






知乎博客:yolov5代码解读-训练 - 知乎
前面跳过,到Config
加载图像路径和类别信息
#Config
plots = not evolve # create plots(创建图) evolve-----evolve hyperparameters for x generations
#为x个generations进化超参数
cuda = device.type != 'cpu'
init_seeds(1 + RANK) #这里RANK到底是什么东西
with torch_distributed_zero_first(LOCAL_RANK): # 这也看不懂
data_dict = data_dict or check_dataset(data) # check if None
train_path, val_path = data_dict['train'], data_dict['val']
nc = 1 if single_cls else int(data_dict['nc']) # number of classes
names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check
is_coco =data.endswith('coco.yaml') and nc == 80 #COCO dataset这一段是先设置了随机种子,然后记载data.yaml数据,读进来训练图像和测试图像的地址。在数据处理部分已经说过了,标签的地址是根据图像的地址替换掉‘imges’为'labels'得到的。所以这里只需要度图像地址就可以了。
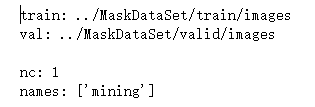
这面这个就是data.yaml中的数据。
torch_distributed_zero_first函数解读(utils/torch_utils.py)
pytorch在分布式训练过程中,对于数据的读取是采用主进程预读取并缓存,然后其它进程从缓存中读取,不同进程之间的数据同步具体通过torch.distributed.barrier()实现。
def torch_distributed_zero_first(local_rank: int):
"""
Decorator to make all processes in distributed training wait for each local_master to do something.
这个Decorator(装饰器)是让分布式训练中所有等待local_master的进程做点什么
"""
if local_rank not in [-1, 0]:
dist.barrier(device_ids=[local_rank])
yield
if local_rank == 0:
dist.barrier(device_ids=[0])torch_distributed_zero_first是在create_dataloader函数中调用的,如果执行create_dataloader()函数的进程不是主进程,即rank不等于0或者-1,上下文管理器会执行相应的torch.distributed.barrier(),设置一个阻塞栅栏,让此进程处于等待状态,等待所有进程到达栅栏处(包括主进程数据处理完毕);
如果执行create_dataloader()函数的进程是主进程,其会直接去读取数据并处理,然后其处理结束之后会接着遇到torch.distributed.barrier(),此时,所有进程都到达了当前的栅栏处,这样所有进程就达到了同步,并同时得到释放。
加载模型
之后就是加载模型了。一般都是需要用预训练模型的,如果没有预训练权重,就从之前解读的Model哪里创建一个新的model。如果有预训练权重,就加载一下。
# Model
check_suffix(weights, '.pt') # check weights
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location=device) # load checkpoint(加载检查点)
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) #create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys(排除keys)
#上面这三行没看懂要干嘛,大概知道一点而已
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32 这里什么意思又没看懂
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # 这里把csd又重写了,还是没看懂
model.load_state_dict(csd, strict=False) # load 什么是state_dict
LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
else :
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) #create
迁移学习
这一部分是做迁移学习的,也就是当数据量的时候,尝试冻住前面一些层,让他们不再更新了。但是据说没有必要。但是这段代码还是可以看看的,k是索引,v是具体的参数。如果确定freeze中的层数,有在k中的,或者说,k有在freeze中的,那么就把这层相关的v冻结,不再进行梯度下降和参数更新。
# Freeze
freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
print(f'freezing {k}')
v.requires_grad = False下面是 Image size 和 Batch size
# Image size
gs = max(int(model.stride.max()), 32) # grid size (max stride) 这里也看不懂
imgsz = check_img_size(opt.imgsz, gs, floor= gs * 2) #verify imgsz is gs-multiple
# Batch size
if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size 自动估算batch_size
batch_size = check_train_batch_size(model, imgsz)Optimizer
# Optimizer
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}")
g0, g1, g2 = [], [], [] # optimizer parameter groups
for v in model.modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
g2.append(v.bias)
if isinstance(v, nn.BatchNorm2d): # weight (no decay)
g0.append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g1.append(v.weight)
if opt.adam:
optimizer = Adam(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
optimizer = SGD(g0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
optimizer.add_param_group({'params': g1, 'weight_decay': hyp['weight_decay']}) # add g1 with weight_decay
optimizer.add_param_group({'params': g2}) # add g2 (biases)
LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__} with parameter groups "
f"{len(g0)} weight, {len(g1)} weight (no decay), {len(g2)} bias")
del g0, g1, g2
hasattr()函数
返回对象是否具有给定名称的属性。这里是看v里面是否有bias
Adam
pytorch优化器详解:Adam_拿铁大侠的博客-CSDN博客
SGD
随机梯度下降,具体的函数以后查
Scheduler
# Scheduler
if opt.linear_lr:
lf = lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
else:
lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
lambda
见笔记
one_cycle()
cosine步长衰减
def one_cycle(y1=0.0, y2=1.0, steps=100):
# lambda function for sinusoidal ramp(正弦坡道) from y1 to y2 https://arxiv.org/pdf/1812.01187.pdf
return lambda x: ((1 - math.cos(x * math.pi / steps)) / 2) * (y2 - y1) + y1lr_scheduler:调整学习率
torch.optim.lr_scheduler:调整学习率_qyhaill的博客-CSDN博客_lr_scheduler
EMA
#EMA
ema = ModelEMA(model) if RANK in [-1,0] else NoneEMA:
指数移动平均(EMA)的原理及PyTorch实现_zhang2010hao的博客-CSDN博客_指数移动平均
Resume
# Resume
start_epoch, best_fitness = 0, 0.0
if pretrained:
# Optimizer
if ckpt['optimizer'] is not None:
optimizer.load_state_dict(ckpt['optimizer'])
best_fitness = ckpt['best_fitness']
# EMA
if ema and ckpt.get('ema'):
ema.ema.load_state_dict(ckpt['ema'].float().state_dict())
ema.updates = ckpt['updates']
# Epochs
start_epoch = ckpt['epoch'] + 1
if resume:
assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.'
