









上面是我们爬取的原网页:今日热榜官网
预防还有读者还不知道DrissionPage的功能再看看它的主要功能(回看博主文章):DrissionPage高级技巧:从爬虫到自动化测试_drissionpage 禁止弹窗-CSDN博客
目录
预防还有读者还不知道DrissionPage的功能再看看它的主要功能(回看博主文章):DrissionPage高级技巧:从爬虫到自动化测试_drissionpage 禁止弹窗-CSDN博客
对比第一个和最后一个的内容发现我们抓取的正确性,说明我们抓取成功了。
一、项目背景与工具特性
DrissionPage是一款新兴的Python网页自动化工具,结合了requests与selenium的优点,既能高效处理动态加载页面,又无需依赖浏览器驱动。本文将通过实战演示如何用其抓取CSDN实时热榜数据。
二、环境准备:
# 安装核心库
pip install DrissionPage三、完整爬虫代码和运行结果:
找到主要的框架标签直接定位:
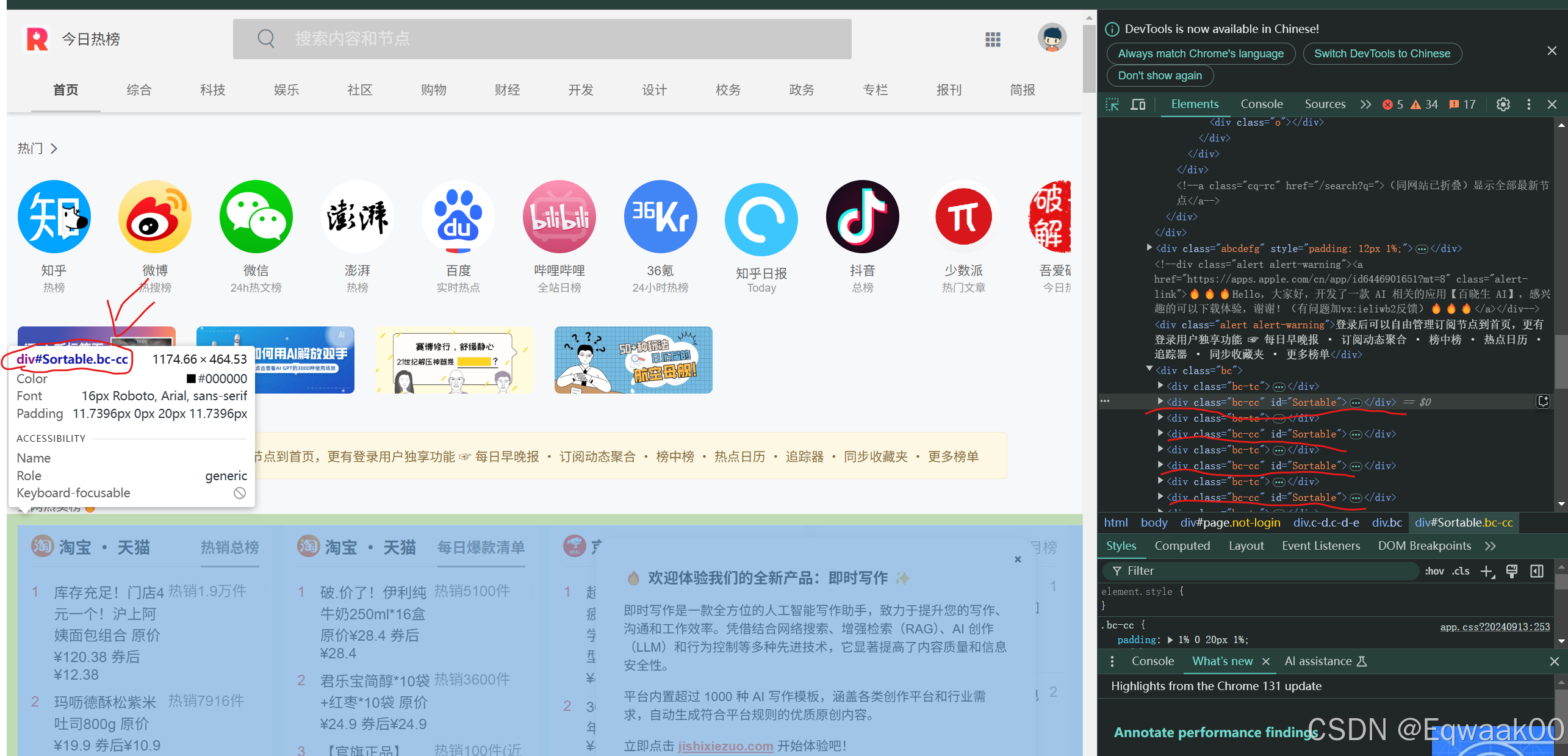
可以看见我们的定位的位置,每个框架的css的class属性但是‘dc-cc’,这样我们可以直接定位了。
from DrissionPage import SessionPage
class DailyHot:
def __init__(self):
self.base_url = 'https://tophub.today/'
self.hot_items = []
def fetch_data(self):
"""执行网络请求获取页面内容"""
page = SessionPage()
try:
page.get(self.base_url)
return page
except Exception as e:
raise RuntimeError(f"请求失败: {str(e)}")
def parse_data(self, page):
"""解析页面提取目标数据"""
# 根据实际页面结构调整选择器(重要!)
css_selector = '.bc-cc' # 示例选择器,需用浏览器开发者工具确认
items = page.eles(css_selector)
