






在生成式 AI 时代,向量数据库对于高效存储和查询高维数据已变得不可或缺。但是,与所有数据库一样,向量数据库容易受到一系列攻击,包括网络威胁、网络钓鱼尝试和未经授权的访问。鉴于这些数据库通常包含敏感和机密信息,这一漏洞尤其重要。
为了解决这一关键问题,Cyborg 与 NVIDIA 合作,使用 RAPIDS cuVS 库增强向量数据库的安全性。RAPIDS cuVS 库是一个开源工具包,可使用先进的算法加速向量搜索。这项合作旨在为 Cyborg 的加密向量搜索引擎提供 NVIDIA 的 GPU 加速,在不影响性能的情况下确保强大的安全性。
向量数据库漏洞
向量数据库是现代数据密集型应用程序的基石,为从检索增强生成(RAG)流程到推荐系统的所有内容提供支持。
这些数据库的高性能索引构建和搜索功能使其对此类应用程序至关重要,但其存储的数据的价值使其成为恶意攻击和漏洞的热门目标。对于需要保密的业务领域,这种风险尤其值得关注,因为它们通常拥有敏感信息和商业机密,任何泄露或攻击都可能会对业务造成严重的影响。
- 受监管行业:例如,医疗健康、金融服务和公共部门,其中严格的隐私和安全要求可能会完全排除使用矢量搜索及其下游应用程序。
- IP 驱动型行业:例如制药、制造和国防等行业,在这些行业中知识产权形成了巨大的价值驱动力和竞争优势。
在对 AI 驱动的工作负载进行原型设计时,这些问题可能被忽略,但在生产方面可能会变成障碍。
解决方案:机密向量搜索
总部位于纽约的初创公司Cyborg开发了一个端到端加密向量搜索引擎来解决这一问题。通过使用前向隐私和加密哈希,Cyborg Vector Search实现了机密数据的安全索引和检索。端到端加密意味着数据库中不会存储未加密的向量,从而大幅减少了攻击面,并解决了前面提到的机密性问题。
Cyborg Vector Search旨在平衡以下关键性能特征:1. 查询效率:Cyborg Vector Search旨在实现快速的查询速度,以满足实时应用程序的需求。2. 精准度:Cyborg Vector Search旨在提供高精准度的搜索结果,以满足复杂查询的需求。3. 可扩展性:Cyborg Vector Search旨在提供可扩展的架构,以满足大规模数据集的需求。4. 灵活性:Cyborg Vector Search旨在提供灵活的查询语言,以满足多样化的查询需求。5. 成本效益:Cyborg Vector Search旨在提供成本效益的解决方案,以满足企业的经济需求。
