







一、概述
神经网络的BP算法应用。
作业分为三部分,FP,BP,正则化。
BP算法的思想比较简单,但是实际应用起来还是很难的,想要自己推出所有公式实在需要好好花上一段时间去仔细琢磨。
我是通过看吴恩达的课程加上这篇博客加上西瓜书的对应部分才勉强弄懂整个流程是如何运作的。
当然,要完成本次作业,即是不是很懂整个流程也没有关系。

二、分析
1、Sigmoid Gradient函数
功能函数,用于求Sigmoid函数的导数。
十分简单,如下:
z1=sigmoid(z);
g=z1.*(1-z1);无论z是向量还是矩阵还是实数,都可以得到正确的结果。
2、randInitializeWeights函数
功能函数,用于对Theta矩阵进行初始化,都初始化为0会导致symmetry问题,但是又不能乱初始化,因此选择初始化为接近0的正数或者负数。PDF中有相应的函数,直接写上即可。没必要浪费时间。
3、nnCostFunction函数
最重要的函数,神经网络的主体函数,实现FP、BP、正则化。
返回代价函数以及每一个权重对应的偏导数。
首先是返回代价函数,不进行正则化。
公式如下:
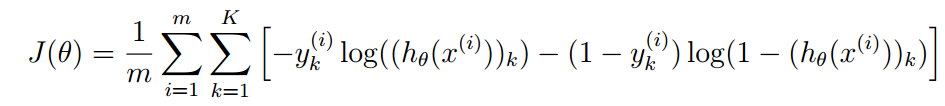
公式有点长,但是仔细观察可以看出,累加式部分与逻辑回归的代价函数几乎一样。
我们首先回顾一下该神经网络的输出:1个向量,向量中的元素范围都是(0,1),也就是预测向量,那么真实向量是什么呢?真实向量也是一个向量,向量中有K-1个0和1个1。
预测向量中的元素表示概率,真实向量中的元素表示是否。
在公式中,这个预测向量就是hx函数的返回值。整个公式的意义如下:
对比预测向量和真实向量中的对应元素,求出其误差值,使用log函数而不是直接减是为了使得J是凸函数。
然后累加对应元素的误差,求出误差和,这是整个预测向量的误差。
一共有m个测试用例,因此总的误差和就是m次累加。
最后除以m,求出平均值,也就是代价函数。
如果用代码实现该函数,首先要生成预测函数。
预测函数的实现是要使用FP算法的,输入测试样例,然后在神经网络中一步一步一层一层求出即可。
与上次作业的代码类似,因此可以直接使用以求出所有的预测向量。
那么真实向量怎么求呢?我们知道真实向量中元素1的位置对应的就是预测值,可以根据这一点构建真实向量:首先开一个全0向量,然后看y向量中对应的值,这个值作为下标,将其元素置为1。
如下:
X = [ones(m, 1) X];
z1=Theta1*X';%25*401 401*5000 --- 25*5000
A1=sigmoid(z1);
A1=[ones(1,m);A1];
A2=Theta2*A1;
A2=A2';
for i=1:m
y_=zeros(num_labels,1);
y_(y(i),1)=1;
J=J+(-log(sigmoid(A2(i,:)))*y_-log(1-sigmoid(A2(i,:)))*(1-y_));
end
J=J/m;这样我们就得到了神经网络的代价函数。
然后对代价函数加入正则化项,正则化项,简而言之,就是为了防止某些项太大造成的过拟合等,公式如下:

下面的就是正则化项,简而言之,就是求出权重中,除了偏移项以外所有权重矩阵元素的平方和。
除去偏移项对应的元素,我们可以另开两个矩阵存原来的Theta矩阵,然后使用
Theta1_(:,1)=[];
来除去对应的行(列)。
然后累加即可,如下:
Thetasum=0;
Theta1_=Theta1;
Theta2_=Theta2;
Theta1_(:,1)=[];
Theta2_(:,1)=[];
Thetasum=sum(sum(Theta1_.^2))+sum(sum(Theta2_.^2));
J=J+Thetasum*lambda/(2*m);注意矩阵元素的平方和,使用矩阵的点平方加上两次sum使用实现。
sum函数默认是求出对应矩阵每列的和,生成一个一行n列的向量,用两次就是求出一个实数了,看起来类似一种简陋的降维操作。
这样正则化也实现了。
然后是最难点:BP算法实现。其实PDF中的已经很详细了,一步一步按着来即可,千万不要耍小聪明,会吃亏。
BP算法的本质就是求偏导数,求出“每个权重矩阵元素对于整个误差的影响”,就是甩锅。
锅怎么甩是个大难题,让无关人士平白背锅肯定是不人道的,因此使用偏导数来表达。
我们知道,整个误差,也就是J,其自变量是神经网络的输出值,而不是每个具体的元素,因此直接求偏导求不出,需要链式求导,流程如下:
J→an→zn→an-1→an-1......→ai→zi→thetai;
由于J到thetai可能有多条路径,即thetai通过多种途径影响到J,因此需要对每条途径都求出,这样就是偏导数的公式。好在可以通过迭代的方式来简化操作,虽然说还是很麻烦,或许这就是为什么广泛使用的神经网络都是三层的原因。
代码如下,按步实现整个BP算法:
Tri1 = zeros(size(Theta1));
Tri2 = zeros(size(Theta2));
for t=1:m
%step1
a_1=X(t,:);%1*401
z_2=Theta1*a_1';%25*401 401*1->25*1
a_2=sigmoid(z_2);%25*1
a_2=[1;a_2];%26*1
z_3=Theta2*a_2;%10*26 26*1->10*1
a_3=sigmoid(z_3);%10*1
%step2
out_=zeros(num_labels,1);
out_(y(t),1)=1;
delta_3=a_3-out_;%10*1
%step3
%disp('size(Theta2)=');
%size(Theta2)
%disp('size(delta_3)');
%size(delta_3)
%disp('size(z1(:,t))');
%size(z1(:,t))
delta_2=Theta2'*delta_3.*sigmoidGradient([1;z_2]);%26*10 10*1 26*1->26*1
%step4
Tri1=Tri1+delta_2(2:end)*(a_1);%25*1 1*401->25*401
Tri2=Tri2+delta_3*(a_2');%10*1 1*26->10*26
end首先初始化Tri1和Tri2,用这两个矩阵存储Theta1和Theta2中对应元素的偏导数值。
接下来是整个流程:
第一步:求出a1,z1,a2,z2,a3,z3。
注意a是神经元的输出,z经sigmoid后是a,对a1,a2,别忘了加偏移项1。
最好注明每个向量的长度,否则debug会很麻烦。
第二步:求出第三层输出的误差向量。
很简单,用第三层输出a3减去真实向量即可。
第三步:求出第二层输出的误差向量。
公式如下:
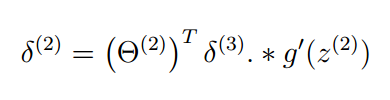
自己用链式求导可以得到对应的结果,但实在是太麻烦了,我只求出了几个元素的,整个矩阵的偏导没求。
注意一点,对a2要加偏移项1,但是z2没加,而要矩阵相乘的话,z2还差一个元素,于是在首位加1,这其实没什么影响,为什么呢?因为得到的delta2的第一行是没用的,喜欢在首位加几就加几。
第四步:求出偏导并保存。
公式如下:
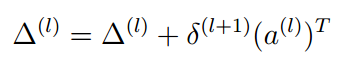
这里的l取值有两个,1和2。
直接代码实现即可。
最后,添加正则项,公式如下:

同样代码实现。
如下:
[a1 b1]=size(Theta1);
[a2 b2]=size(Theta2);
Theta1_grad = Tri1./m+[zeros(a1,1) Theta1_*lambda/m];
Theta2_grad = Tri2./m+[zeros(a2,1) Theta2_*lambda/m];这样就实现了整个函数。总的代码如下:
X = [ones(m, 1) X];
z1=Theta1*X';%25*401 401*5000 --- 25*5000
A1=sigmoid(z1);
A1=[ones(1,m);A1];
A2=Theta2*A1;
A2=A2';
for i=1:m
y_=zeros(num_labels,1);
y_(y(i),1)=1;
J=J+(-log(sigmoid(A2(i,:)))*y_-log(1-sigmoid(A2(i,:)))*(1-y_));
end
J=J/m;
Thetasum=0;
Theta1_=Theta1;
Theta2_=Theta2;
Theta1_(:,1)=[];
Theta2_(:,1)=[];
Thetasum=sum(sum(Theta1_.^2))+sum(sum(Theta2_.^2));
J=J+Thetasum*lambda/(2*m);
Tri1 = zeros(size(Theta1));
Tri2 = zeros(size(Theta2));
for t=1:m
%step1
a_1=X(t,:);%1*401
z_2=Theta1*a_1';%25*401 401*1->25*1
a_2=sigmoid(z_2);%25*1
a_2=[1;a_2];%26*1
z_3=Theta2*a_2;%10*26 26*1->10*1
a_3=sigmoid(z_3);%10*1
%step2
out_=zeros(num_labels,1);
out_(y(t),1)=1;
delta_3=a_3-out_;%10*1
%step3
%disp('size(Theta2)=');
%size(Theta2)
%disp('size(delta_3)');
%size(delta_3)
%disp('size(z1(:,t))');
%size(z1(:,t))
delta_2=Theta2'*delta_3.*sigmoidGradient([1;z_2]);%26*10 10*1 26*1->26*1
%step4
Tri1=Tri1+delta_2(2:end)*(a_1);%25*1 1*401->25*401
Tri2=Tri2+delta_3*(a_2');%10*1 1*26->10*26
end
[a1 b1]=size(Theta1);
[a2 b2]=size(Theta2);
Theta1_grad = Tri1./m+[zeros(a1,1) Theta1_*lambda/m];
Theta2_grad = Tri2./m+[zeros(a2,1) Theta2_*lambda/m];4、其他
我们可以使用checkNNGradients函数来验证我们的偏导数求的是否正确,还是很贴心的,很容易因为一个小错误而导致出现误差却不自知。正确的验证如下:
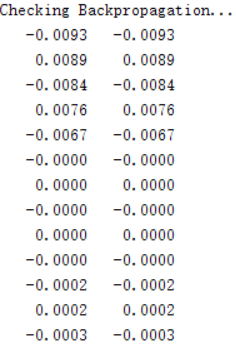
可以看出,几乎没有区别。
三、总结
本次课程不是很简单,需要仔细理解才能较好应用。通过这次作业,可以对神经网络有一个大概轮廓。















 824
824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









