










前言
请在linux环境下开展实验,非常建议熟悉 awk, grep, sed, cut, 等shell 命令快速处理文本,以及学会使用python脚本处理数据等.
为了方便大家学习,本教程相关代码放置:https://gitee.com/ephemeroptera/aishell-1.git
一、kaldi项目的一般架构
1.1 搭建第一个asr项目
新建一个空目录(例如aishell-1),构建一个asr的项目基本结构如下:

这里我大致介绍一下每个文件的用处:
1、data 存放相关数据的文件夹,比如训练集,测试集,语言模型,发音字典等文件
2、steps: kaldi官方工具(ln -s kaldi/egs/wsj/s5/steps steps),封装了am 训练/解码 等脚本
3、utils: kaldi 官方工具 (ln -s kaldi/egs/wsj/s5/utils utils), 封装了 数据处理,lm处理 等常用脚本
4、local: 用户自定义的一些处理脚本一般放在这,比如计算词错率脚本啥的
5、conf: 存放配置文件的目录,这里面一般有 提取特征/解码 需要的配置
6、cmd.sh: 该文件定义了 训练/构图/解码 需要的硬件支持配置
7、path.sh: 该文件需要声明kaldi根目录所在位置,这样可以可以使用kaldi一些二进制命令
1.2 准备好相关配置
(1)链接 steps 和 utils
link -s $kaldi_root/egs/wsj/s5/steps steps
link -s $kaldi_root/egs/wsj/s5/utils utils
(2) 修改 path.sh ,指定 kaldi 位置
export KALDI_ROOT=/disc3/ww/kaldi-trunk #(修改此处即可)
[ -f $KALDI_ROOT/tools/env.sh ] && . $KALDI_ROOT/tools/env.sh
export PATH=$PWD/utils/:$KALDI_ROOT/tools/openfst/bin:$PWD:$PATH
[ ! -f $KALDI_ROOT/tools/config/common_path.sh ] && echo >&2 "The standard file $KALDI_ROOT/tools/config/common_path.sh is not present -> Exit!" && exit 1
. $KALDI_ROOT/tools/config/common_path.sh
export LC_ALL=C
(3)修改 cmd.sh , 设置本机运行相关参数(此处根据本机硬件自主设置)
export train_cmd="run.pl --mem 2G"
export decode_cmd="run.pl --mem 4G"
export mkgraph_cmd="run.pl --mem 8G"
export cuda_cmd="run.pl --gpu 3"
(4)定义解码/特征提取等相关配置文件(conf文件夹)
conf/decode.config
beam=11.0 # beam for decoding. Was 13.0 in the scripts.
first_beam=8.0 # beam for 1st-pass decoding in SAT.
conf/mfcc.conf
--use-energy=false # only non-default option.
--sample-frequency=16000
conf/mfcc_hires.conf
--use-energy=false # use average of log energy, not energy.
--sample-frequency=16000 # Switchboard is sampled at 8kHz
--num-mel-bins=40 # similar to Google's setup.
--num-ceps=40 # there is no dimensionality reduction.
