







 本文介绍了如何使用Spark Streaming的reduceByKeyAndWindow操作来实现在线热点搜索词的实时统计。文章详细阐述了滑动窗口的概念,并通过代码分析解释了reduceByKeyAndWindow的工作原理和效率优势,提供了具体的实战案例和集群运行效果。
本文介绍了如何使用Spark Streaming的reduceByKeyAndWindow操作来实现在线热点搜索词的实时统计。文章详细阐述了滑动窗口的概念,并通过代码分析解释了reduceByKeyAndWindow的工作原理和效率优势,提供了具体的实战案例和集群运行效果。
本博文主要内容包括:
1、在线热点搜索词实现解析
2、SparkStreaming 利用reduceByKeyAndWindow实现在线热点搜索词实战
一:在线热点搜索词实现解析
背景描述:在社交网络(例如微博),电子商务(例如京东),热搜词(例如百度)等人们核心关注的内容之一就是我所关注的内容中,大家正在最关注什么或者说当前的热点是什么,这在市级企业级应用中是非常有价值,例如我们关心过去30分钟大家正在热搜什么,并且每5分钟更新一次,这就使得热点内容是动态更新的,当然更有价值。 Yahoo(是Hadoop的最大用户)被收购,因为没做到实时在线处理实现技术:Spark Streaming(在线批处理) 提供了滑动窗口的奇数来支撑实现上述业务背景,我外面您可以使用reduceByKeyAndWindow操作来做具体实现
我们知道在SparkStreaming中可以设置batchInterval,让SparkStreaming每隔batchInterval时间提交一次Job,假设batchInterval设置为5秒,那如果需要对1分钟内的数据做统计,该如何实现呢?SparkStreaming中提供了window的概念。我们看下图:
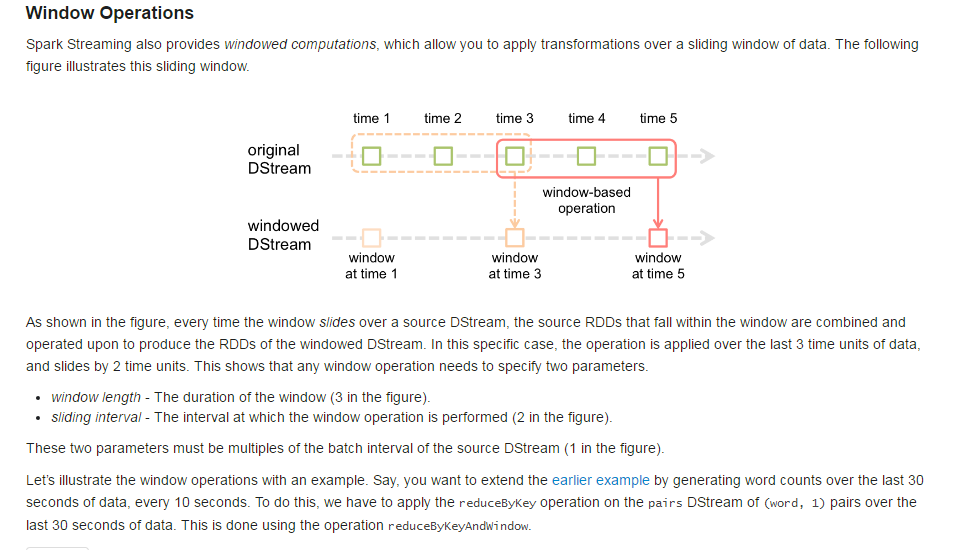
官网给的例子每个2秒钟更新过去3秒钟的内容,3秒钟算一下,5秒钟算一下,3秒钟是一个窗口。window可以包含多个batchInterval(例如5秒),但是必须为batchInterval的整数倍例如1分钟。另外window可以移动,称之为滑动时间间隔,它也是batchInterval的整数倍,例如10秒。一般情况滑动时间间隔小于window的时间长度,否则会丢失数据。
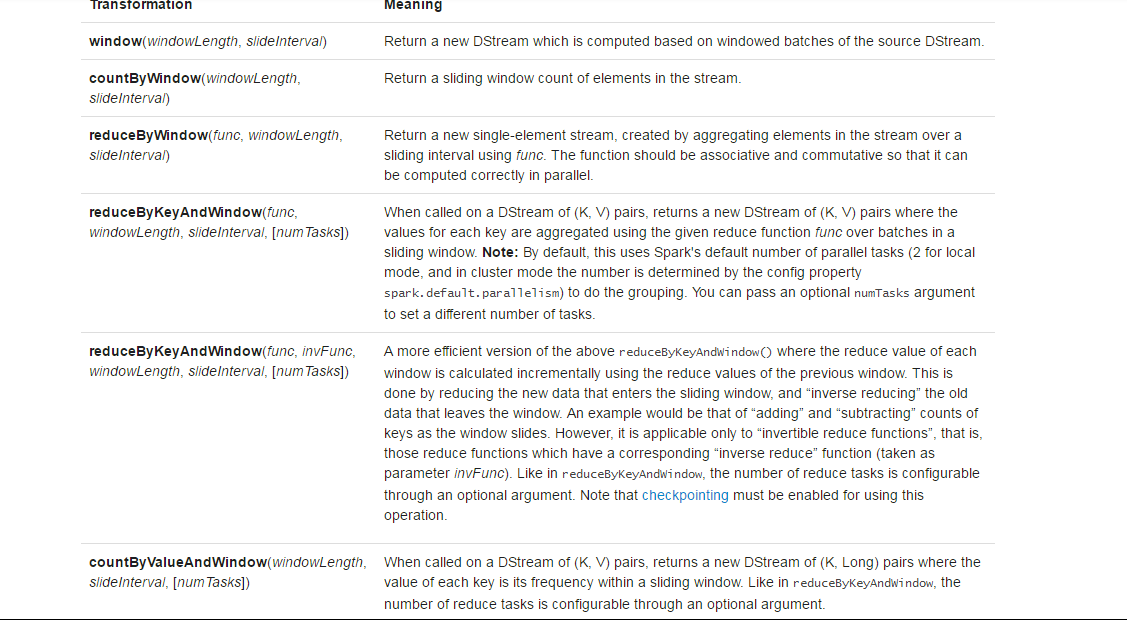
SparkStreaming提供了如下与window相关的方法:
二、SparkStreaming 实现在线热点搜索词实战
1、经过分析我们采用reduceByKeyAndWindow的方法,reduceByKeyAndWindow方法分析如下:
从代码上面来看, 入口为:
reduceByKeyAndWindow(_+_, _-_, Duration, Duration)
一步一步跟踪进去, 可以看到实际的业务类是在ReducedWindowedDStream 这个类里面:
代码理解就直接拿这个类来看了: 主要功能是在compute里面实现, 通过下面代码回调mergeValues 来计算最后的返回值
val mergedValuesRDD = cogroupedRDD.asInstanceOf[RDD[(K, Array 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1409
1409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









