







一:RDD粗粒度与细粒度
粗粒度: 在程序启动前就已经分配好资源(特别适用于资源特别多而且要进行资源复用)
细粒度:计算需要资源是才分配资源,细粒度没有资源浪费问题。
二: RDD 的解密:
1,分布式(擅长迭代式是spark的精髓之所在) 基于内存(有些时候也会基于硬盘) 特别适合于计算的计算框架
2,RDD代表本身要处理的数据,是一个数据集Dataset RDD本身是抽象的,对分布式计算的一种抽象
RDD 定义: 弹性分布数据集 代表一系列的数据分片
3,RDD弹性之一: 自动进行内存和磁盘数据存储的切换
RDD弹性之二:基于Lineage(血统)的高效容错:
基于DAG图,lineage是轻量级而高效的:
操作之间相互具备lineage的关系,每个操作只关心其父操作,各个分片的数据之间互不影响,出现错误的时候只要恢复单个Split的特定部分即可:
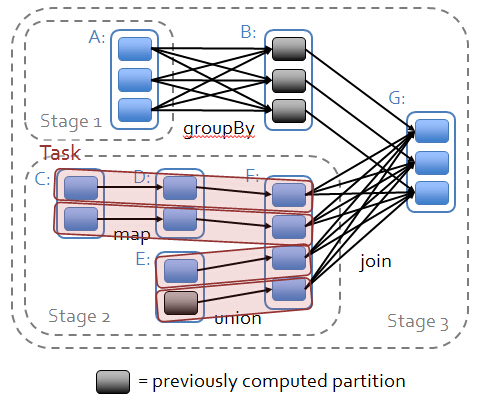
RDD弹性之三: Task如果进行失败会进行特定次数的重试(某一计算步骤一般重试4次)
RDD弹性之四:stage如果失败会进行特定次数的重试
RDD弹性之五:checkpoint 和persist(持久化 将数据放在内存上)
RDD弹性直六:数据调度弹性:DAG Task 和资源管理无关
RDD弹性之七: 数据分片的高度弹性
checkpoint解密:1,spark 在生产环境下经常会面临Transformations 的RDD 特别多(例如一个job里面包含了1万个RDD)或者具体Transformation产生的RDD本身计算特别复杂和耗时(例如计算时长超过1万小时)此时我们必须考虑对计算数据的持久化
2,spark擅长多步骤的迭代 同时擅长基于job的复用,这个时候如果能够对曾经计算过程产生的数据进行复用,就可以极大地提升效率
3,如果采用persist的方式把数据放在内存上的话,虽然是最快速但是也是最不可靠的;如果放在磁盘上也不是完全可靠(例如管理员可能清空磁盘等)
4,checkpoint的产生就是为了相对而言更可靠的持久化数据,在checkpoint可以指定把数据放在本地且是多副本的方式,但是正常的生产环境下是放在HDFS,这就天然的借助了HDFS高容错 高可靠的特性来完成最大化的可靠的特征来完成了最大化的持久化数据的方式