--low-freq=40 # low cutoff frequency for mel bins
--high-freq=-200 # high cutoff frequently, relative to Nyquist of 8000 (=3800)
conf/pitch.conf
--sample-frequency=16000
设置好配置后,kaldi的相关脚本会引入path.sh, cmd.sh,conf/ 等相关文件,这样就可以调用kaldi中相关命令以及指定训练/解码的参数和配置。
---------------------------------------------------------------------------------------------------
二、准备 aishell-1 数据集
2.1 wav文件
aishell-1提供了178小时的中文含标注的语音数据(aishell-1开源中文语音数据库),读者们下载该完数据集后,解压会得到:

data_aishell/wav 存放wav的压缩文件,解压后会得到 train,dev,test 数据用于训练/开发/测试:
cd data_aishell
for file in wav/*;do
tar -xvf $file;
done
2.2 标注文件
data_aishell/transcript 存放每个wav的中文标注, 这里已经是分词后的结果,因为一般asr的输出类型都是词序列,对于未分词的原始文本可以使用例如python中jieba工具分词处理。  同时读者们也要注意到一般的语音数据集会根据说话人进行划分,例如在文件名“BAC009S0002W0140” 的文件名中,根据前几位字符我们可以提取到说话人S0002信息BAC009S0002,之所以介绍这是因为kaldi的准备文件中需要确认说话人信息,当然说话人不确认的话,可以令说话人为文件名就好
同时读者们也要注意到一般的语音数据集会根据说话人进行划分,例如在文件名“BAC009S0002W0140” 的文件名中,根据前几位字符我们可以提取到说话人S0002信息BAC009S0002,之所以介绍这是因为kaldi的准备文件中需要确认说话人信息,当然说话人不确认的话,可以令说话人为文件名就好
---------------------------------------------------------------------------------------------------
三、kladi数据准备(data/train,dev,test)
3.1 音频的唯一性
kaldi中每个音频由唯一键值(utterance)确认,其键值要保证唯一性,一般键值为音频文件名,对于数据集而言,键值需要保证其有序性。这个会在数据准备中继续说明。
3.2 标准kaldi数据结构
在训练/解码中:
有三个文件是必要的:
(1) wav.scp
(2) utt2spk
(3) spk2utt
一个标注文件用于测试的:
(4) text
---------------------------------- 现在依次说明 (例子:data/train)--------------------------------------------
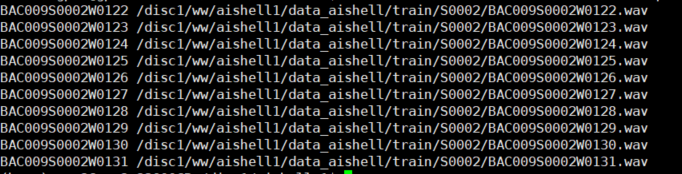
(1) wav.scp
用处:指定音频路径
结构: [utterance] [wav_path]
样例:
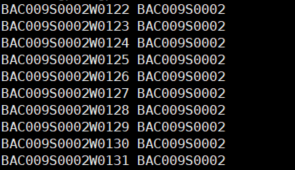
(2) utt2spk
用处: 音频对应说话人信息
结构: [utterance] [speaker]
样例:
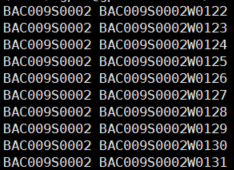
(3) spk2utt
用处: 说话人对应音频信息
结构: [speaker] [utterance]
样例:
(4) text
用处: 音频标注
结构: [utterance] [transcript]
样例:

3.3 脚本实现
以 data/train 为例,通过脚本来实现生成这些文件
src_train=/disc1/ww/aishell1/data_aishell/train/
src_trans=/disc1/ww/aishell1/data_aishell/transcript/aishell_transcript_v0.8.txt
train=data/train
# wav.scp (用户脚本)
bash local/search.sh $src_train wav scp | sort | uniq > $train/wav.scp
# utt2spk and spk2utt (用户脚本)
bash local/utt-spk.sh $train/wav.scp 1 11 $train
# text (官方脚本)
perl utils/filter_scp.pl $train/wav.scp $src_trans > $train/text
# checking and fixing (官方脚本)
utils/fix_data_dir.sh $train
---------------------------------------------------------------------------------------------------
四、提取音频特征(MFCC)
这里我们将对训练/验证/测试集提取最常使用的mfcc特征,此外添加3维的音高特征(pitch),之后再做归一化处理。
4.1 提取低维mfcc特征(13+3维,面向gmm-hmm)
train=data/train
train_sp=data/train_sp
train_sp_hires=data/train_sp_hires
