







本博文内容主要包括:
1、JobScheduler内幕实现
2、JobScheduler深度思考
一:JobScheduler内幕实现:
JobScheduler的地位非常的重要,所有的关键都在JobScheduler,它的重要性就相当于是Spark Core当中的DAGScheduler,因此,我们要花重点在JobScheduler上面。
我们在进行sparkstreaming开发的时候,会对Dstream进行各种transform和action级别的操作,这些操作就构成Dstream graph,也就是Dstream 之间的依赖关系,随着时间的流逝,Dstream graph会根据batchintaval时间间隔,产生RDD的DAG,然后进行job的执行。Dstream 的Dstream graph是逻辑级别的,RDD的DAG是物理执行级别的。DStream是空间维度的层面,空间维度加上时间构成时空维度。
JobSchedule是将逻辑级别的job物理的运行在spark core上。JobGenerator是产生逻辑级别的job,使用JobSchedule将job在线程池中运行。JobSchedule是在StreamingContext中进行实例化的,并在StreamingContext的start方法中开辟一条新的线程启动的。
1、 作业流程源码 :
(1)、设置batchDuration时间间隔来控制Job生成频率并且创建SparkStream执行的入口

(2)接下来我们看一下按照一定的频率操作ForeachRDD :
我们设置每隔5秒钟都会生成一个Spark 的Job ,Job其实其内部是存在依赖关系的,当遇到时间维度的时候就变成物理级别的。DStream就是一个规划逻辑级别,遇到时间之后就相当于规划之后实施他实现级别的。

/**
* Apply a function to each RDD in this DStream. This is an output operator, so
