







Dify 配置语音转文字
1. 配置 Speech2text 模型
打开 “设置”,
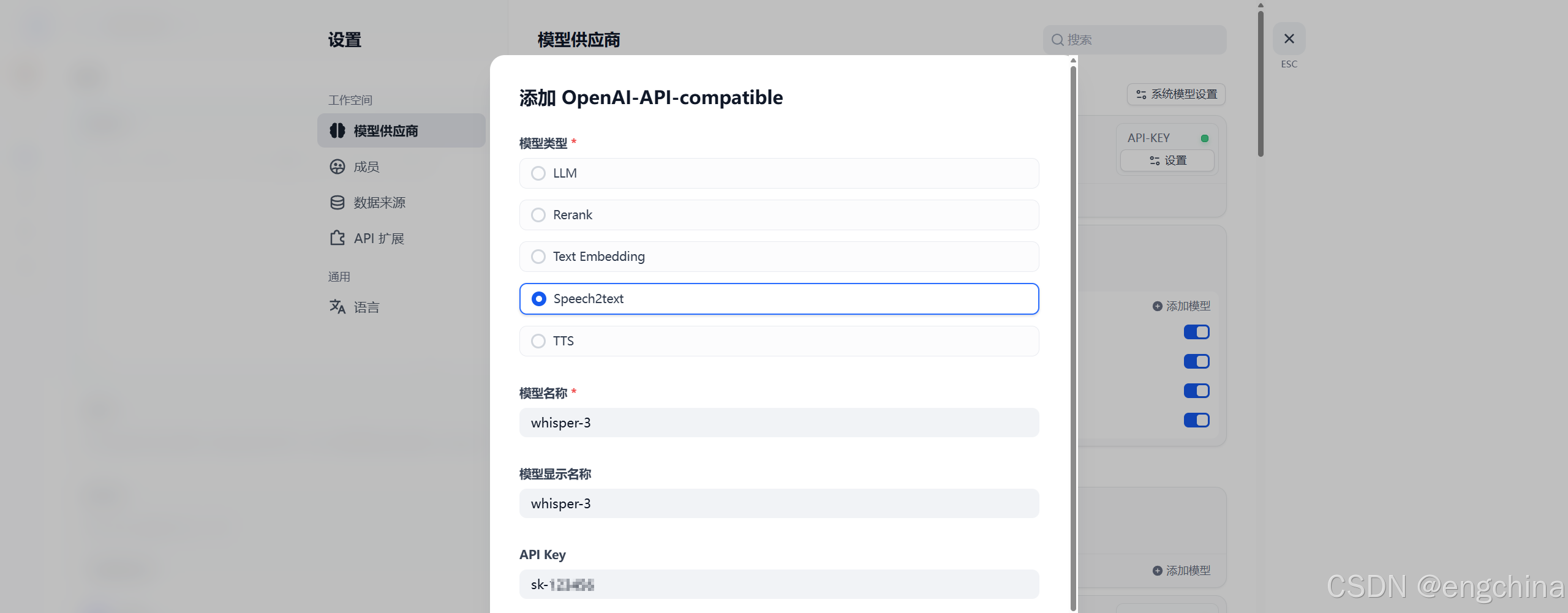
选择 模型供应商,单击 “添加模型”,

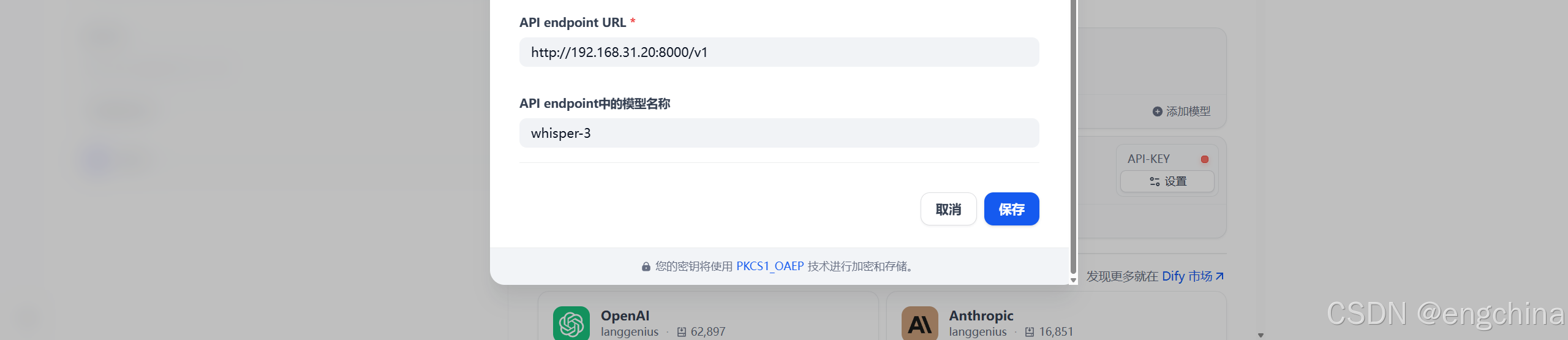