5,checkpoint是为了最大程度 保证绝对可靠的复用RDD 计算数据的spark 的高级功能通过checkpoint我们通过把数据持久化的HDFS来保证数据最大程度的安全性
6,checkpoint就是针对整个RDD计算链条中特别需要数据持久化的环节(后面反复使用当前环节的RDD)开始基于HDFS等的数据持久化复用策略,通过对RDD启动checkpoint机制来实现容错和高复用
RDD上的 Partition size = 默认为HDFS上的Block Size
移动计算而不是移动数据
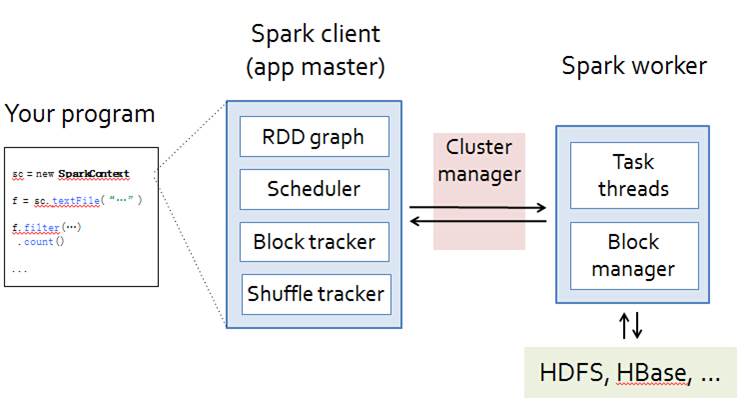
每步操作都产生RDD,RDD包含对函数的计算,RDD是有依赖关系的RDD逻辑上代表了HDFS上的数据,计算前数据不用传到机器上,因为数据就在机器上。
三:Spark的位置感知 比Hadoop的位置感知好很多 Hadoop 在进行Partitions 之后就不管reduce在哪里了 但是Spark 在进行Partition进行下一步stage操作时候会确定这个位置是精致化的。
四: MapReduce 是基于数据集 spark是基于工作集
无论是基于数据集还是工作集 都有位置感知,容错 负载均衡这些工作特征
基于数据集的处理:从物理存储上加载数据,然后操作数据,然后写入物理存储设备,主要代表Hadoop的MapReduce
基于数据集不适合的工作场景:1,不适合于大量的迭代 2,不适合于交互式查询 重点是:基于数据流的方式不能复用曾经的结果或者中间结果。
RDD是基于工作集的 RDD允许用户在执行多个查询任务的时候,显式
的将工作集缓存在内存中,其他人查询的时候就可以复用
假设stage内部有1000个步骤 中间不会默认产生999次结果,如果是默认情况下之产生一次 结果
partion 很小 要合并, block 大 分成小片 :
提高处理批次 人工做
减少个数
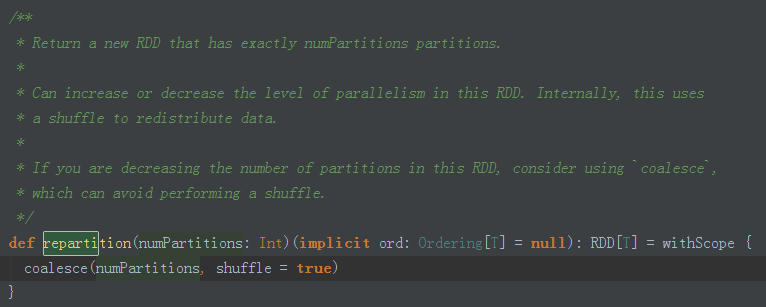
1W 个变成10W 个 可用可不用 shuffle
100W变 1W 不用 shuffle