* 'this' DStream will be registered as an output stream and therefore materialized.
* @param foreachFunc foreachRDD function
* @param displayInnerRDDOps Whether the detailed callsites and scopes of the RDDs generated
* in the `foreachFunc` to be displayed in the UI. If `false`, then
* only the scopes and callsites of `foreachRDD` will override those
* of the RDDs on the display.
*/
private def foreachRDD(
foreachFunc: (RDD[T], Time) => Unit,
displayInnerRDDOps: Boolean): Unit = {
new ForEachDStream(this,
context.sparkContext.clean(foreachFunc, false), displayInnerRDDOps).register()
}(3)、指定的两条线程,说明具体在集群中需要的线程数据,一条用于接收数据不断的循环,另外一条是处理线程。
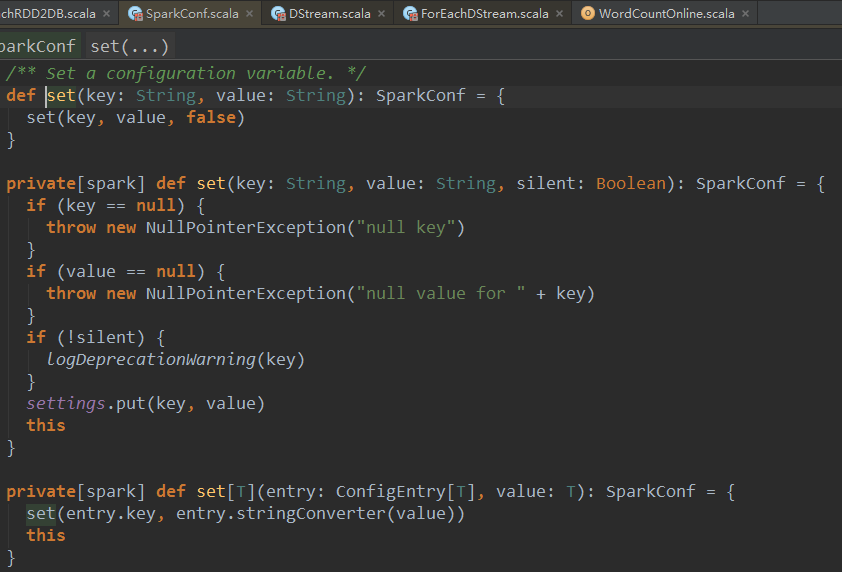
(4)、启动的新线程,是调度层面的,而应用程序是自己配置,需要把调度与执行分离开,每个线程都有自己的属性:
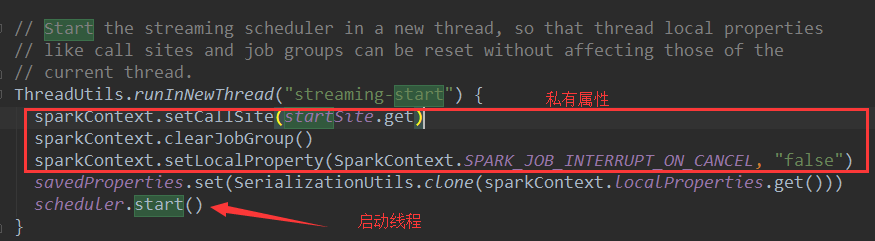
(5)、Spark Streaming源码中默认的是一个线程数 :
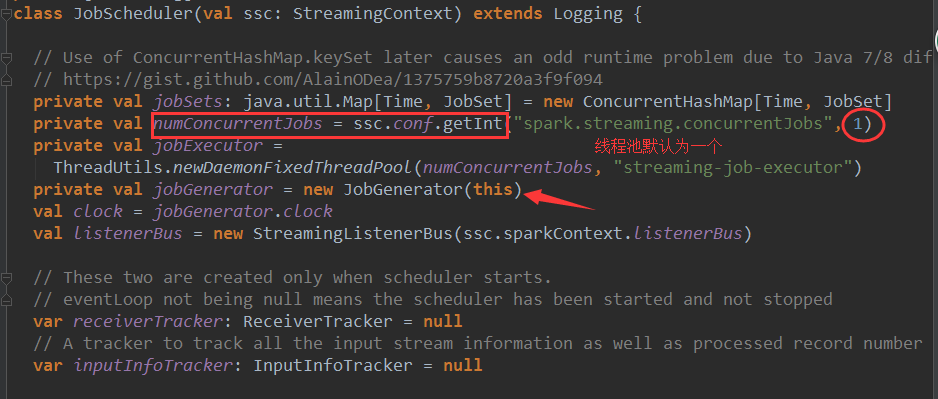
(6)、进行实例化过程
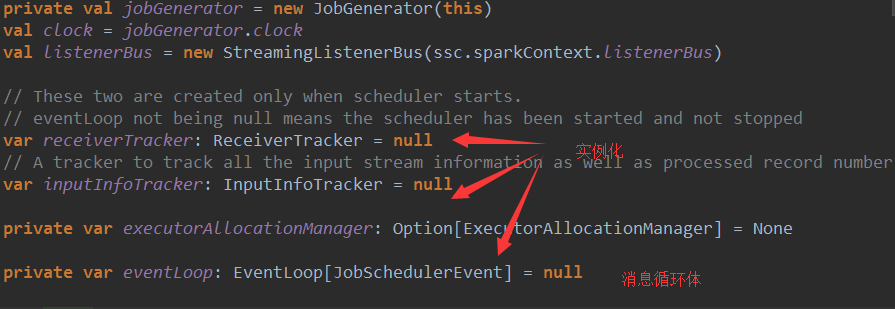