输入各个项目的信息,单击 “保存”
2. 使用 Speech2text
在调试与预览处单击 “管理”,
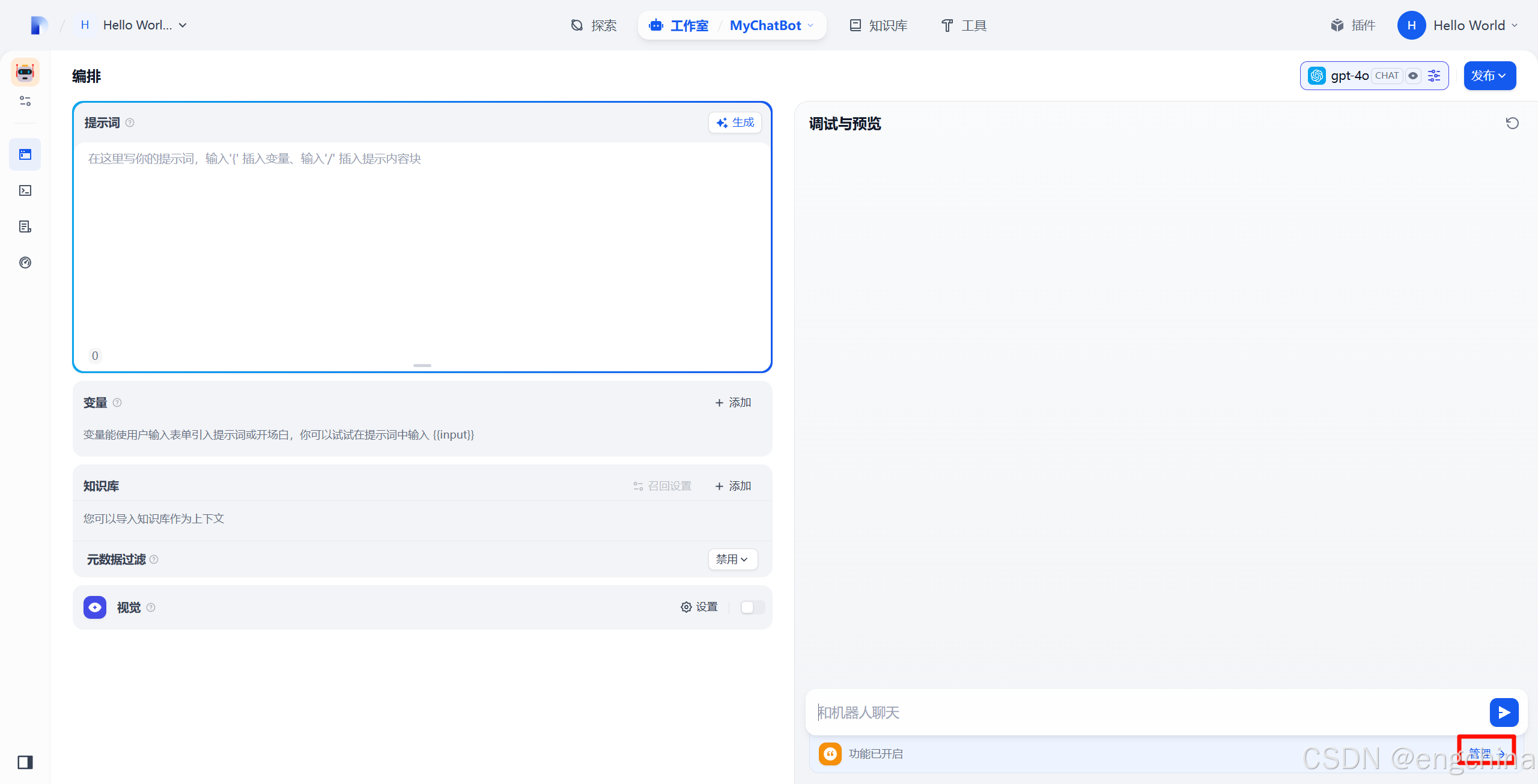
激活 “语音转文字”,
