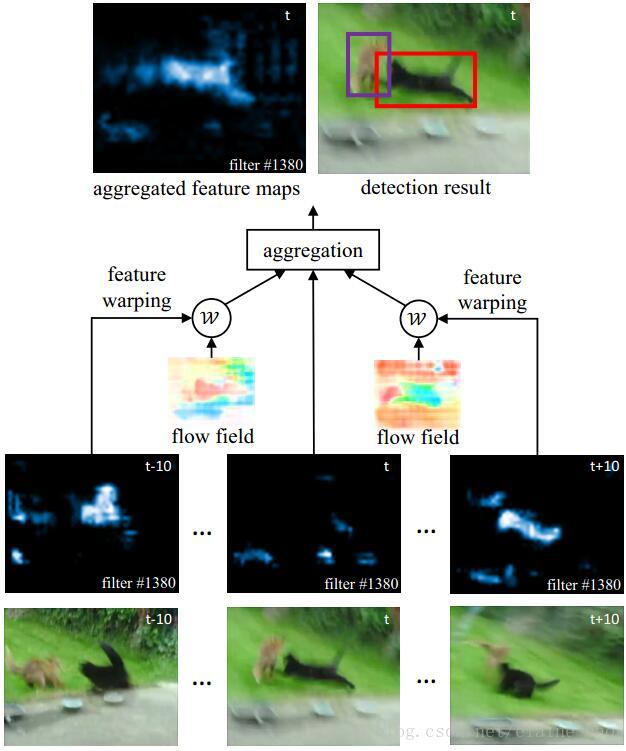
3.Flow Guided Feature Aggregation
3.1 Baseline and Motivation
给定输入的视频帧{
Ii },我们的目标是输出所有帧上的物体框{
Yi }。Baseline就是在每帧上单独使用现有的物体检测器。
现有的CNN-based物体检测器结构相似,输入图片I,CNN提取特征得到Nfeat( I )=f feature maps,然后一个专用于detection的子网络用于生成检测结果
视频帧会有很剧烈的表现变化,如图2所示,当画面很差的时候,单帧的检测结果很不稳定,易出错。图1给出了一个例子,在

特征传递和加强需要两个模块实现:(1)motion-guided spatial warping.在帧间估计运动然后将feature map进行warp。(2)feature aggregation module.它用于正确地将不同帧的特征进行融合,再加上特征提取和检测网络,共同组成了我们方法的四个模块。
3.2 Model Design
Flow-guided warping.给定一帧{
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