dev=data/dev
dev_hires=data/dev_hires
test=data/test
test_hires=data/test_hire
# usage:
# steps/make_mfcc_pitch.sh --nj $nj <data> <log> <feats>
steps/make_mfcc_pitch.sh --nj 20 $train exp/make_mfcc/train mfcc/train
steps/make_mfcc_pitch.sh --nj 20 $dev exp/make_mfcc/dev mfcc/dev
steps/make_mfcc_pitch.sh --nj 20 $test exp/make_mfcc/test mfcc/test
steps/compute_cmvn_stats.sh $train exp/make_mfcc/train mfcc/train
steps/compute_cmvn_stats.sh $dev exp/make_mfcc/dev mfcc/dev
steps/compute_cmvn_stats.sh $test exp/make_mfcc/test mfcc/test
4.2 数据增广
此步骤用于gmm-hmm对齐生成用于训练dnn-hmm的label,提取特征之前采用音速扰动做一次3倍增广
utils/data/perturb_data_dir_speed_3way.sh $train $train_sp
steps/make_mfcc_pitch.sh --nj 20 $train_sp exp/make_mfcc/train_sp mfcc/train_sp
steps/compute_cmvn_stats.sh $train_sp exp/make_mfcc/train_sp mfcc/train_sp
4.2 提取高维mfcc特征(40+3维,面向dnn-hmm)
utils/copy_data_dir.sh $train_sp $train_sp_hires
utils/copy_data_dir.sh $dev $dev_hires
utils/copy_data_dir.sh $test $test_hires
utils/data/perturb_data_dir_volume.sh $train_sp_hires
steps/make_mfcc_pitch.sh --nj 30 --mfcc-config conf/mfcc_hires.conf $train_sp_hires exp/make_hires/train_sp mfcc_hires/train_sp
steps/make_mfcc_pitch.sh --nj 10 --mfcc-config conf/mfcc_hires.conf $dev_hires exp/make_hires/dev mfcc_hires/dev
steps/make_mfcc_pitch.sh --nj 10 --mfcc-config conf/mfcc_hires.conf $test_hires exp/make_hires/test mfcc_hires/test
---------------------------------------------------------------------------------------------------
五、声学模型单元 (data/local/dict)
5.1 音素和发音词典
在训练声学模型的前期,我们需要定义好声学模型的一些基本结构,主要就是 建模单元(音素) 的定义,音素的选择取决于发音词典,这里aishell也提供了中文发音词典:
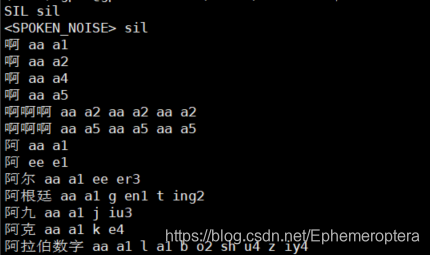
该词典使用的音素类似声韵母的结构,其中对于静音和噪声统一采用 sil 单元表征。
5.2 定义建模单元
这里我们根据发音词典来定义我们的声学单元,在kaidi中对声学单元的表述需要以下四个文件:
data/local/dict:

其中简单介绍如下:
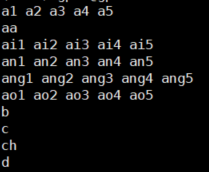
(1) nonsilence_phones.txt
意义:非静音音素集
样例:
(2) silence_phones.txt
意义:静音音素集
样例:

(3) optional_silence.txt
意义:指定静音音素集
样例:
(3) extra_questions.txt
意义:用于三音素聚类问题
样例:

5.3 集外词 (噪声) 建模
对于集外词(噪声)的建模单元,我们将 _SIL 表示为silence语音,用unknown符号 表示集外未知词,发音如下:
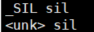
5.4 脚本实现
dict=data/local/dict
# nonsilence_phones.txt
cat $src_lexicon | awk '{ for(n=2;n<=NF;n++){ phones[$n] = 1; }} END{for (p in phones) print p;}'| \
perl -e 'while(<>){ chomp($_); $phone = $_; next if ($phone eq "sil");
m:^([^\d]+)(\d*)$: || die "Bad phone $_"; $q{$1} .= "$phone "; }
foreach $l (values %q) {print "$l\n";}
' | sort -k1 > $dict/nonsilence_phones.txt || exit 1;