(7)、Job调度本身与需要实现的业务逻辑

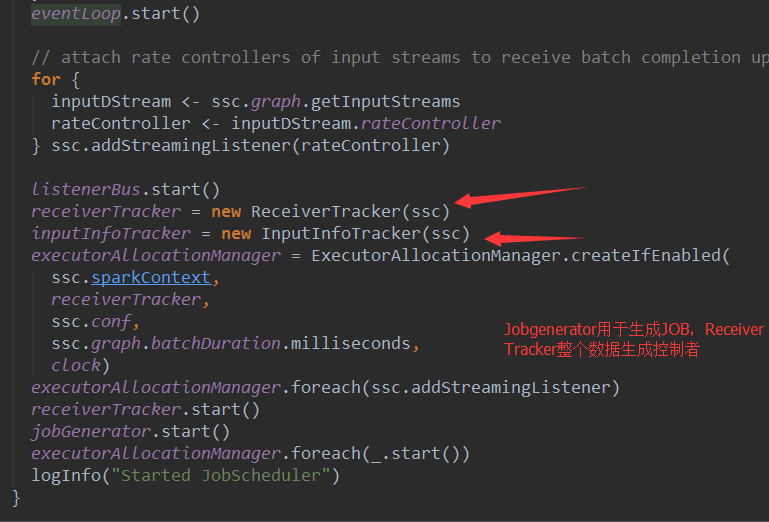
二、 调度流程源码 :
JobScheduler有三大核心 :
1. JobScheduler本身
2. JobGenerator任意生成Job
3. ReceiverTracker整个数据的控制与生成者
时间维度加Action级别,就是根据generateJob来生成作业
业务代码逻辑级别与空间级别、静态,真正运行起来变成物理级别就需要JobGeneratorEvent
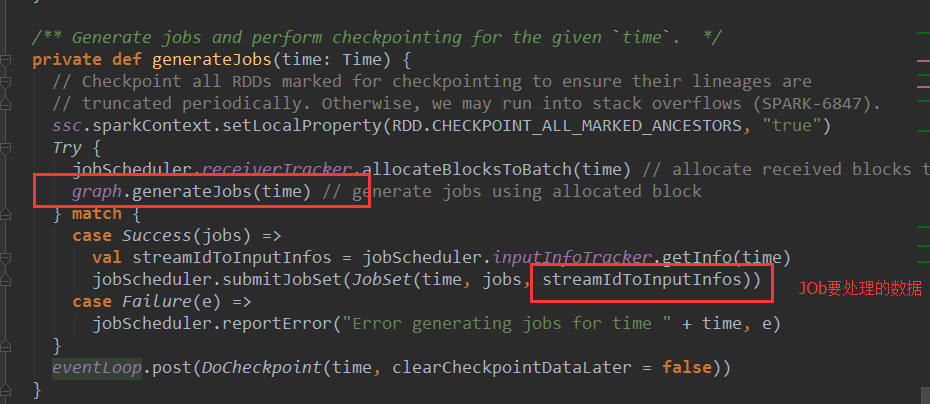
从时间维度去调用空间维度的内容,就生成了现实的内容(物理级别的)这里的outputStreams为ForeachDStream
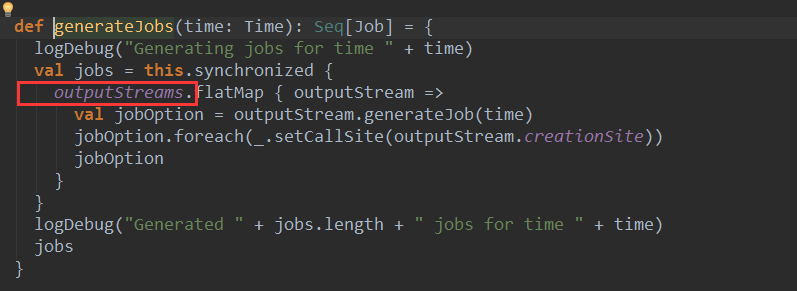
将每个Job放入线程池中,为了配合线程池使用了JobHandler
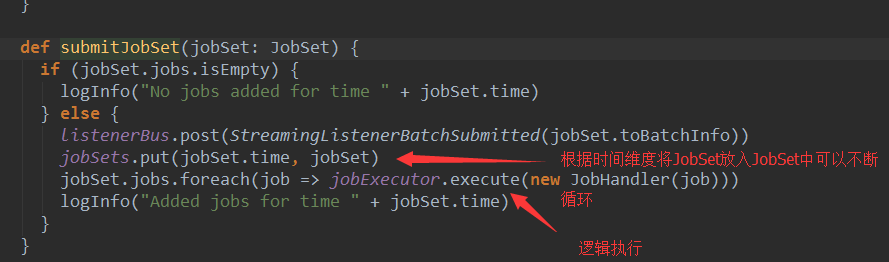
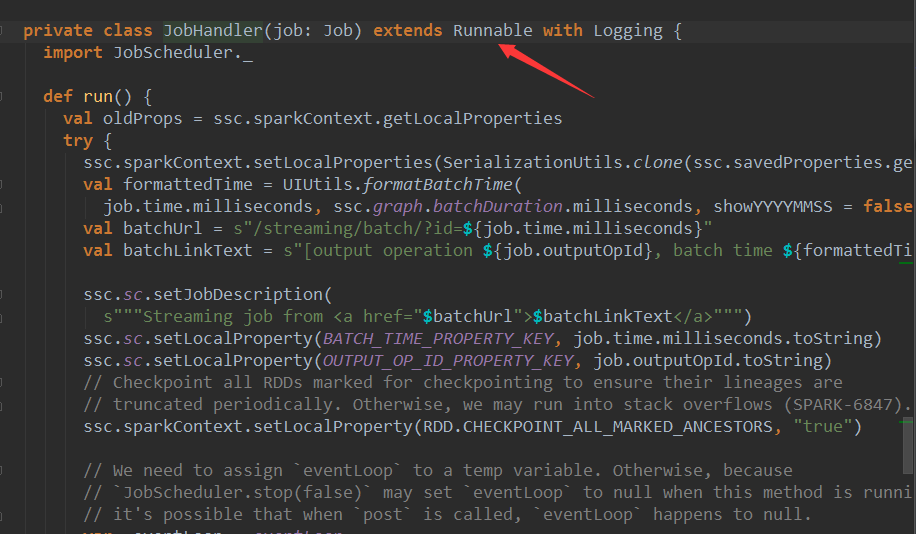
开始处理业务逻辑部分
三:基本流程文字总结:
// Start the streaming scheduler in a new thread, so that thread local properties
// like call sites and job groups can be reset without affecting those of the
// current thread.ThreadUtils.runInNewThread("streaming-start") {
sparkContext.setCallSite(startSite.get)
sparkContext.clearJobGroup()
sparkContext.setLocalProperty(SparkContext.SPARK_JOB_INTERRUPT_ON_CANCEL, "false")