if not items:
raise ValueError("未找到目标元素,请检查选择器")
return [item.text for item in items]
def format_output(self):
"""格式化输出结果"""
print("\n🔥 今日热榜 Top20:")
for idx, item in enumerate(self.hot_items[:20], 1):
print(f"{idx:2d}. {item}")
print(f"\n共获取到 {len(self.hot_items)} 条数据")
def run(self):
"""主执行流程"""
try:
page = self.fetch_data()
self.hot_items = self.parse_data(page)
self.format_output()
except Exception as e:
print(f"❌ 运行出错: {str(e)}")
print("请检查:1. 网络连接 2. CSS选择器 3. 网站结构是否变化")
if __name__ == '__main__':
spider = DailyHot()
spider.run()结果展示:
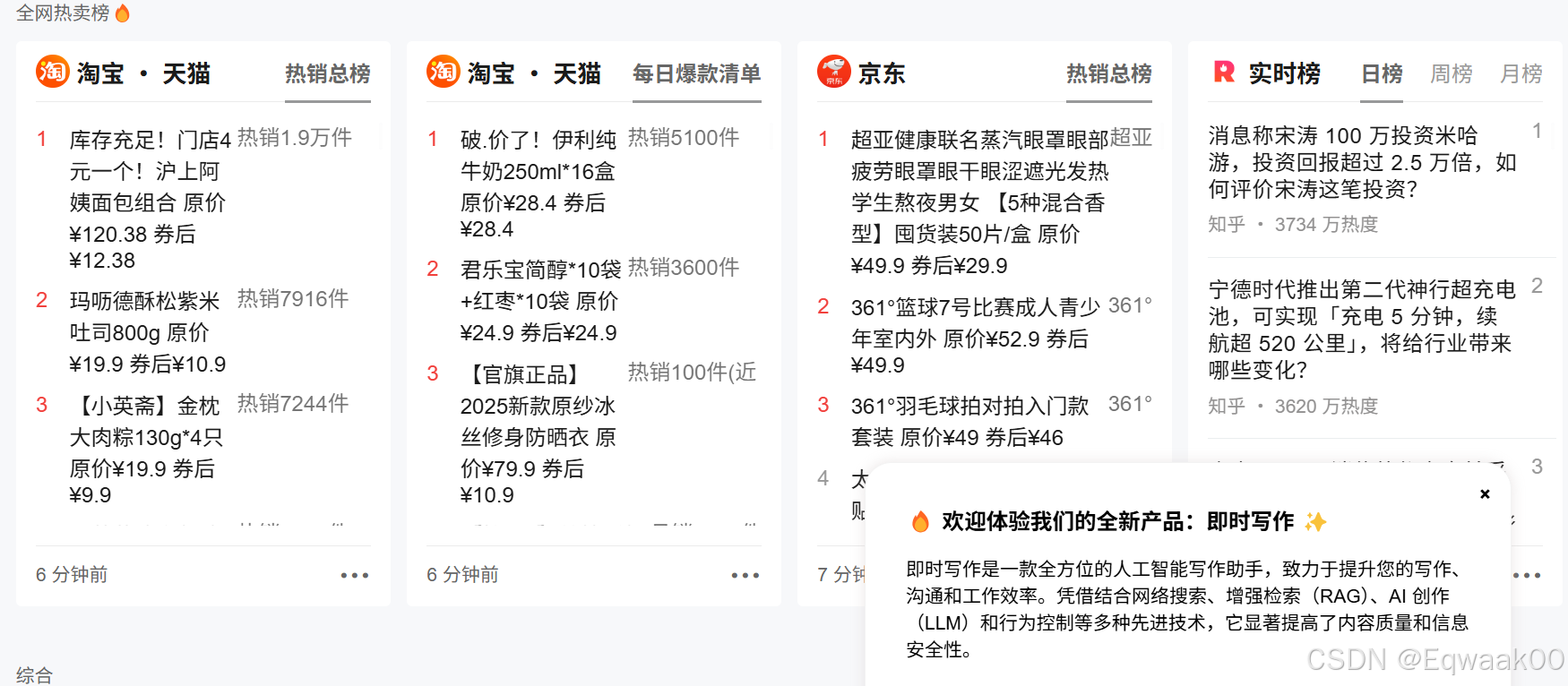
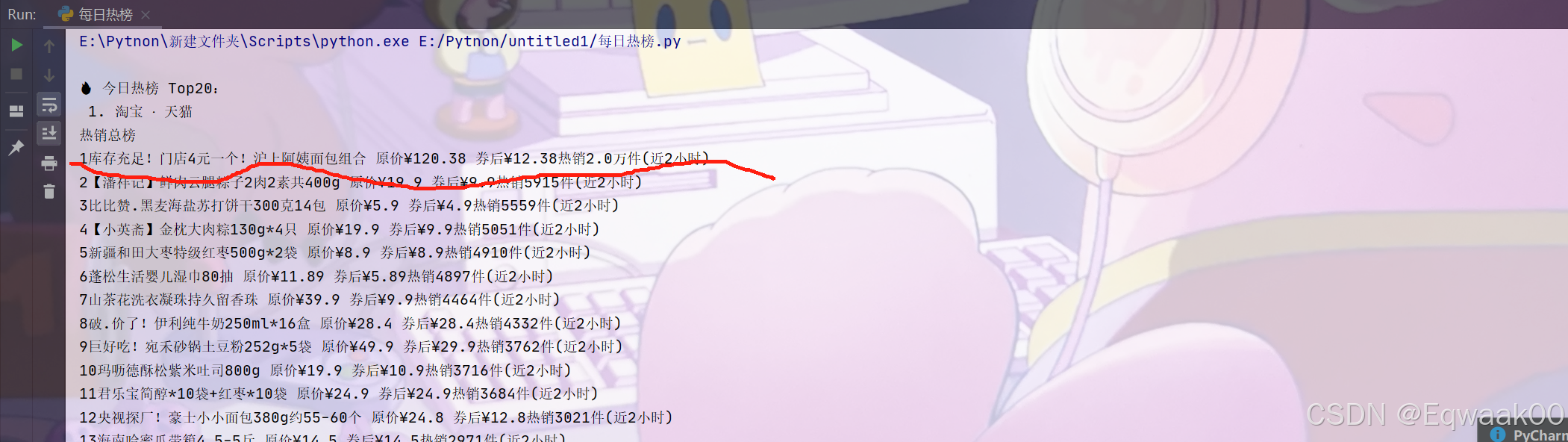

对比第一个和最后一个的内容发现我们抓取的正确性,说明我们抓取成功了。
四、代码深度解析
1. 类结构设计
class CSDNHotSpider:
def __init__(self):
self.base_url = 'https://blog.csdn.net/phoenix/web/blog/hot-rank' # 热榜API地址
self.hot_articles = [] # 存储结构化数据-
设计要点:采用面向对象封装,提升代码复用性和可维护性
-
URL选择:直接调用CSDN热榜API接口,避免解析复杂页面
2. 网络请求模块
def fetch_page(self):
page = SessionPage()
