






Redis 一共有5种数据结构,包括:
- 字符串(String)
string 是Redis的最基本的数据类型,可以理解为与 Memcached 一模一样的类型,一个key 对应一个 value。string 类型是二进制安全的,意思是 Redis 的 string 可以包含任何数据,比如图片或者序列化的对象,一个 redis 中字符串 value 最多可以是 512M。
应用:Redis对于KV的操作效率很高,可以直接用作计数器。例如,统计在线人数等等,另外string类型是二进制存储安全的,所以也可以使用它来存储图片,甚至是视频等。
- 哈希(hash)
hash 是一个键值对集合,是一个 string 类型的 key和 value 的映射表,key 还是key,但是value是一个键值对(key-value)。类比于 Java里面的 Map<String,Map<String,Object>> 集合。
应用:存放键值对,一般可以用来存某个对象的基本属性信息,例如,用户信息,商品信息等,另外,由于hash的大小在小于配置的大小的时候使用的是ziplist结构,比较节约内存,所以针对大量的数据存储可以考虑使用hash来分段存储来达到压缩数据量,节约内存的目的,例如,对于大批量的商品对应的图片地址名称。比如:商品编码固定是10位,可以选取前7位做为hash的key,后三位作为field,图片地址作为value。这样每个hash表都不超过999个,只要把redis.conf中的hash-max-ziplist-entries改为1024,即可。
- 列表(List)
list 列表,它是简单的字符串列表,按照插入顺序排序,你可以添加一个元素到列表的头部(左边)或者尾部(右边),它的底层实际上是个链表。列表有两个特点:有序、可以重复。Redis的list共有两种,一种是压缩列表(ziplist),另一种是双向循环链表。
应用:可以用于实现消息队列,限制登陆次数,也可以使用它提供的range命令,做分页查询功能。
Redis链表特性:①、双端:链表具有前置节点和后置节点的引用,获取这两个节点时间复杂度都为O(1)。②、无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问都是以 NULL 结束。③、带链表长度计数器:通过 len 属性获取链表长度的时间复杂度为 O(1)。④、多态:链表节点使用 void* 指针来保存节点值,可以保存各种不同类型的值。
- 集合(Set)
Redis 的 set 是 string 类型的无序集合。相对于列表,集合也有两个特点:无序、不可重复。整数的有序列表可以直接使用set。
应用:用作某些去重功能,例如用户名不能重复等,对集合进行交集并集操作来查找某些元素的共同点。
- 有序集合(zset)
zset(sorted set 有序集合),和上面的set 数据类型一样,也是 string 类型元素的集合,但是它是有序的,使用链表加多级索引的结构。
应用:范围查找,排行榜功能或者topN功能。
Redis 中的有序集合是通过跳表来实现的,严格点讲还用到了散列表。Redis 中的有序集合支持的核心操作主要是:
- 插入一个数据;
- 删除一个数据;
- 查找一个数据;
- 按照区间查找数据(比如查找值在[100, 356]之间的数据);
- 迭代输出有序序列。
zset为什么不用红黑树?
插入、删除、查找以及迭代输出有序序列这几个操作红黑树也可以完成,且时间复杂度跟跳表一样。但按照区间来查找数据这个操作红黑树的效率没有跳表高, 跳表可以做到 O(logn) 的时间复杂度定位区间的起点,再在原始链表中顺序往后遍历,非常高效。
其他原因还有跳表更容易代码实现;跳表更加灵活,它可以通过改变索引构建策略,有效平衡执行效率和内存消耗。
Tips: 跳表不能完全替代红黑树,红黑树比跳表的出现要早一些,很多编程语言中的 Map 类型都是通过红黑树来实现,做业务开发时可以直接拿来用,不用费劲自己去实现,但跳表没有现成的实现,所以在开发中如果想使用跳表必须要自己实现。
zset为什么不用B+树?
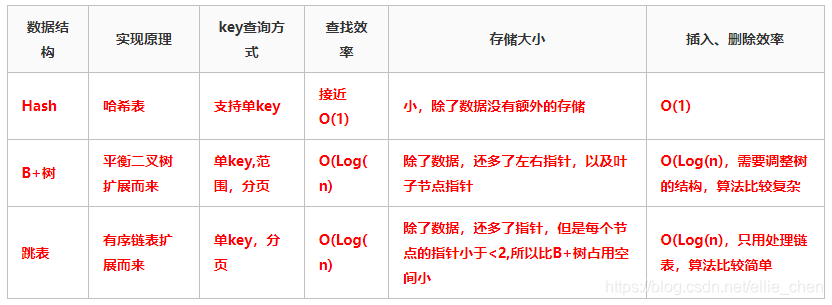
B+树的原理是叶子节点存储数据,非叶子节点存储索引,B+树的每个节点可以存储多个关键字,它将节点大小设置为磁盘页的大小,充分利用了磁盘预读的功能。每次读取磁盘页时就会读取一整个节点,每个叶子节点还有指向前后节点的指针,为的是最大限度的降低磁盘的IO;因为数据在内存中读取耗费的时间是从磁盘的IO读取的百万分之一。而Redis是内存中读取数据,不涉及IO,因此使用了跳表;
为什么Redis使用单线程读取速度还这么块?
因为Redis不涉及I/O操作,而多线程更适合用于I/O操作多的情况。
Tips:1.CPU在切换线程的时候有上下文切换时间,上下文切换时间非常耗时;但I/O操作更耗时,所以在需要频繁进行I/O操作时,应当优先考虑多线程。2.Redis的性能和CPU无关,其性能瓶颈在:a.机器内存大小,内存大小关系到Redis存储的数据量;b.网络带宽,Redis的客户端和服务端可能部署在不同的机器上,但就近部署降低往返时间RTT,提高性能。
- 数据结构持久化(存储到磁盘)
尽管 Redis 经常会被用作内存数据库,但是它也支持数据落盘,也就是将内存中的数据存储到硬盘中。这样当机器断电的时候,存储在 Redis 中的数据也不会丢失。在机器重新启动之后,Redis 只需要再将存储在硬盘中的数据,重新读取到内存,就可以继续工作了。
Redis 的数据格式由“键”和“值”两部分组成,“值”支持很多数据类型,比如字符串、列表、字典、集合、有序集合。像字典、集合等类型,底层用到了散列表,散列表中有指针的概念,而指针指向的是内存中的存储地址。
如何将数据结构持久化到硬盘?
- 清除原有的存储结构,只将数据存储到磁盘中。
当我们需要从磁盘还原数据到内存的时再重新将数据组织成原来的数据结构。实际上,Redis 采用的就是这种持久化思路。不过,这种方式也有一定的弊端。那就是数据从硬盘还原到内存的过程,会耗用比较多的时间。比如,我们现在要将散列表中的数据存储到磁盘。当我们从磁盘中,取出数据重新构建散列表的时候,需要重新计算每个数据的哈希值。如果磁盘中存储的是几 GB 的数据,那重构数据结构的耗时就不可忽视了。
- 保留原来的存储格式,将数据按照原有的格式存储在磁盘中。
我们拿散列表这样的数据结构来举例。我们可以将散列表的大小、每个数据被散列到的槽的编号等信息,都保存在磁盘中。有了这些信息,我们从磁盘中将数据还原到内存中的时候,就可以避免重新计算哈希值。














 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