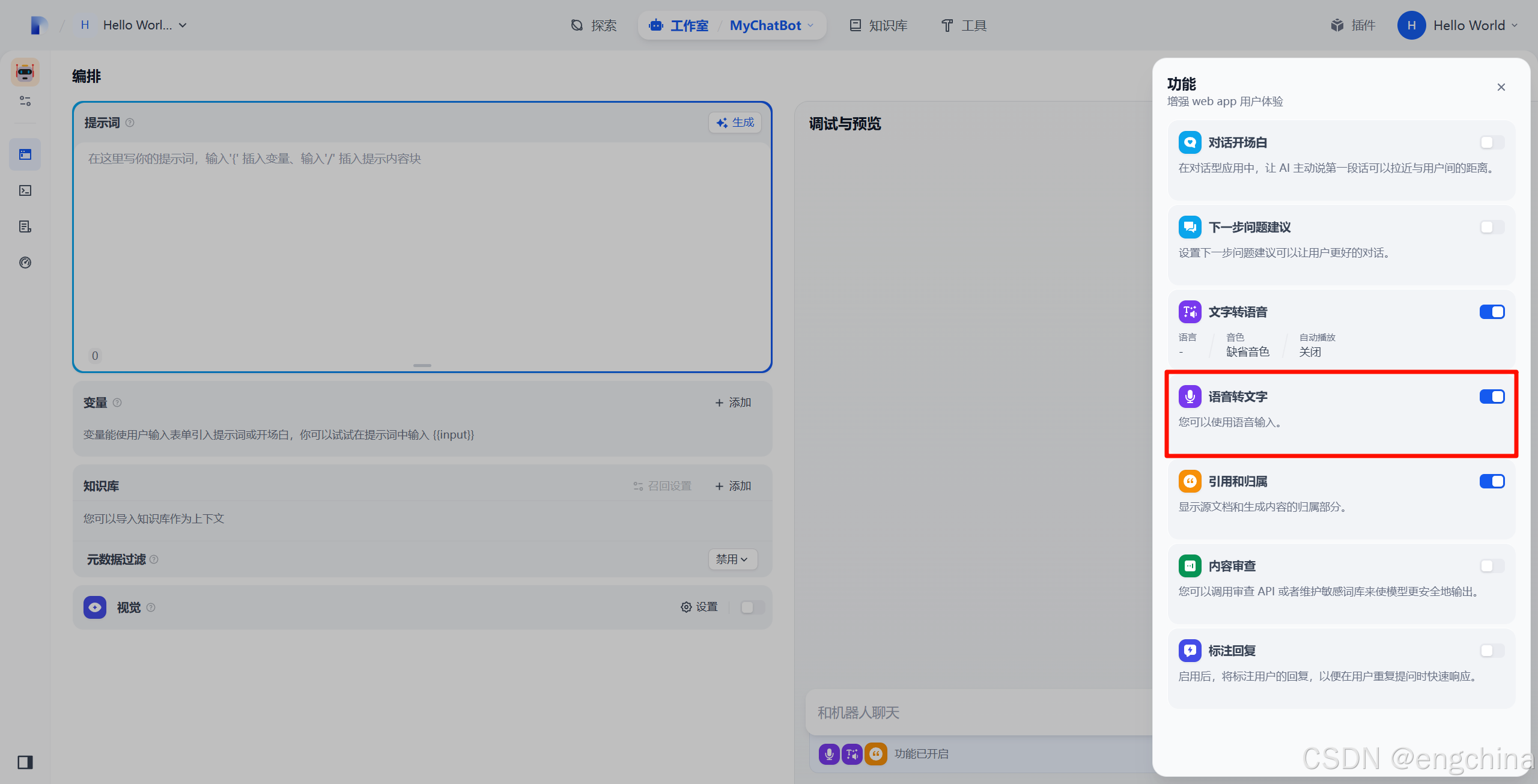
然后就可以以语音输入了,
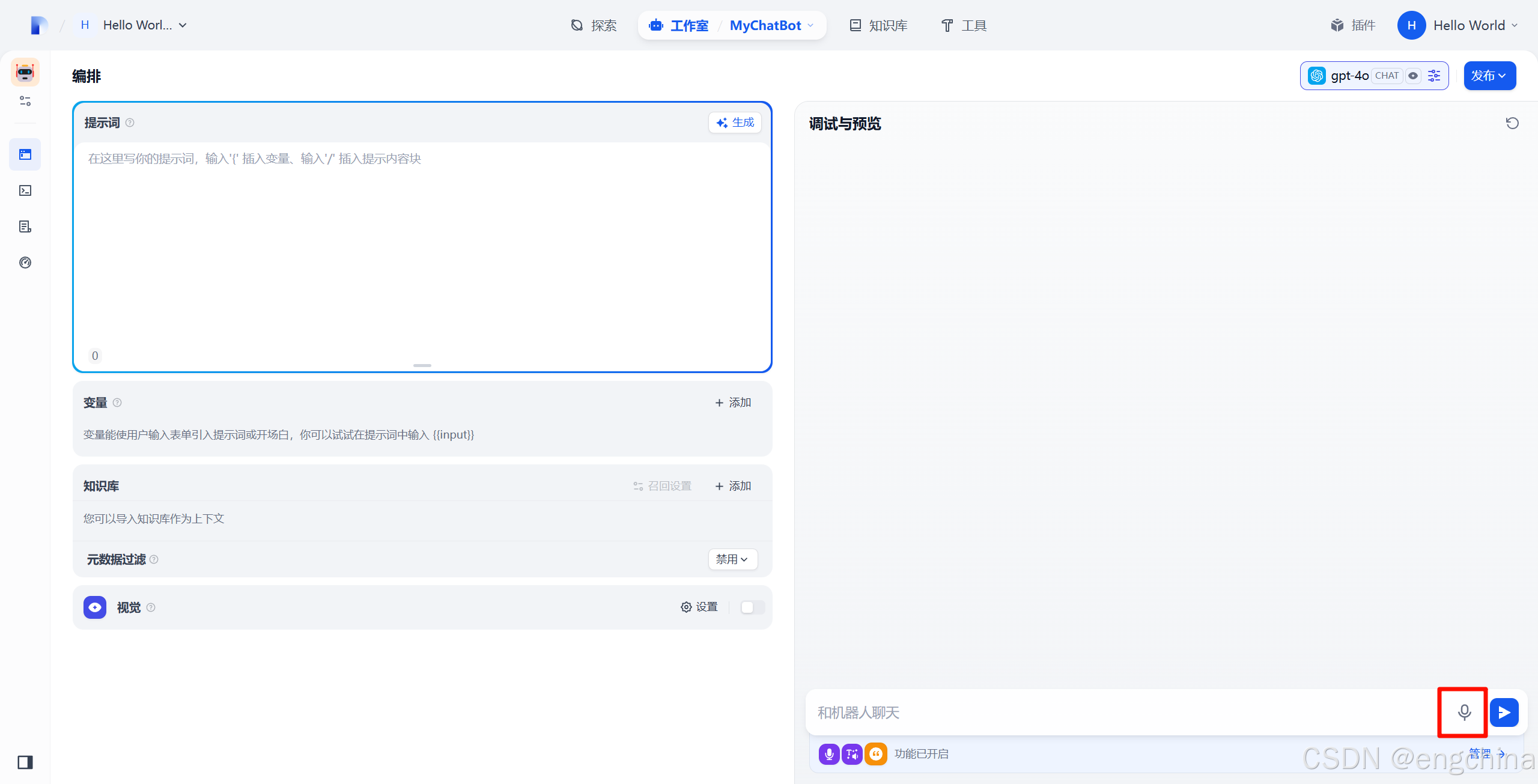
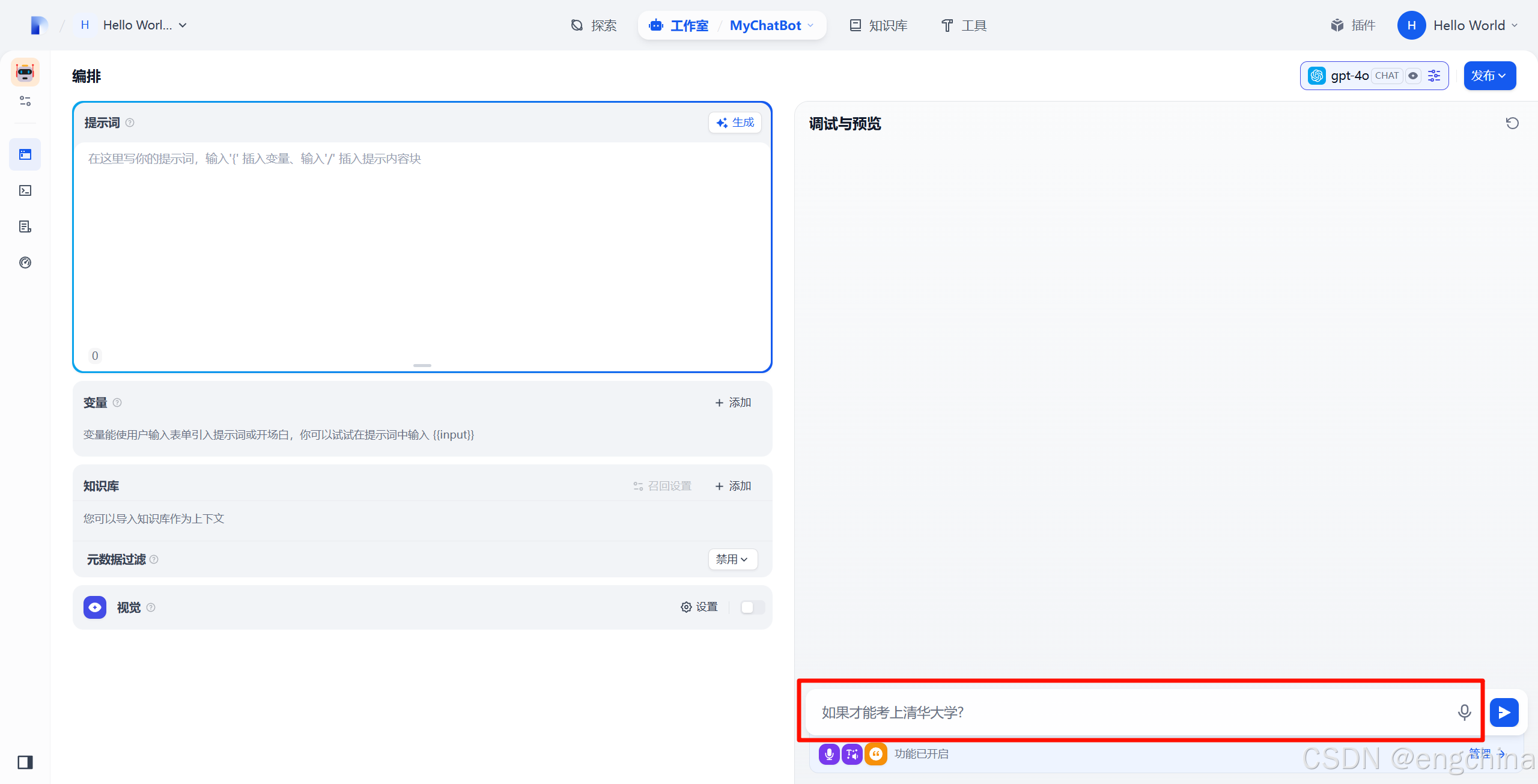
3. 测试一下