scheduler.start()
}1.大括号中的代码作为一个匿名函数在新的线程中执行。Sparkstreaming运行时至少需要两条线程,其中一条用于一直循环接收数据,现在所说的至少两条线程和上边开辟一条新线程运行scheduler.start()并没有关系。Sparkstreaming运行时至少需要两条线程是用于作业处理的,上边的代码开辟新的线程是在调度层面的中,不论Sparkstreaming程序运行时指定多少线程,这里都会开辟一条新线程,之间没有一点关系。
2.每一条线程都有自己私有的属性,在这里给新的线程设置私有的属性,这些属性不会影响主线程中的。
sparkContext.setCallSite(startSite.get)
sparkContext.clearJobGroup()
sparkContext.setLocalProperty(SparkContext.SPARK_JOB_INTERRUPT_ON_CANCEL, "false")JobSchedule在实例化的时候会实例化JobGenerator和线程池。
线程池中默认是有一条线程,当然可以在spark配置文件中配置或者使用代码在sparkconf中修改默认的线程数,在一定程度上增加默认线程数可以提高执行job的效率,这也是一个性能调优的方法(尤其是在一个程序中有多个job时)。
Java在企业生产环境下已经形成了生态系统,在spark开发中和数据库、hbase、radis、javaEE交互一般都采用java,所以开发大型spark项目大部分都是scala+java的方式进行开发。
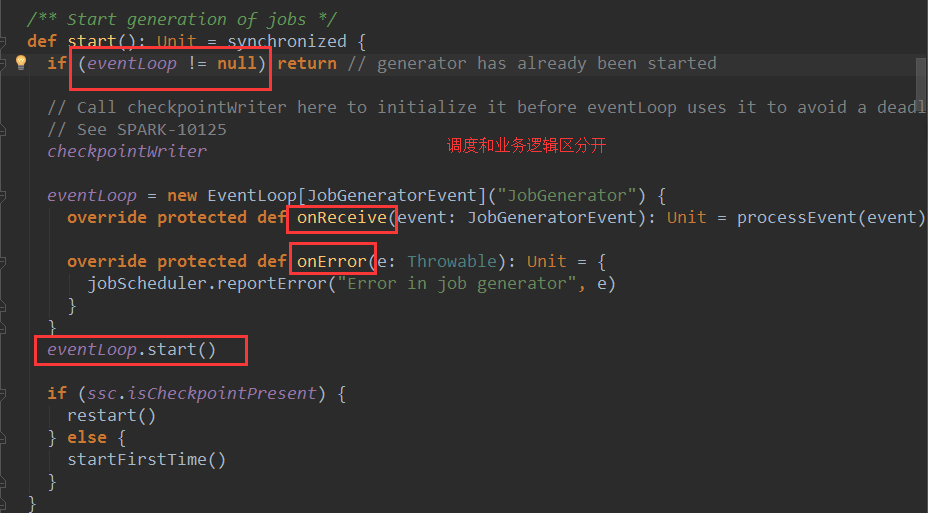
JobGenerator和线程池在JobSchedule在实例化的时候就已经实例化了,而eventloop和receiverTracker是在调用JobGenerator的start方法时才被实例