- 端到端加密:通过符合严格隐私要求的cryptographically安全架构,确保最高级别的安全性和机密性。
- 高性能:最大限度地降低端到端加密的增量成本,将加密索引和检索的加密开销分别保持在5%和30%以内。
- 兼容性:保持与现有向量搜索管线和工作负载的一致性,实现从原型到生产的简单过渡。
NVIDIA 硬件
为了在 GPU 上实现加密索引,该解决方案使用了 NVIDIA 机密计算。机密计算可确保数据通过加密方式和强大的访问控制保持安全性,使用可信执行环境(TEE)为敏感操作提供安全的安全区。这项技术对于在 GPU 加速计算期间保持数据的机密性至关重要。
此解决方案的核心硬件是启用机密计算的 NVIDIA H100 Tensor Core GPU(80 GB)。目前,所有 NVIDIA Hopper Tensor Core GPU 均公开支持机密计算,新一代 NVIDIA Blackwell Tensor Core GPU 将继续支持机密计算。
配置为 CC 模式的 NVIDIA GPU 已激活基于硬件的加密引擎、防火墙和远程认证流,以确保 TEE 的完整性,以便最终用户可以确保并验证其机密工作负载在 GPU 上使用时受到保护。
NVIDIA Hopper 机密计算使用 AES-GCM256 对 PCIe 总线上的所有用户数据进行加密和签名,并使用经签名和可认证固件配置的防火墙阻止基础设施和带外访问。NVIDIA 还提供公共远程认证服务,以便最终用户或依赖方可以获得最新的确信,确信其驱动和固件未因错误或漏洞而被吊销。
Cyborg 使用 NVIDIA LaunchPad 快速访问和开发其设计。LaunchPad 为 NVIDIA 客户、合作伙伴和 ISV 提供了在基于浏览器的沙盒环境中动手访问预构建实验室的机会,该设计已预先配置了所有必要步骤,以确保通过开发机密 VM 应用实验室为机密工作负载正确构建和配置系统。这样,Cyborg 就无需花时间担心基础架构,而是专注于开发自己的解决方案。
加速机密向量搜索
与传统的向量搜索一样,机密向量搜索是一个计算成本高昂且难以扩展的过程。这使其成为 GPU 加速的理想候选对象。RAPIDS cuVS 包含用于执行此操作的高度优化基元。
为评估此集成的有效性,Cyborg 和 NVIDIA 进行了一项联合概念验证(POC)。这项工作涉及到将 cuVS 与 Cyborg Vector Search 集成,以实现使用 GPU 加速的加密矢量搜索。