和AI聊天,使用语音输入,
4. 其他问题解决
如果报错“microphone not authorized”或者“麦克风未授权”,请按照下面方法解决,
4-1. 在线测试浏览器是否可以使用麦克风
访问https://www.microphonetest.com/使用此链接在线测试。
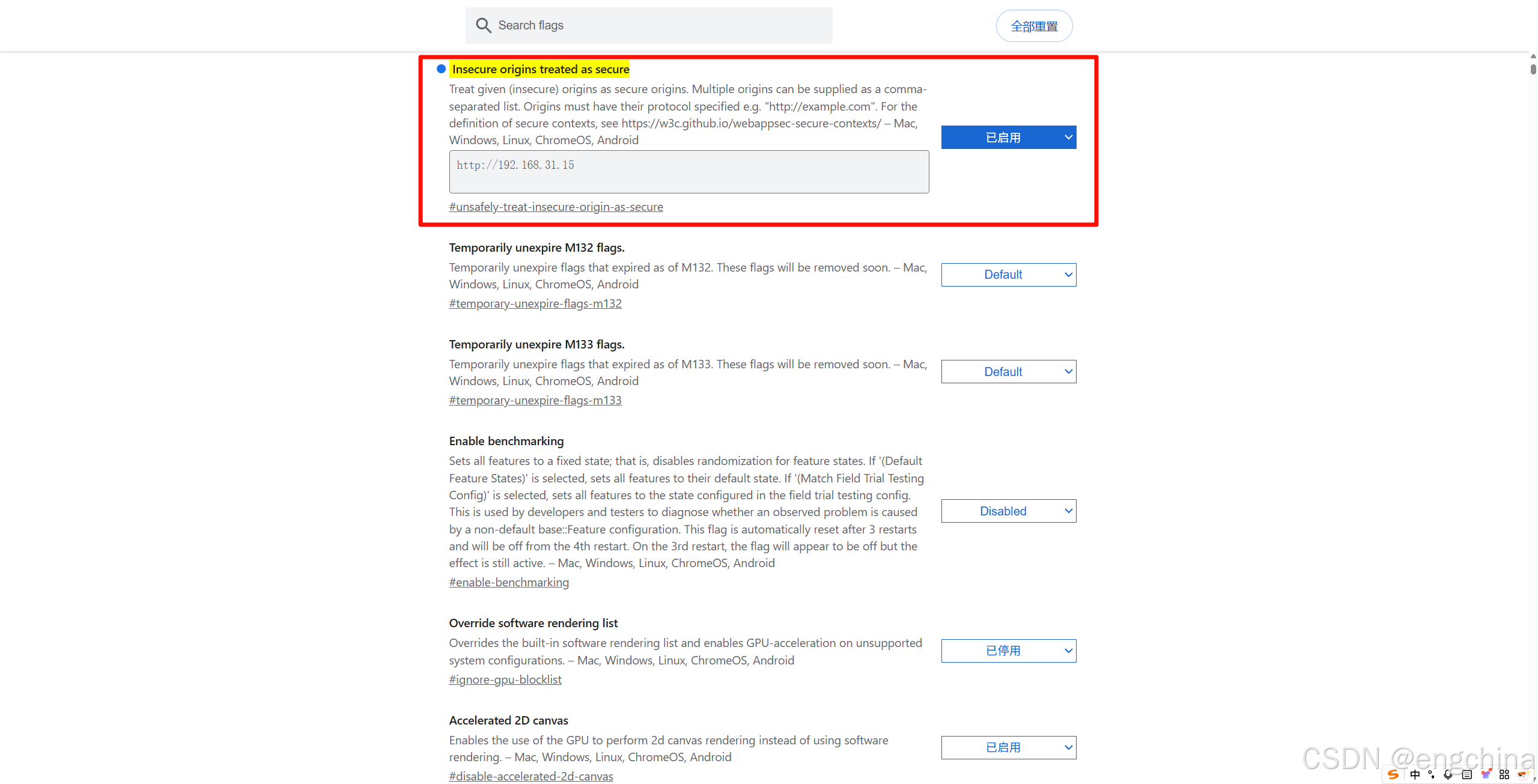
4-2. 设置 Insecure origins treated as secure
使用浏览器打开下面链接,
chrome://flags/#unsafely-treat-insecure-origin-as-secure
参考下面截图进行设置,
完结!
参考文章:


















 1719
1719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