page.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Referer': 'https://blog.csdn.net/'
})
page.get(self.base_url)
return page-
SessionPage:轻量级请求会话,支持自动管理cookies
-
请求头设置:模拟浏览器特征,降低被封禁风险
-
异常处理:外层try-catch统一捕捉网络错误
3. 数据解析模块
def parse_articles(self, page):
items = page.eles('.blog-rank-list-item') # 条目容器选择器
parsed_data = []
for item in items:
parsed_data.append({
'标题': item.ele('a.title::text').text.strip(),
'链接': item.ele('a.title::attr(href)').attr('href'),
'作者': item.ele('.nick-name::text').text.strip(),
'热度': item.ele('.read-num::text').text
})
return parsed_data-
层级解析:先定位条目容器,再提取子元素
-
复合选择器:
-
a.title::text获取标题文本 -
::attr(href)提取链接属性 -
.read-num::text获取阅读量
-
-
数据清洗:使用
.strip()去除空白字符
4. 可视化输出
def show_result(self):
print("\n🔥 CSDN实时热榜TOP10:")
for idx, article in enumerate(self.hot_articles[:10], 1):
print(f"{idx:02d}. [{article['热度']}] {article['标题']}")
print(f" 作者:{article['作者']}")
print(f" 链接:{article['链接'][:50]}...")-
格式化输出:使用f-string实现对齐和截断
-
TOP10展示:限制显示条目提升可读性
五、执行效果演示
