







本文主要内容包括 : “钨丝计划”的shuffle的使用
一:使用Tungsten功能
1, 如果想让您的程序使用Tungsten的功能,可以配置:
Spark.Shuffle.Manager = tungsten-sort
2, DataFrame中自动开启了Tungsten功能。
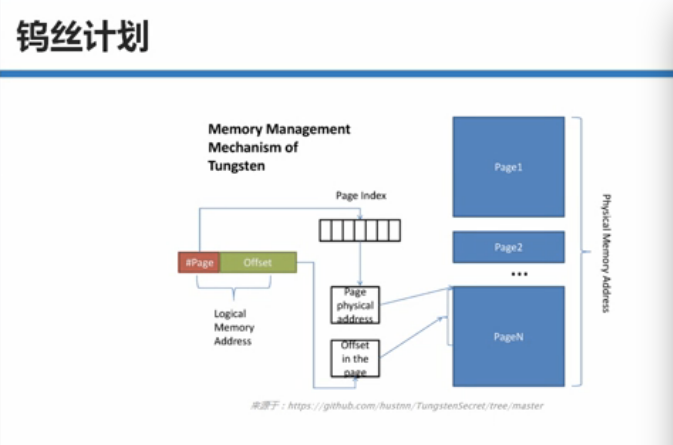
二:Tungsten-sort base Shuffle writer内幕
1,写数据在内存足够大的情况下是写到Page里面,在Page里面有一条条的Record,如果内存不够的话,会spill到磁盘上,输入数据的时候是循环每个Task中处理的数据Partition的结果,循环的时候会查看是否有内存,一个Page写满之后,才会写下一个Page。
2,如何看内存是否足够呢?
a)系统默认情况下给 shuffleMapTask 最大准备了多少内存空间,默认情况下是ExecutorHeapMemory*0.8*0.2 (spark.shuffle.memoryFraction = 0.2 , spark.shuffle.safeFraction = 0.8)
b)另外一方面是和Task处理的Partition大小紧密相关
写入的过程图:
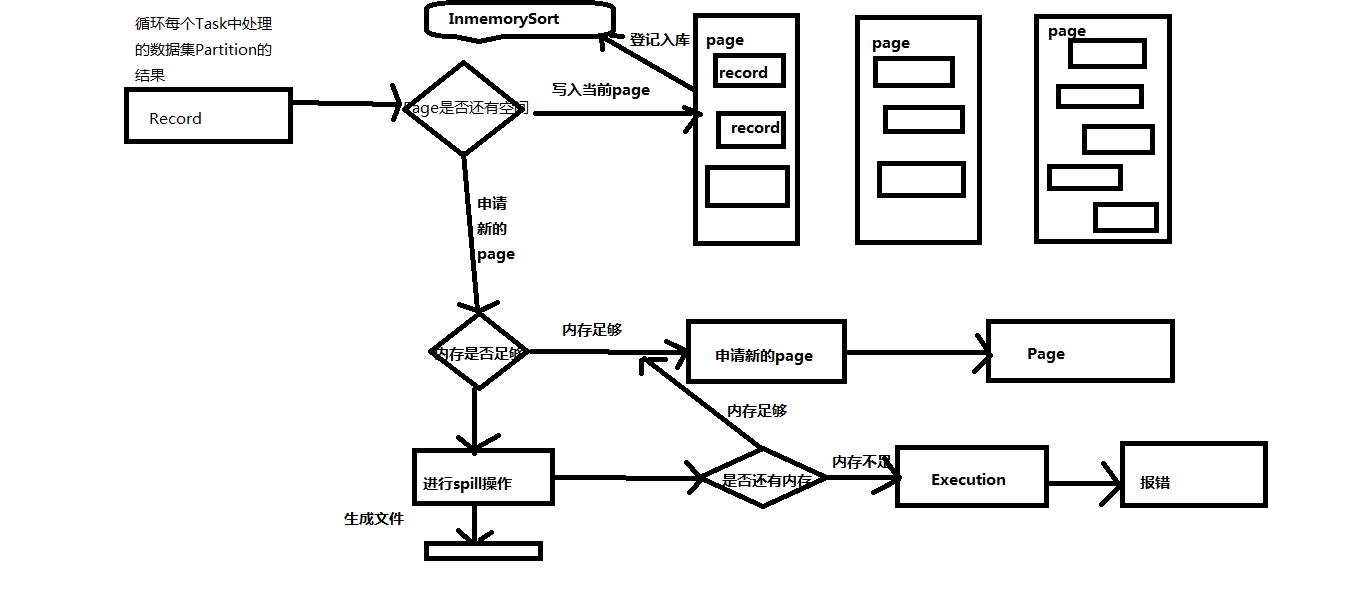
1,mergeSpills的功能是将很多小文件合并成一个大文件。然后加上index文件索引。
2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2159
2159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









