









之前的文章对于对抗样本有过一个简单的介绍,除了概念、原理的部分内容之外还有一些早期的相关研究工作;在这里更加具体一些,来看一看相关顶会论文对于这一块的研究工作。
对抗样本主要分为两个级别上的:1、像素级别上的;2、单独对抗块级别上的。这里主要关注一下对抗块级别相关的研究工作。
人工智能这么火,越火越代表安全这一块的严重性,因为他的应用确实比较广而且非常贴合实际、影响性大:人脸识别、监控摄像头、自动驾驶的路标识别及恶意文档/软件等等;
对抗样本的攻防,也是一个道高一尺魔高一丈的一个不断迭代的过程,相对鲁棒的攻防基本都是不存在的,大多都是应用在一个特定的领域方向。
对于攻:大多集中在测试阶段的一个样本上的改变,不论是像素级别还是对抗块的;其实也可以在训练阶段加上对抗样本对最终模型进行扰乱。
对于防:包括训练阶段增加对抗样本提高鲁棒性;更改原网络模型结构使其可以自身鉴别对抗样本;以及在原有网络模型基础之上附加新的网络模型进行过滤筛除等等多个方向。
下面具体来看一下相关论文的研究工作:
1.‘Adversarial Patch’ ,这是谷歌于CVPR17上发表的一篇论文,是相对比较早的关于对抗快攻击方向的,其最终效果如图:
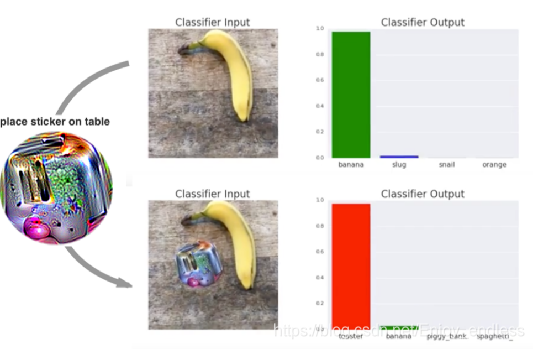
生成的这个对抗块加到原有图像上,使原有分类模型分类错误,如上原有识别为banana的概率为1,加了块之后识别为toaster的概率接近为1。
其实他的整个训练对抗快的过程也是非常简单的,仅仅是对于一个loss值得设置上,做了一个转变:

将你想要模型最终识别为一个什么效果,最为一个最终得期望,比如说原图片是一个猫,你非得想让他识别为一个狗,那么这个狗就是你的目标,就是上面公式里面得y^,使其期望最大化,将其取反作为一个loss值,进行不断地迭代回传。
下面是其核心源码部分:
adv_out = F.log_softmax(netClassifier(adv_x))
adv_out_probs, adv_out_labels = adv_out.max(1)
Loss = -adv_out[0][target]
Loss.backward()
其中adv_x是你输入的含有对抗块得对抗图像,将其过分类器及softmax输出各类别概率,然后取你想要的目标得概率并取反,最为最终得loss并回传更新你的对抗快。
2.LaVAN: Localized and Visible Adversarial Noise,这一篇是CVPR2018得一个工作,同样是生成对抗快图像攻击相关得。

如上图所示,加上对抗块之后,最终得识别效果将是由你的对抗快所决定得。
他的一个loss值设置其实也是非常简单,只不过是在第一个论文得基础之上又加了一点东西:
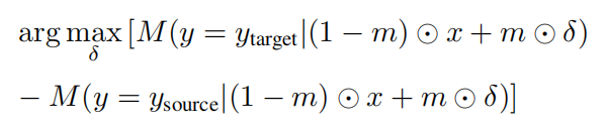
他的loss值设置是说,不仅仅要使其最终识别效果越靠近你给他得目标target越好、同时还要越远离原来的目标source越好,就是如上得loss值设置。其中m是一个简单的mask,而那个delta就表示得是对抗快。
3.‘Trojaning Attack on Neural Networks’,这是普渡大学和南大发表在NDSS2018上得一个工作,效果图如下:

其loss值设置如下:
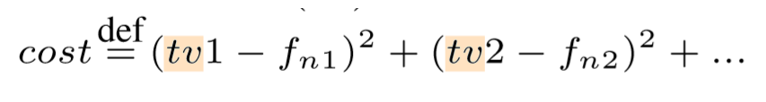
他这里是基于特征值空间做的一个工作,也就是说输入对抗图像,其模型输出特征fn1与你的目标特征tv1尽可能得相近,也是一个不断优化迭代得过程。
4.Fooling automated surveillance cameras: adversarial patches to attack person detection,这是发表在CVPR2019ws上的一个工作:

这是应用于目标检测方向上的,实际背景是说:对于监控摄像头来说,如果你拿着一个打印出来的对抗块放在身上,那me监控就发现不了你是一个人了。
如上图所示,是yolov2的一个识别效果,对于拿着图像块的那个人来说,yolov2是检测不到的。
他的整体网络流程图如下:
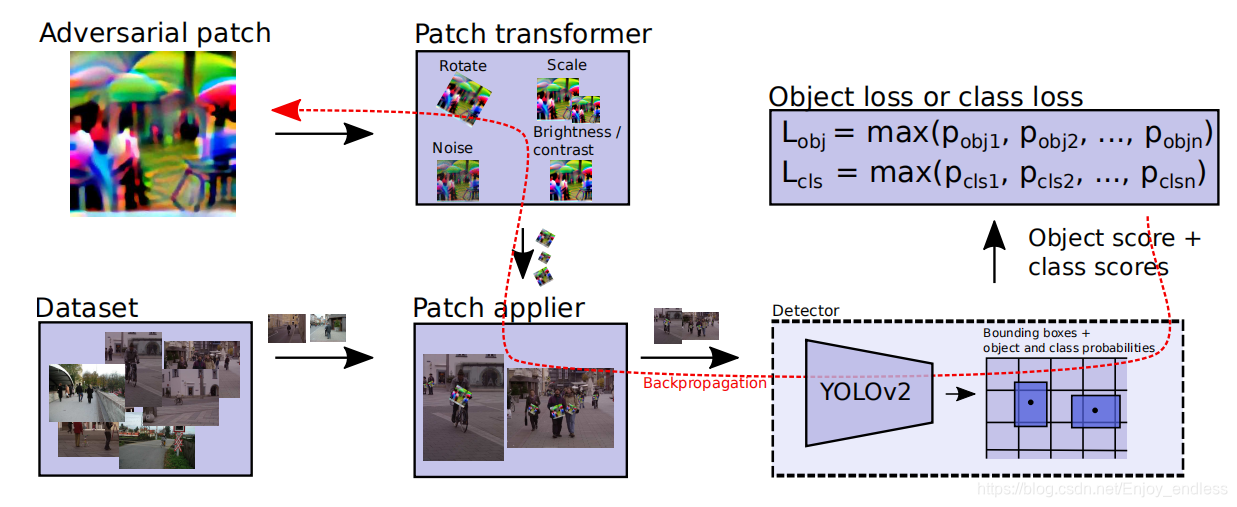
将一些数据集图像,然后在特定位置安放一些随机灰度块,在送入yolov2网络进行识别检测,网络输出目标、类别识别效果,然后将其设置为loss值进行回传更新图像块内像素,迭代几百上千轮,得到最终的对抗快。
他这里的loss值比之前的设置稍微多了几项,包括可打印设置:因为这个对抗块是可以打印出实物的,同时增加了内部平滑控制,整体loss如下:

第一个loss项就是控制可打印的,第二个loss控制图像块内更加平滑的,而第三个loss是最核心的。
目标检测的输出结果包括:目标+类别,所以作者做了几个实验,对于第三个loss值设置分别取了三种情况:只用目标、只用类别、用目标加类别,作为loss值进行回传,最终三种情况的效果图如下:

可以看到,只用目标作为第三个loss值,获得的目标效果最好。
其实他这里的思想还是很简单的,源码如下:
56 output_objectness = torch.sigmoid(output[:, 4, :]) # 置信度
57 output = output[:, 5:5 + self.num_cls , :] #
58 # perform softmax to normalize probabilities for object classes to [0,1]
59 normal_confs = torch.nn.Softmax(dim=1)(output)
60 # we only care for probabilities of the class of interest (person)
61 confs_for_class = normal_confs[:, self.cls_id, :]
62
63 confs_if_object = output_objectness #confs_for_class * output_objectness
64
65 #confs_if_object = confs_for_class * output_objectness
67
68 #在这里可以修改对应的那三种策略:最小化类别、目标、两者之和,原论文指出最小化目标效果最好
69
70 max_conf, max_conf_idx = torch.max(confs_if_object, dim=1)
71 return max_conf
最开始的output即yolov2的模型输出,取其第二维度的4即表示目标的置信度,
这里取其max既可以直接作为最终的目标损失直接返回作为第三个loss值;
下面的取output的第二个维度的5:即表示模型输出的类别值取softmax即表示每一类的类别概率,按你想要的类别概率(这里为人)进行指定self.cls_id,同样取max返回即可作为类别的最终损失loss值。
5.'ADVHAT: REAL-WORLD ADVERSARIAL ATTACK ON ARCFACE FACE ID SYSTEM ',这是今年华为新出的一个工作,也是关于对抗块贴到人脸上之后,最先进的人脸识别系统最终失效的一个工作:

如上图所示,第一个人脸识别率为0.61,而第二个图贴了块之后识别率仅有0.02,
他的loss值设置也是根据他想要的那个特定识别系统来做的:
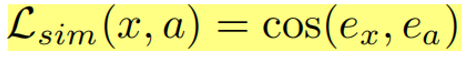
就是加上块之后的图像特征与原图像特征的相似性越低越好,也是一个迭代优化的过程,当然他还做了很多鲁棒性的工作:比如角度、光照等等;
在图像块攻击这一块,近年大家做的工作还是比较多的,而且做法大多相似,主要是loss值得更改设置。当然后期的工作还包括成本、平滑度、鲁棒性等等相关工作;这些工作,他们的问题也是非常突出的,就是迁移性,他们只是针对于特定得模型、场景等效果非常好,但是迁移性非常差。另一个就是产生的块非常突兀、这也是未来的一个方向。
当然还有其他的生成对抗块的方法,比如AAAI2019北航的一个基于gan生成对抗的方法效果也是非常不错,也是一个新的思路方法;包括像素级别的也有用gan来生成的,比如IJCAI2019的操晓春老师组的工作。
有攻就有防,犹如有尖锐的茅就有更坚固的盾,这也是不断迭代的一个过程,期望有更多、更好的工作展现出来。
非常欢迎,学习研究相关工作的、大家一起讨论交流。














 3194
3194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