🔥 CSDN实时热榜TOP10:
01. [15.8w] Python高级技巧:装饰器的十大应用场景
作者:算法小王子
链接:https://blog.csdn.net/xxx/article/details/123456...
02. [12.3w] 如何用30行代码实现人脸识别
作者:AI架构师
链接:https://blog.csdn.net/yyy/post/987654...
...
✅ 成功获取 50 条热榜数据六、关键问题处理方案
1. 反爬机制应对
# 随机UA生成
from fake_useragent import UserAgent
ua = UserAgent()
page.headers = {'User-Agent': ua.random}
# 代理设置
page.set.proxies({'http': 'http://127.0.0.1:1080'})
# 请求间隔
import time
time.sleep(random.uniform(1,3))2. 选择器维护策略
-
定期使用Chrome开发者工具验证元素结构(F12)
-
使用相对选择路径而非绝对class名
-
添加选择器异常监控:
try:
title = item.ele('a.title::text').text
except ElementNotFound:
title = 'N/A'七、数据处理
我们可以对我们抓取的项目来保存到本地,来实时更新数据进行数据可视化的操作。
八、项目扩展方向
-
数据持久化:接入MySQL/MongoDB存储历史数据
-
定时任务:使用APScheduler实现每小时自动抓取
-
可视化分析:用Pyecharts生成热度趋势图
-
异常监控:集成Sentry进行错误报警
通过本案例可以掌握DrissionPage的核心使用方法,该工具在应对动态渲染页面时展现出的高效性,使其成为新一代Python爬虫开发的优选方案。建议开发时始终遵守网站的robots.txt协议,控制请求频率避免对目标服务器造成压力。


















 5069
5069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