在eventloop的start方法中会回调onStart方法,一般在onStart方法中会执行一些准备性的代码,在JobSchedule中虽然并没有复写onStart方法,不过sparkStreaming框架在这里显然是为了代码的可扩展性考虑的,这是开发项目时需要学习的。
Dstream的action级别的操作转过来还是会调用foreachRDD这个方法,生动的说明在对Dstream操作的时候其实还是对RDD的操作。
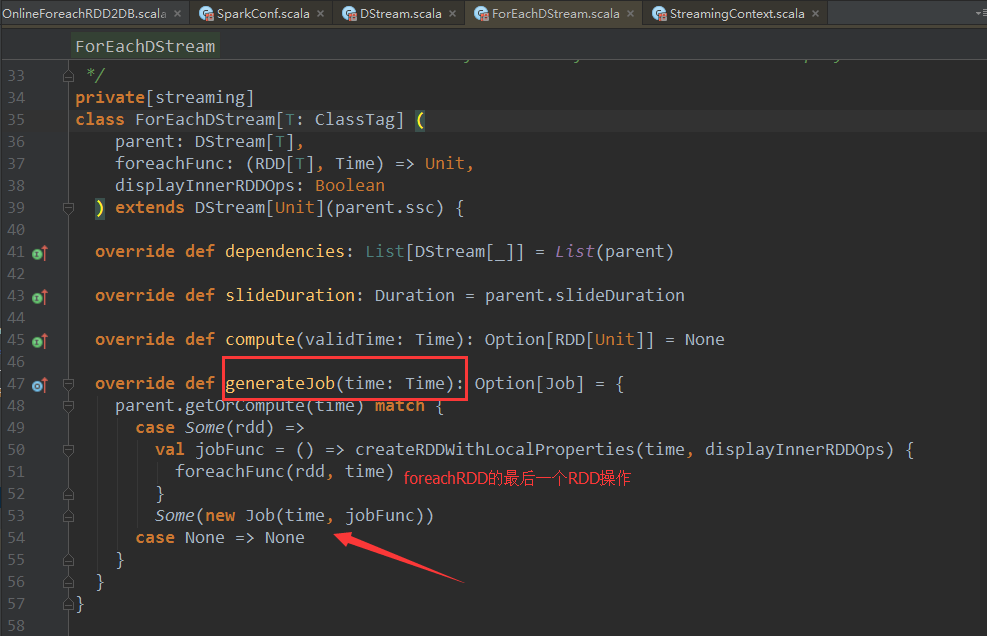
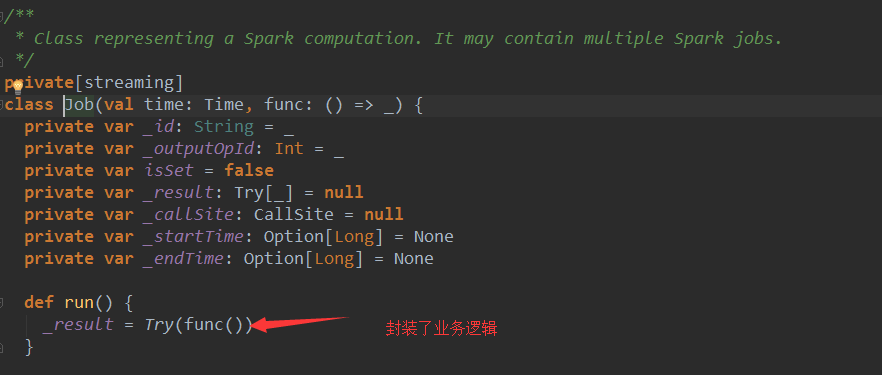
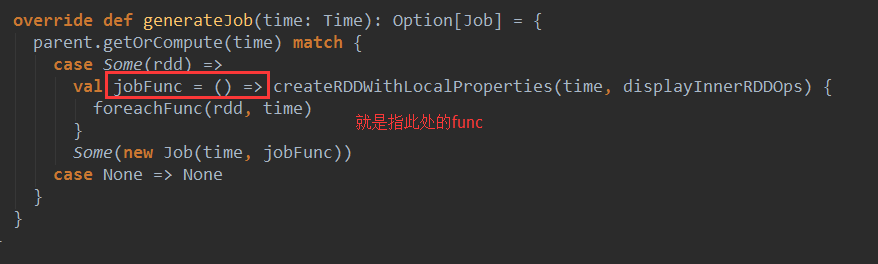
ForEachDstream中很重要的一个函数generateJob。考虑时间维度和action级别,每个Duration都基于generateJob来生成作业。foreachFunc(rdd, time)//这个方法就是对Dstream最后的操作 ,new Job(time, jobFunc)只是在RDD的基础上,加上时间维度的封装而已。这里的Job只是一个普通的对象,代表了一个spark的计算,调用Job的run方法时,真正的作业就触发了。foreachFunc(rdd, time)中的rdd其实就是通过DstreamGraph中最后一个Dstream来决定的。
Job是通过ForEachDstream的generateJob来生成的,值得注意的是在Dstream的子类中,只有ForEachDstream重写了generateJob方法。
现在考虑一下ForEachDstream的generateJob方法是谁调用的?当然是JobGenerator。ForEachDstream的generateJob方法是静态的逻辑级别,他如果想要真正运行起来变成物理级别的这时候就需要JobGenerator。
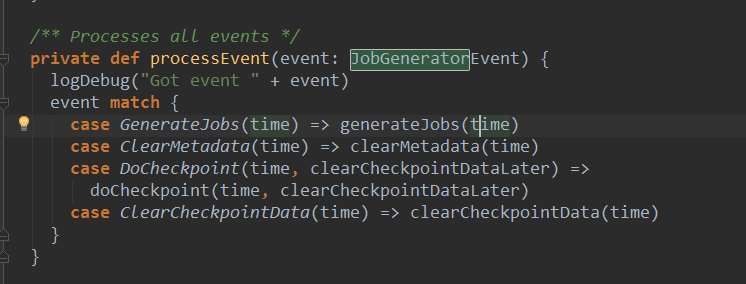