if epochs < start_epoch:
LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
epochs += ckpt['epoch'] # finetune additional epochs
del ckpt, csdstart_epoch, best_fitness
load_state_dict()
loads the optimizer state(加载优化器状态)
多机多卡
# DP mode
if cuda and RANK == -1 and torch.cuda.device_count() > 1:
logging.warning('DP not recommended, instead use torch.distributed.run for best DDP Multi-GPU results.\n'
'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
model = torch.nn.DataParallel(model)- DP模式:单机多卡,但是这个情况也会出现一些问题,例如主卡爆掉,其他卡利用率上不去。当然,这是要修改底层和与硬件相关的问题,怎么优化还得靠人家框架官方。
- DDP模式:多机多卡,能解决DP不均衡,主卡爆掉的问题,也就是单机多卡也能用,但是这个一般人也用不到,家里有条件的时候再去研究吧。
SyncBatchNorm
# SyncBatchNorm
if opt.sync_bn and cuda and RANK != -1:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
LOGGER.info('Using SyncBatchNorm()')opt里面有这个参数,可以注意一下这个是什么功能
RANK
RANK = -1 和 RANK = 0 分别对应什么情况
Trainloader
# Trainloader
train_loader, dataset = create_dataloader(train_path, imgsz, batch_size // WORLD_SIZE, gs, single_cls,
hyp=hyp, augment=True, cache=opt.cache, rect=opt.rect, rank=LOCAL_RANK,
workers=workers, image_weights=opt.image_weights, quad=opt.quad,
prefix=colorstr('train: '))
mlc = int(np.concatenate(dataset.labels, 0)[:, 0].max()) # max label class
nb = len(train_loader) # number of batches
assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
WORLD_SIZE
batch_size // WORLD_SIZE 算什么??
WORLD_SIZE = int(os.getenv('WORLD_SIZE',1))
getenv():
def getenv(key, default=None):
"""Get an environment variable, return None if it doesn't exist.
获取一个环境变量,如果不存在返回None
The optional second argument can specify an alternate default.
可选的第二个参数可以指定一个备用默认值。
key, default and the result are str.(都是str)
"""
return environ.get(key, default)gs
grid size (max stride)网格大小(最大步长)
augment(增加)
什么意思呢
cache(缓存)
--cache images in "ram" (default) or "disk"
LOCA_RANK
??
np.concatenate
numpy.concatenate()函数_人类高质量算法工程狮的博客-CSDN博客
mlc = int(np.concatenate(dataset.labels, 0)[:, 0].max())
这里labels在第0维上拼接,每个label有1类别+4位置5个数成一个列表,dataset.labels在coco128上就有128张图对应128个列表,拼接起来成一个有128个列表的列表。[:,0]取出第0位所有的类,算出最大值。
Process 0
# Process 0
if RANK in [-1, 0]:
val_loader = create_dataloader(val_path, imgsz, batch_size // WORLD_SIZE * 2, gs, single_cls,
hyp=hyp, cache=None if noval else opt.cache, rect=True, rank=-1,
workers=workers, pad=0.5,
prefix=colorstr('val: '))[0]
if not resume:
labels = np.concatenate(dataset.labels, 0)
# c = torch.tensor(labels[:, 0]) # classes
# cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
# model._initialize_biases(cf.to(device))
if plots:
plot_labels(labels, names, save_dir)
# Anchors
if not opt.noautoanchor:
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
model.half().float() # pre-reduce anchor precision
callbacks.run('on_pretrain_routine_end')plot_labels(labels, names, save_dir)
函数定义在utils/plots.py中,应该是处理labels的,name是label的名字,这里比较奇怪的是save_dir是从opt.save_dir中传过来的,但是在train.py的opt里面没有找到save_dir,而且save_dir在train.py中多次使用,在最上面opt.save_dir点到了loggers里面,但Logger定义的时候也是用的save_dir传进去,套娃
Anchors部分
opt.noautoanchor根本找不到,怀疑这部分是被淘汰了
check_anchors()
这是写在utils的antoanchor中,Check anchor fit to data, recompute if necessary
DDP mode
# DDP mode 这个好像是线程对齐的模式
if cuda and RANK != -1:
model = DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)Model patameters
# Model parameters
nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
hyp['box'] *= 3 / nl # scale to layers
hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
hyp['label_smoothing'] = opt.label_smoothing
model.nc = nc # attach number of classes to model
model.hyp = hyp # attach hyperparameters to model
model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
model.names = namesde_parallel()
在utils/torch_utils.py
def de_parallel(model):
# De-parallelize a model: returns single-GPU model if model is of type DP or DDP
return model.module if is_parallel(model) else model这里de_parallel(model).model[-1].nl -1是什么意思,按照列表的规则应该是最后一位?
model[-1].nl
self.nl = len(anchors) # number of detection layers还是不太理解这里放anchors,还有detection layers指哪些,还有为什么就能scale hyps了,是hyps里面经常用到吗??















 7586
7586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