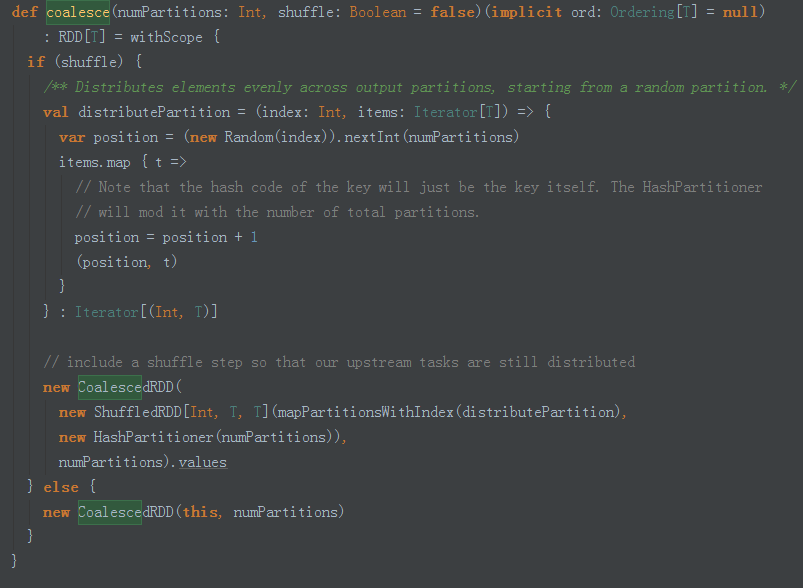
调用 coalesece

五: RDD通过记录数据更新的方式为何很高效
1,RDD是不可变的 + lazy (每次操作就变成新的RDD,因为RDD是不可变的,新的RDD与前面的RDD为这个this指针 作为第一个参数,所以就不存在全局修改的问题,控制难度就极大的下降,在这基础上有计算链条,因有计算链条,901条出错时可以从900条恢复,第一点:lazy级别的且是不可变的构成链条,导致计算的时候从后往前回溯不会每次产生中间的结果之类的只是记录了对他的什么操作 第二点容错的时候它会记录前面的东西,在前面某步的基础而不是从头计算 )
2,RDD是粗粒度 RDD的具体的数据结构的操作都是粗粒度的 RDD 的写操作(彻底修改数据例如网络爬虫)是粗粒度的 但是RDD的读操作(查询数据)既可以是粗粒度的也可以是细粒度的
RDD 一系列数据分片上运行的计算逻辑是一样的
3,所有的RDD操作返回的都是迭代器这就让所有框架无缝集成
面向接口编程 返回的是接口级别的RDD 但可以操作接口的子类的方法 为什么Spark可以 因为this.type ,所以可以通过运行时也就是Runtime来具体把实际的实例赋值给RDD转过来就可以操作它。
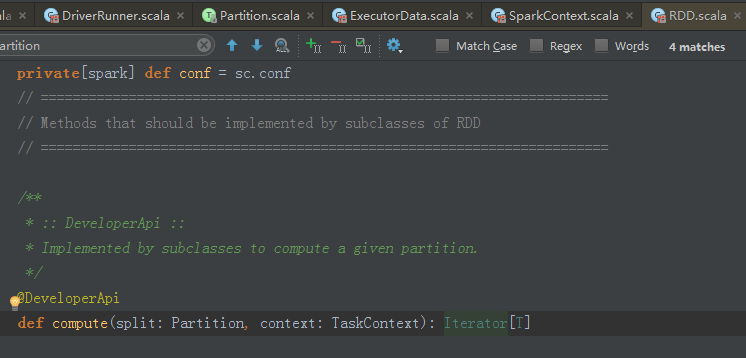

可操作 RDD接口 子类方法:
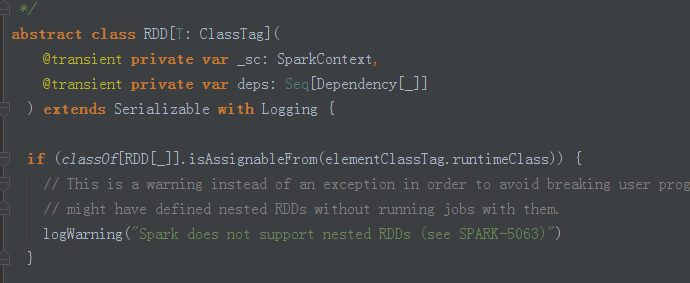
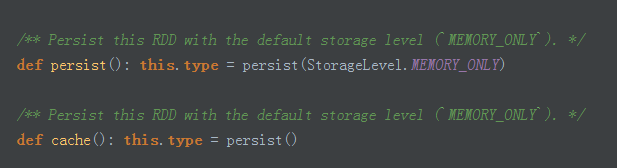
面向接口 使用的接口 ,能否 调用接口的子类?
java 不可以这是Scala的语法提供的this.type 指向 具体的子类 可以调用 子类 方法
运行时 把具体实列赋值给RDD 中 然后转过来 就可以操作它,
指向 子类的方法
写一个框架 符合RDD 规范 因为无缝集成 可以调动很多框架
六:RDD的缺陷:主要不支持细粒度的写操作(更新)和以及增量迭代计算















 3544
3544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