# silence_phones.txt
echo sil > $dict/silence_phones.txt
# optional_silence.txt
echo sil > $dict/optional_silence.txt
# extra_questions.txt
cat $dict/silence_phones.txt| awk '{printf("%s ", $1);} END{printf "\n";}' > $dict/extra_questions.txt || exit 1;
cat $dict/nonsilence_phones.txt | perl -e 'while(<>){ foreach $p (split(" ", $_)) {
$p =~ m:^([^\d]+)(\d*)$: || die "Bad phone $_"; $q{$2} .= "$p "; } } foreach $l (values %q) {print "$l\n";}' \
>> $dict/extra_questions.txt || exit 1;
# defing sil & spn
mkdir -p local/dict
echo "_SIL sil
<unk> sil" > local/dict/sil-spn
5.5 dict/lang目录准备
上面我们我们定义好声学单元之后,对于不同的任务我们需要生成不同的dict/lang目录,以某个任务task为例:
(1) dict_{task}
在dict_{task}中,首先拷贝关于声学单元的定义:
<nonsilence_phones.txt>
<silence_phones.txt>
<optional_silence.txt>
<extra_questions.txt>
cp $dict/{nonsilence_phones.txt,silence_phones.txt,optional_silence.txt,extra_questions.txt} dict_{task}/
然后添加发音词典,使用G2P工具(参考六)给出词表发音:
bash local/seq2seq-g2p/g2p_decode.sh 0 $g2p_model $dict_train/words.txt dict_{task}//words.g2p 1
cat local/dict/sil-spn $dict_train/words.g2p > $dict_train/lexicon.txt
(2)lang_{task}
制作lang目录可以理解为将dict内容转化为 fst 形式,fst 参与模型训练 或者 解码网络构建。
lexicon.txt --> L.fst
arpa(ngram语言模型) --> G.fst
utils/prepare_lang.sh dict_{task} "<unk>" lang_task_tmp lang_task
utils/prepare_lang.sh lang_task "<unk>" lang_task_tmp lang_task
# 或者 arpa2fst --disambig-symbol=#0 --read-symbol-table=lang_{task}/words.txt <arpa> lang_{task}/G.fst
---------------------------------------------------------------------------------------------------
六、任意单词发音(exp/g2p)
6.1 集外词(oov)发音和G2P
在基于HMM的语音识别框架中,发音词典将音素级HMM复合成单词级HMM,因此在训练/解码过程中,标注或者语言模型中可能包含大量集外词(out of vocabulary),但是aishell提供的种子词典由专家标注,收纳闭集中有限中文单词发音,对于集外词,我们希望能够学习种子词典的发音规律,给出oov发音。
在ASR中,一般用于学习发音规律的模型称作G2P模型(grapheme-to-phoneme),是字素到音素的预测模型。这里我才用了CMU大学开发的基于seq2seq的G2P工具,并封装了训练/解码脚本
bash g2p_train.sh <cuda_device> <model_dir> <train_file> <test_file> [epochs]
bash g2p_decode.sh <cuda_device> <model> <vocab_file> <decode_file> [ppw]
6.2 脚本实现
cat $src_lexicon | awk 'NR>2' > $g2p_dir/corpus.txt
cat data/local/g2p/ch/corpus.txt | shuf -n 100 > $g2p_dir/g2p.test
cat data/local/g2p/ch/corpus.txt | grep -v -f g2p.test > $g2p_dir/g2p.train
bash local/seq2seq-g2p/g2p_train.sh 0 $g2p_model $g2p_dir/g2p.train $g2p_dir/g2p.test 0
---------------------------------------------------------------------------------------------------
七、训练GMM-HMM
7.1 dict/lang 准备
这里我们将统计训练集data/train/text 中全部单词,并应用g2p模型给出单词发音,再生成训练专用dict/lang目录