现在就来看看JobGenerator的代码,JobGenerator中有一个定时器timer和消息循环体eventloop,timer会基于batchinteval,一直向eventloop中发送JenerateJobs的消息,进而导致processEvent方法->generateJobs方法的执行。
其中的outputStream.generateJob(time)中的outputStream就是前面说ForEachDstream,generateJob(time)方法就是ForEachDstream中的generateJob(time)方法。
这是从时间维度调用空间维度的东西,所以时空结合就转变成物理的执行了。
再来看看JobGenerator的generateJobs方法:
基于graph.generateJobs产生job后,会封装成JobSet并提交给JobScheduler,JobSet(time, jobs, streamIdToInputInfos),其中streamIdToInputInfos就是接收的数据的元数据。
JobSet代表了一个batch duration中的一批jobs。就是一个普通对象,包含了未提交的jobs,提交的时间,执行开始和结束时间等信息。
JobSet提交给JobScheduler后,会放入jobSets数据结构中,jobSets.put(jobSet.time, jobSet) ,所以JobScheduler就拥有了每个batch中的jobSet.在线程池中进行执行。
在把job放入线程池中时,采用JonHandler进行封装。JonHandler是一个Runable接口的实例。
其中主要的代码就是job.run(),前面说过job.run()调用的就是Dstream的action级别的方法。
在job.run()前后会发送JonStarted和JobCompleted的消息,JobScheduler接收到这两个消息只是记录一下时间,通知一下job要开始执行或者执行完成,并没有过多的操作。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