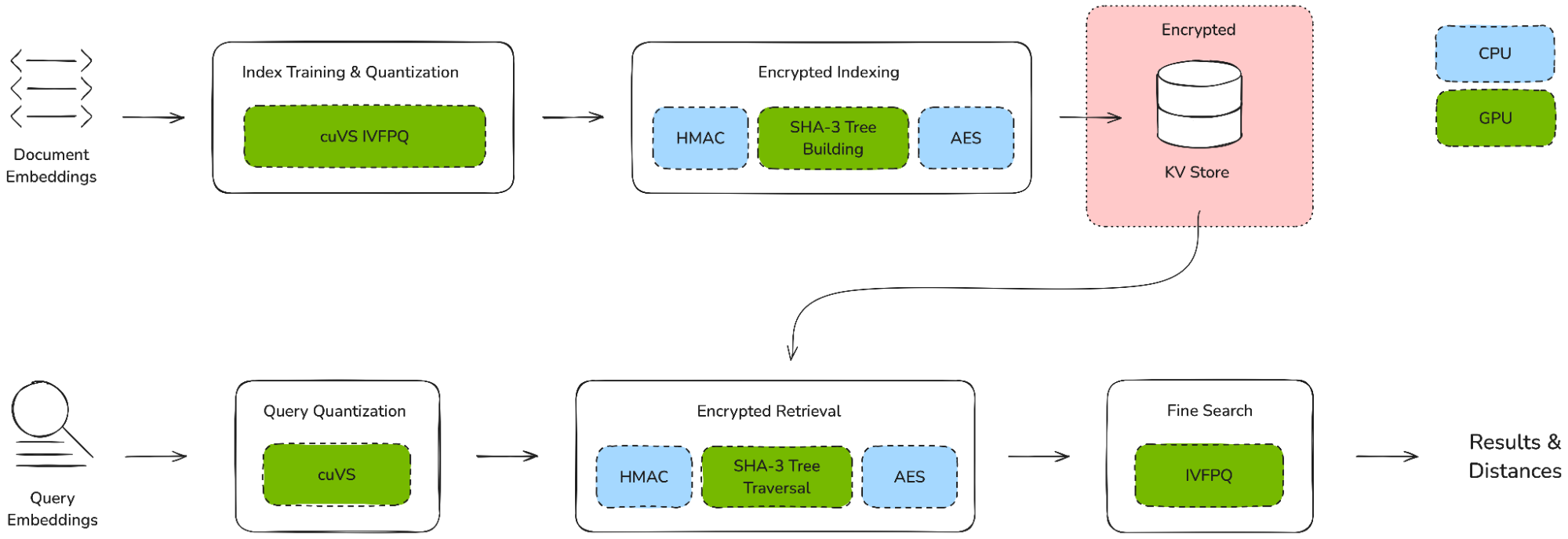
图 1.来自联合 Cyborg-NVIDIA PoC 的加密索引和检索流程
此 PoC 比较了 CPU 和 GPU 上的加密索引和检索性能。具体来说,我们分别用 cuVS 和 GPU 上的自定义 SHA-3 CUDA 内核取代了 CPU 上的 scikit-learnKmeans 和 hashlib。结果不言自明:我们在 GPU 上使用 cuVS 和自定义的 SHA-3 CUDA 内核,代替了 CPU 上的 tg_1Kmeans 和 tg_2。结果非常明显。
- 索引构建时间平均缩短了 47 倍,将索引向量嵌入所需的时间从几小时缩短到几分钟。使用 cuVS 加速的步骤在聚类模型训练和推理方面实现了 52.2 倍的更好改进。
- 检索也实现了显著改进:cuVS 加速部分的工作流在尽可能减少代码更改的情况下实现了 9.8 倍的性能提升。
- 与未加密的同类产品相比,启用 NVIDIA Hopper 机密计算模式进行索引和检索的端到端加密的边际成本分别为 1-2% 和 15-25%。这只是一个很小的开销,而 GPU 加速则抵消了这个开销。
从索引构建过程开始,图 2 显示了 CPU 上的总体构建时间与 GPU 的比较。
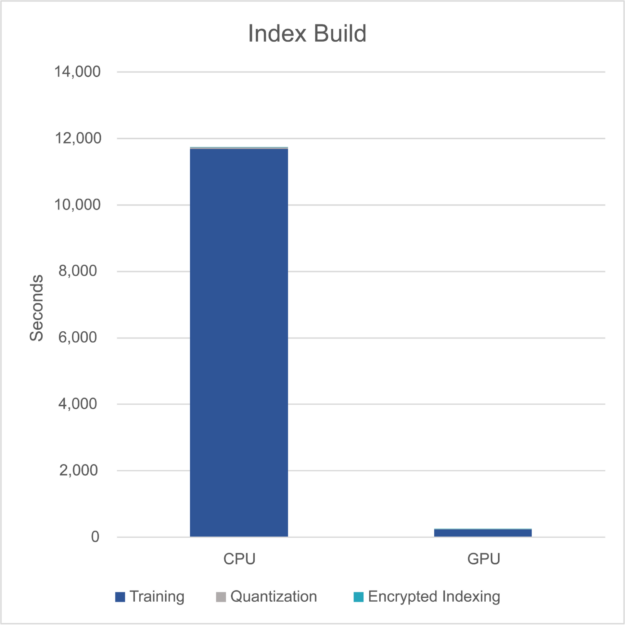
图 2.CPU 和 GPU 上的总索引构建时间
集群模型训练通常占据索引构建时间的主要部分。如果您不关注训练而只关注量化和加密索引,则 GPU 仍可显著加速(图 3)。
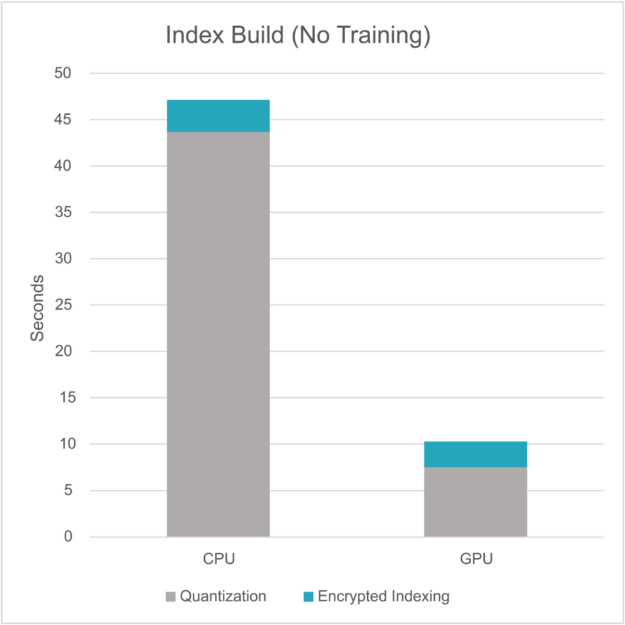
图 3. 在 CPU 和 GPU 上不进行模型训练的索引构建时间
最后,向 GPU 的转变使整个检索工作流实现了显著的改进(图 4)。
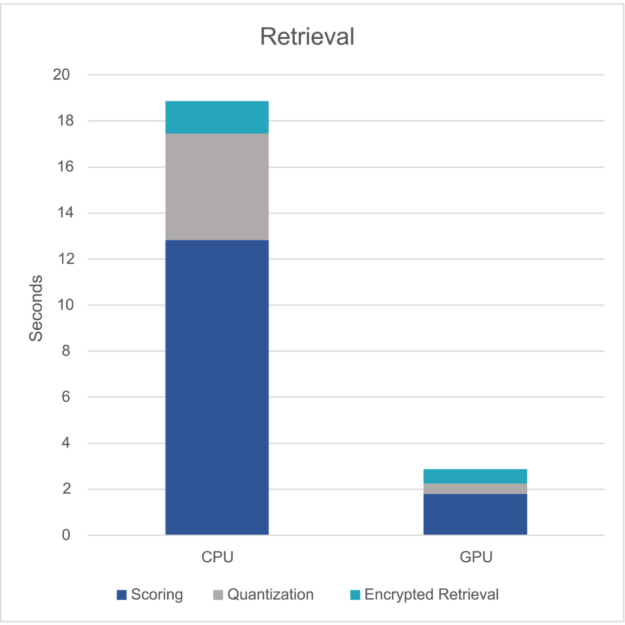
图 4.CPU 和 GPU 上的检索时间
所有时间均来自相同的索引配置(召回级别 > 0.95)。
采用 IVFPQ 指数类型是为了实现效率和准确性的最佳组合。















 6955
6955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