cp $dict/{nonsilence_phones.txt,silence_phones.txt,optional_silence.txt,extra_questions.txt} $dict_train/
cat $train/text | awk '{for (n=2;n<=NF;n++) counts[$n]++;} END{for (w in counts) printf "%s\n",w;}' > $dict_train/words.txt
bash local/seq2seq-g2p/g2p_decode.sh 0 $g2p_model $dict_train/words.txt $dict_train/words.g2p 1
cat local/dict/sil-spn $dict_train/words.g2p > $dict_train/lexicon.txt
utils/prepare_lang.sh $dict_train "<unk>" $lang_train_tmp $lang_train
7.2 训练GMM-HMM
这里的训练步骤为:
单音素 --> 三音素 --> 三音素 --> lda+mllt --> sat --> sat
nj=40
# mono
steps/train_mono.sh --nj $nj --cmd "$train_cmd" $train $lang_train exp/mono
steps/align_si.sh --nj $nj --cmd "$train_cmd" $train $lang_train exp/mono exp/mono_ali
# tri1
steps/train_deltas.sh --cmd "$train_cmd" 2500 10000 $train $lang_train exp/mono_ali exp/tri1
steps/align_si.sh --nj $nj --cmd "$train_cmd" $train $lang_train exp/tri1 exp/tri1_ali
# tri2
steps/train_deltas.sh --cmd "$train_cmd" 2500 20000 $train $lang_train exp/tri1_ali exp/tri2
steps/align_si.sh --nj $nj --cmd "$train_cmd" $train $lang_train exp/tri2 exp/tri2_ali
# tri3a
steps/train_lda_mllt.sh --cmd "$train_cmd" 2500 20000 $train $lang_train exp/tri2_ali exp/tri3a
steps/align_fmllr.sh --nj $nj --cmd "$train_cmd" $train $lang_train exp/tri3a exp/tri3a_ali
# tri4a
steps/train_sat.sh --cmd "$train_cmd" 2500 20000 $train $lang_train exp/tri3a_ali exp/tri4a
steps/align_fmllr.sh --nj $nj --cmd "$train_cmd" $train $lang_train exp/tri4a exp/tri4a_ali
# tri5a
steps/train_sat.sh --cmd "$train_cmd" 4000 100000 $train $lang_train exp/tri4a_ali exp/tri5a
最后训练得到的声学模型为exp/tri5a/final.mdl
---------------------------------------------------------------------------------------------------
八、制作 n-gram 语言模型 (*)
8.1 训练 n-gram 语言模型
这里采用srilm工具训练n-gram语言模型,训练语料来自训练集标注,训练得到语言模型为arpa文件。
SRILM=/disc3/ww/kaldi-trunk/tools/srilm
export PATH=$SRILM/bin:$SRILM/bin/i686-m64:$PATH
lm_dir=data/local/lm
order=3
cat $train/text | cut -d" " -f2- > $lm_dir/corpus.txt
ngram-count -order $order -write-vocab $lm_dir/vocabs.txt -wbdiscount -text $lm_dir/corpus.txt -lm $lm_dir/aishell-1.${order}gram
8.3 dict/lang 准备
cp $dict/{nonsilence_phones.txt,silence_phones.txt,optional_silence.txt,extra_questions.txt} $dict_lm/
bash local/seq2seq-g2p/g2p_decode.sh 0 $g2p_model $lm_dir/vocabs.txt $dict_lm/ 1
cat local/dict/sil-spn $dict_train/words.g2p > $dict_lm/lexicon.txt > dict_lm/lexicon.txt
utils/prepare_lang.sh $dict_lm "<unk>" $lang_lm_tmp $lang_lm
8.3 arpa to fst
语言模型参与构建asr解码网络之前需要将其转换为G.fst
