







递归
-
一般来说,递归的执行效率很低,实际应用中能不用就不要用。
-
递归一般是由基本项和归纳项组成。
基本项:描述了递归过程的一个或几个终结状态(不需要再继续递归而可直接求解的状态)。实际应用中的递归过程必定要经过有限的递归层次到达终结状态。
归纳项:描述如何从当前状态到终结状态的转化。 -
递归的实质:一个复杂的问题可以分解为若干子问题来处理;其中的某些子问题与原问题有着相同的特征属性;那么就可以运用与原问题相同的分析处理方法。
以汉诺塔为例,原问题是将n个圆盘从x塔座移动到z塔座,可以分解成三个子问题:
1、将编号为1至n-1的n-1个圆盘从x塔座移动到y塔座;
2、将编号为n的圆盘从x塔座移动到z塔座;
3、将编号为1至n-1的n-1个圆盘从y塔座移动到z塔座;
子问题1和3均与原问题具有相同属性,由此实现了递归。 -
代码实例1 :梵塔的递归函数
// 将 n 个盘从 x轴 搬到 z轴,y轴 用作过渡。
void hanoi(int n, char x, char y, char z)
{
if(n == 1)
{
move(x, 1, z);
}
else
{
hanoi(n-1, x, z, y);
move(x, n, z);
hanoi(n-1, y, x, z);
}
}
- 代码示例2 :二叉树的先序遍历
void PreOrderTraverse(BiTree T, void (Visit)(BiTree P)) // T总有空的时候
{
if(T)
{
Visit(T->data);
PreOrderTraverse(T->lchild, Visit);
PreOrderTraverse(T->rchild, Visit);
}
}
- 删除一个单链表中值为
x的元素
1、递推法(略)
2、递归法
void delete(LinkList &L, ElemType x) // 注意第一个引用参数
{
// L 为无头结点的单链表的指针
if(L)
{
if(L->data == x)
{
p = L;
L = L->next;
free(p);
delete(L, x);
}
else
{
delete(L->next, x);
}
}
}
递归函数的几个特性
- 1、递归函数可读性较好,另外不要强行追求的递归,在利用分割求解设计算法时,子问题和原问题的性质相同,自然导致递归求解。
- 2、实现递归函数,必须利用栈:一个递归函数必定能改写成为利用栈实现的非递归函数,反之一个用栈实现的非递归函数可以改写为递归函数。递归层次的深度决定所学存储量的大小。
- 3、分析递归算法的工具是递归树,从递归树上可以得到递归函数的各种信息,例如递归树的深度即为递归函数的递归深度,递归树上的结点数目洽为函数中的主要操作重复进行的次数。若递归树是单支树或者递归树中含有很多相同的结点,则表明该递归函数不适用。
// 将 n 个盘从 x轴 搬到 z轴,y轴 用作过渡。
void hanoi(int n, char x, char y, char z)
{
if(n == 1)
{
move(x, 1, z);
}
else
{
hanoi(n-1, x, z, y);
move(x, n, z);
hanoi(n-1, y, x, z);
}
}

如下就是上述代码的递归树,递归执行的过程 就是 中序遍历 的过程,递归树的结点数目是 7,所以移动盘共 7 次,;递归深度为 3。
若递归树蜕化为单支树或者递归树中含有很多相同的结点,则说明递归函数不适用:
如 n! = n * (n-1)! …
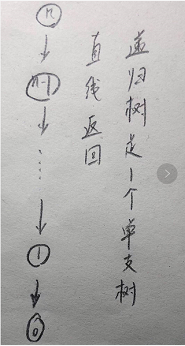
单支树的递归深度很深,所需要的存储空间蛮大的。
再如斐波那契数列,递归树如下:

可以看到图中有很多重复的结点,使用递推更合适。
递归是从上到下,递推是从下到上。
- 4、递归函数中的尾递归
在传统的递归中,典型的模型是** 首先执行递归调用,然后获取递归调用的返回值并计算结果。以这种方式,在每次递归调用返回之前,您不会得到计算结果。传统的递归过程就是函数调用,涉及返回地址、函数参数、寄存器值等压栈(在x86-64上通常用寄存器保存函数参数)
尾递归:若函数在尾位置调用自身(或是一个尾调用本身的其他函数等等),则称这种情况为尾递归。当编译器检测到一个函数调用是尾递归的时候,它就 覆盖当前的活动记录 而不是 在栈中去创建一个新的。编译器可以做到这点,因为递归调用是当前活跃期内最后一条待执行的语句,于是当这个调用返回时栈帧中并没有其他事情可做,因此也就没有保存栈帧的必要了。通过 覆盖当前的栈帧 而不是在其之上重新添加一个,这样所使用的栈空间就大大缩减了,这使得实际的运行效率会变得更高。
传统模式的编译器对于尾调用的处理方式就像处理其他普通函数调用一样,总会在调用时创建一个新的栈帧(stack frame)并将其推入调用栈顶部,用于表示该次函数调用。
当一个函数调用发生时,电脑必须 “记住” 调用函数的位置 ——返回位置,才可以在调用结束时带着返回值回到该位置,返回位置一般存在调用栈上。在尾调用这种特殊情形中,电脑理论上可以不需要记住尾调用的位置而从被调用的函数直接带着返回值返回调用函数的返回位置(相当于直接连续返回两次)。尾调用消除即是在不改变当前调用栈(也不添加新的返回位置)的情况下跳到新函数的一种优化(完全不改变调用栈是不可能的,还是需要校正调用栈上形式参数与局部变量的信息。)
由于当前函数帧上包含局部变量等等大部分的东西都不需要了,当前的函数帧经过适当的更动以后可以直接当作被尾调用的函数的帧使用,然后程序即可以跳到被尾调用的函数。产生这种函数帧变动代码与 “jump”(而不是一般常规函数调用的代码)的过程称作尾调用消除 或 尾调用优化。尾调用优化让位于尾位置的函数调用跟goto 语句性能一样高,也因此使得高效的结构编程成为现实。
对于C++等语言来说,在函数最后return g(x);并不一定是尾递归**——在返回之前很可能涉及到对象的析构函数,使得 g(x) 不是最后执行的那个。这可以通过返回值优化来解决。
如先序遍历二叉树:
void PreOrderTraverse(BiTree T)
{
while(T)
{
Visit(T->data);
PreOrderTraverse(T->lchild);
PreOrderTraverse(T->rchild);
}
}
上述代码是个 尾递归,可以改写消除尾递归:
void PreOrderTraverse(BiTree T)
{
while(T)
{
Visit(T->data);//访问根结点
PreOrderTraverse(T->lchild);//访问左子树
T = T->rchild;
}
}
- 5、可以用
递归方程来表述递归函数的时间性能。例如:
例如:假设解 n 个圆盘的梵塔的执行时间为 T(n)
则递归方程:T(n) = 2*T(n-1) + C
初始条件为:T(0) = 0
void hanoi(int n, char x, char y, char z)
{
if(n == 1)
{
move(x, 1, z);
}
else
{
hanoi(n-1, x, z, y);
move(x, n, z);
hanoi(n-1, y, x, z);
}
}
- 广义表从结构上可以分解成
1、表头 + 表尾
2、子表1 + 子表2 + … + 子表n
求广义表的深度
- 广义表的深度:广义表中括号的重数。
广义表深度 = Max {子表的深度} + 1
原子深度是0,空表深度是1 - 求法:LS = ( a1, a2, … , an )。
ai 可以是原子,也可以是LS的子表。
求LS深度可以分解为n个子问题,每个子问题求 ai 的深度。若 ai 是原子,则深度为0;若 ai 为子表(广义表),那么就和上述一样处理。
空表也是广义表,深度为1。 - 求深度的递归定义
LS = ( a1, a2, … , an )
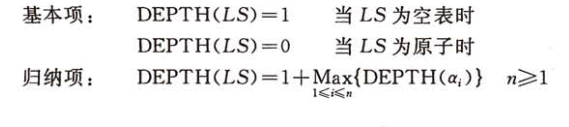
- 代码实现
采用链表法存储结构,如下:
typedef enum
{
ATOM, // 0,表示原子
LIST // 1,表示列表
} ElemTag;
typedef struct GLNode
{
ElemType tag; // 公共部分,用于区分原子结点和表结点
union
{
AtomType atom; // 原子结点的值域
struct GLNode *hp; // 表结点的表头指针
};
struct GLNode *tp; //相当于与线性链表的next,指向下一个结点
} *GList;
int GListDepth(GList L)
{
//广义表采用的是头尾链表结构
if(!L)
{
// 空表深度为1
return 1;
}
if(L->tag == ATOM)
{
// 原子深度为 0
return 0;
}
for(max=0,pp=L; pp; pp=pp->ptr.tp)
{
dep = GListDepth(pp->ptr.hp);
if(dep > max)
{
max = dep;
}
}
// 非空表的深度是个元素深度最大值再加上1
return max+1;
}

复制广义表
-
任何一个非空的广义表均可以分解为表头和表尾,
因此广义表的复制可以分解为 表头的复制 与 表尾的复制。
只要建立与原表中每一个结点一一都对应的新结点,即可。 -
复制广义表的递归定义
LS是原表,NEWLS是复制表。
| 基本项1 | 建立空表结点 |
| 基本项2 | 建立原子结点 |
| 归纳项 | 建立表中表结点 |
- 代码实现
采用头尾链表结构
typedef enum
{
ATOM, // 0,表示原子
LIST // 1,表示子表
}ElemTag;
typedef struct GLNode
{
ElemTag tag; //公共部分,用于区分原子节点和表结点
union //根据 tag 二选一
{ //要么是原子节点的值域,要么是表结点的头尾节点指针域
AtomType atom;
struct { struct GLNode *hp, *tp } ptr;
};
} *GList //广义表类型
Status CopyGList(GList T, GList L)
{
//采用头尾存储结构,表 = 表头 + 表尾
// L ---> T
if(!L)
{
// 基本项1:复制空表
T = NULL;
}
else
{
// 只要是非空表,必然存在表结点占用空间
if(!(T = (GList)malloc(sizeof(GLNode))))
{
exit(OVERFLOW);
}
T->tag = L->tag;
if(L->tag == ATOM)
{
// 基本项2:建立原子结点
T->atom = L->atom;
}
else
{
// 递归项
CopyGlist(L->ptr.hp, T->ptr.hp);
CopyGlist(L->ptr.tp, T->ptr.tp);
}
}
return OK;
}















 4429
4429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