arpa2fst --disambig-symbol=#0 --read-symbol-table=$lang_lm/words.txt $lm_dir/aishell-1.${order}gram $lang_lm/G.fst
fstisstochastic $lang_lm/G.fst
8.4 构建解码网络(初步的asr系统)
这里我们将语言模型和gmm-hmm构建解码网络,该步骤可以得到一个初步的gmm-hmm的asr系统。kaldi中的解码网络叫做graph.
utils/mkgraph.sh $lang_lm exp/tri5a exp/tri5a/graph
8.5 asr系统测试
这里我们将给出dev/test的测试(解码)结果,基于gmm-hmm的asr的解码脚本位于
steps/decode.sh (说话人无关特征)
steps/decode_fmllr.sh (说话人相关特征)
steps/decode.sh --skip_scoring=false exp/tri5a/graph $dev exp/tri5a/graph/decode_dev
steps/decode_fmllr.sh --skip_scoring=false exp/tri5a/graph $test exp/tri5a/graph/decode_test
其中 参数–skip_scoring 表示是否执行评优脚本(local/score.sh)。通过解码我们可以得到测试集的lattice压缩文件。
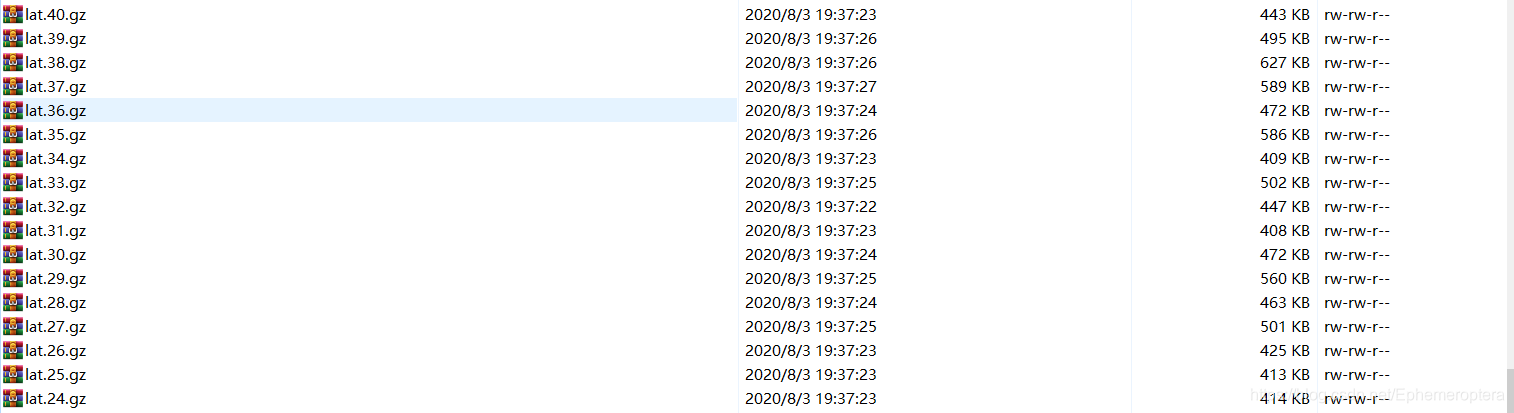
lattice是保存测试语音的部分预测结果的文件形式,通过声学权重(acwt)和语言权重(lmwt)我们可以得到最佳或者n-best语音转写结果。
以最佳结果为例:
symtab=$graph/words.txt
utils/run.pl $decode/decode.log \
lattice-scale --inv-acoustic-scale=$lmwt "ark:gunzip -c $decode/lat.*.gz|" ark:- \| \
lattice-add-penalty --word-ins-penalty=$wip ark:- ark:- \| \
lattice-best-path --word-symbol-table=$symtab ark:- ark,t:- \| \
utils/int2sym.pl -f 2- $symtab '>' $decode/decode.result
此外评优脚本local/score.sh 是参数寻优脚本,可以得到最佳的acwt, lmwt, wip(插入惩罚权重)。
---------------------------------------------------------------------------------------------------
九、训练DNN-HMM
9.1 chain 模型
chain模型是目前最主流的声学模型架构,简单介绍如下:
神经网络:时延神经网络(TDNN)
训练方式:lattice-free (序列鉴别训练)
有关chain模型请参考:
MMI在ASR中的应用
声学模型学习笔记(五) SDT(MMI/BMMI/MPE/sMBR)
语音识别-TDNN
区分性训练和mmi(一)
kaldi中的chain model(LFMMI)详解
具体训练方法请查阅lattice-free论文,本文训练代码参考aishell官方demo(local/chain/run_tdnn.sh)
9.2 GMM-HMM对齐提供标注
steps/align_fmllr.sh --nj 40 --cmd "$train_cmd" $train_sp $lang_train exp/tri5a exp/train_sp_ali
9.3 lattice-free 训练
main=exp/chain
lang_chain=$main/lang
lats=$main/lats
tree=$main/tree
nnet=$main/nnet
(1)Get the alignments as lattice (gives the LF-MMI training more freedom)
steps/align_fmllr_lats.sh --nj $nj --cmd "$train_cmd" $train_sp $lang_train $gmm $lats
(2)Create a version of the lang/ directory that has one state per phone in the topo file. [note, it really has two states… the first one is only repeated once, the second one has zero or more repeats.]
cp -r $lang_train $lang_chain
silphonelist=$(cat $lang_chain/phones/silence.csl) || exit 1;
nonsilphonelist=$(cat $lang_chain/phones/nonsilence.csl) || exit 1;
Use our special topology… note that later on may have to tune this topology.
steps/nnet3/chain/gen_topo.py $nonsilphonelist $silphonelist > $lang_chain/topo
(3)Build a tree using our new topology. This is the critically different step compared with other recipes.
steps/nnet3/chain/build_tree.sh --frame-subsampling-factor 3 \
--context-opts "--context-width=2 --central-position=1" \
--cmd "$train_cmd" 5000 $train_sp $lang_chain $ali $tree
(4)定义神经网络结构
num_targets=$(tree-info $tree/tree |grep num-pdfs|awk '{print $2}')
learning_rate_factor=$(echo "print (0.5/$xent_regularize)" | python)
mkdir -p $nnet/configs
cat <<EOF > $nnet/configs/network.xconfig
input dim=43 name=input
fixed-affine-layer name=lda input=Append(-1,0,1) affine-transform-file=$nnet/configs/lda.mat
relu-batchnorm-layer name=tdnn1 dim=625
relu-batchnorm-layer name=tdnn2 input=Append(-1,0,1) dim=625
relu-batchnorm-layer name=tdnn3 input=Append(-1,0,1) dim=625
relu-batchnorm-layer name=tdnn4 input=Append(-3,0,3) dim=625
relu-batchnorm-layer name=tdnn5 input=Append(-3,0,3) dim=625
relu-batchnorm-layer name=tdnn6 input=Append(-3,0,3) dim=625
relu-batchnorm-layer name=prefinal-chain input=tdnn6 dim=625 target-rms=0.5
output-layer name=output include-log-softmax=false dim=$num_targets max-change=1.5
relu-batchnorm-layer name=prefinal-xent input=tdnn6 dim=625 target-rms=0.5
output-layer name=output-xent dim=$num_targets learning-rate-factor=$learning_rate_factor max-change=1.5
EOF
steps/nnet3/xconfig_to_configs.py --xconfig-file $nnet/configs/network.xconfig --config-dir $nnet/configs/
(5)训练模型
steps/nnet3/chain/train.py --stage $train_stage \
--cmd "$decode_cmd" \
--feat.cmvn-opts "--norm-means=false --norm-vars=false" \
--chain.xent-regularize $xent_regularize \
--chain.leaky-hmm-coefficient 0.1 \
--chain.l2-regularize 0.00005 \
--chain.apply-deriv-weights false \
--chain.lm-opts="--num-extra-lm-states=2000" \
--egs.dir "$egs" \
--egs.stage $get_egs_stage \
--egs.opts "--frames-overlap-per-eg 0" \
--egs.chunk-width $frames_per_eg \
--trainer.num-chunk-per-minibatch $minibatch_size \
--trainer.frames-per-iter 1500000 \
--trainer.num-epochs $num_epochs \
--trainer.optimization.num-jobs-initial $num_jobs_initial \
--trainer.optimization.num-jobs-final $num_jobs_final \
--trainer.optimization.initial-effective-lrate $initial_effective_lrate \
--trainer.optimization.final-effective-lrate $final_effective_lrate \
--trainer.max-param-change $max_param_change \
--cleanup.remove-egs $remove_egs \
--feat-dir $train_sp_hires \
--tree-dir $tree \
--lat-dir $lats \
--dir $nnet || exit 1;

四张1080ti显卡大约耗时4小时训练时间,训练得到声学模型为:exp/chain/nnet/final.mdl
9.4 构建解码网络
这里我们将chain模型和语言模型复合得到解码网络
utils/mkgraph.sh --self-loop-scale 1.0 $lang_lm $nnet $graph
9.5 解码
steps/nnet3/decode.sh --acwt 1.0 --post-decode-acwt 10.0 --nj 20 --cmd "$decode_cmd" $graph $dev_hires $nnet/decode_dev
steps/nnet3/decode.sh --acwt 1.0 --post-decode-acwt 10.0 --nj 20 --cmd "$decode_cmd" $graph $test_hires $nnet/decode_test
十、结果评价
至此,你已经完成了一个中文asr的搭建,这里我给出本次实验中GMM-TDNN 和 chain 声学模型的结果,识别标准采用字错率(CER)。
LM: 由aishell-1标注文本训练得到的3gram语言模型
AM:
(1) GMM-HMM (说话人无关)
dev: 14.05% (exp/tri5a/decode_dev.si/scoring_kaldi/best_wer)
test: 16.60% (exp/tri5a/decode_test.si/scoring_kaldi/best_wer)
(2) GMM-HMM (说话人相关)
dev:11.11% (exp/tri5a/decode_dev/scoring_kaldi/best_wer)
test: 12.80% (exp/tri5a/decode_test.si/scoring_kaldi/best_wer)
(3) chain 模型
dev:7.66% (exp/chain/nnet/decode_dev/scoring_kaldi/best_wer)
test: 9.19% (exp/tri5a/decode_test.si/scoring_kaldi/best_wer)
从结果来看,基于DNN-HMM框架 的识别效果还是要大大优于 GMM-HMM 框架识别。















 3489
3489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











