









文章目录
关键信息
- DDIO: Intel Data Direct I/O 数据直接传输IO
- 仅在Xeon 处理器中可用
- 主要技术点: 它使 I/O 设备(如网卡)能够访问 CPU 的最后一级缓存 (LLC)。由于延迟、CPU 利用率和带宽较高,直接访问 LLC 可以显著提高性能。
- DDIO 功能对软件是透明的
- 第四代五代之后的志强处理器才支持
- 如何观测? 英特尔性能监控 (PerfMon) 事件和指标集来确定英特尔 DDIO 技术的使用是否以及使用效率如何
- 第 4 代之后英至强可扩展处理器实施了平铺布局,所谓平铺布局就是各种块被分组到平铺上,然后并放置在网格顶点中。然后网格顶点连接到网格互连,允许块通过公共网格结构互连
可见多个网格,每个网格下面有公共网格互联。 比如PCIe通过M2IOSF互联

- 通过网格与其他代理和块通信
- CPU core,包含本地 1 级 (L1) 和 2 级 (L2) 缓存。每个CPU的core都通过 mesh 同 非core以及LLC 通信。
- CHA/LLC是缓存控制器,可处理非内核中的所有连贯内存请求,并保持整个系统的内存一致性。
- 每个 CHA 都包含一个最后一级高速缓存 (LLC) “切片”。
- 内存地址在可用的 CHA 之间进行哈希处理,因此来自内核或 I/O 设备的请求将根据物理地址定向到相应的 CHA 单元。这意味着来自内核的 memory 请求没有固有的亲和性,以转到其共存的 CHA 或 LLC slice。CHA 是 I/O 分析和英特尔 DDIO 有效性的关键 PerfMon 观察点,这里计算 I/O 请求并观察套接字的 LLC 命中和未命中。
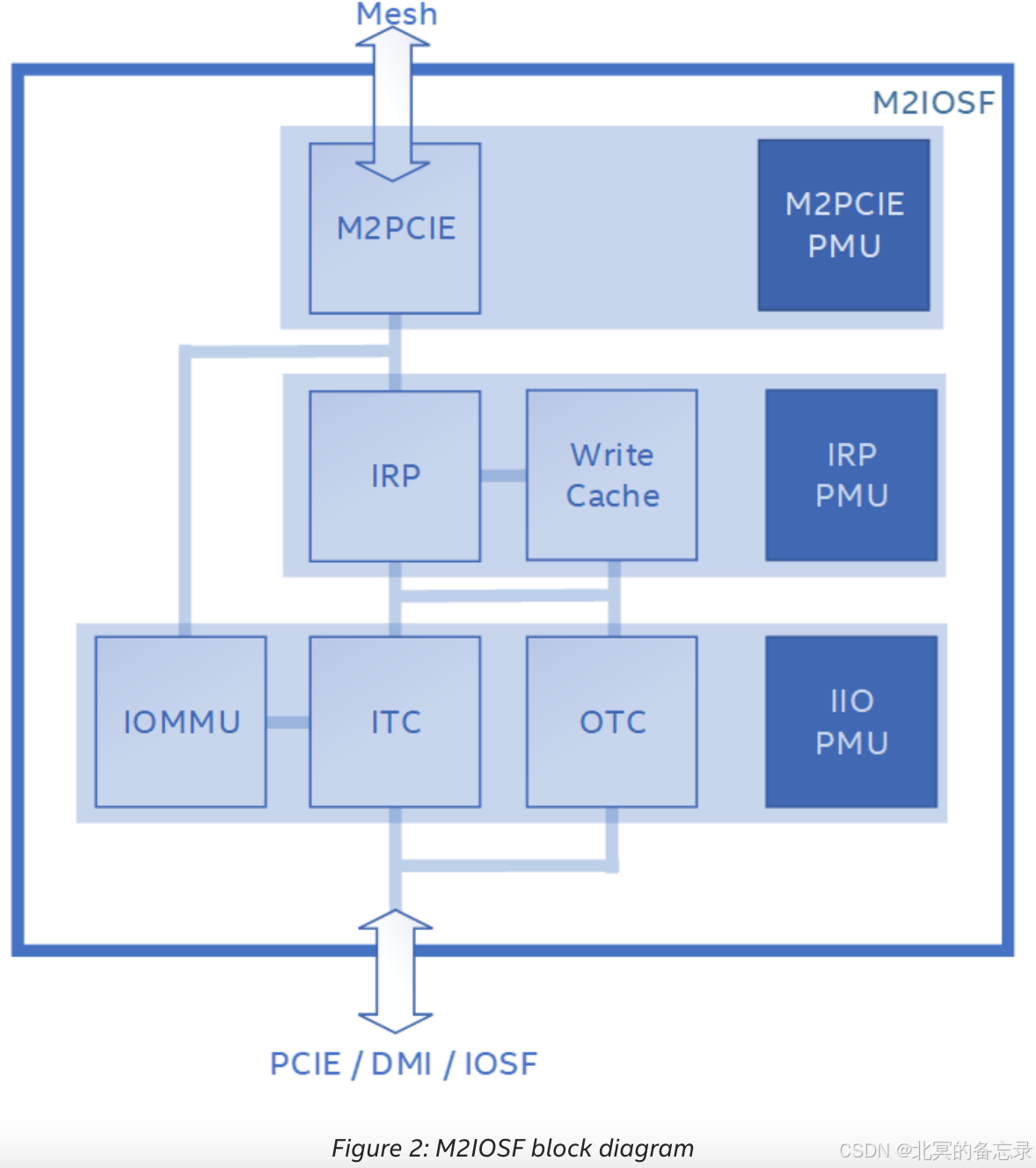
- M2IOSF:Mesh to I/O Scalable Fabric 连接到网格,是 CPU 和 I/O 设备之间的接口,通过 PCI Express 插槽连接或集成在芯片上。M2IOSF 是一个观察点,我们可以在其中计算每个 M2IOSF 块或 PCIE 设备的 I/O 请求类型。M2IOSF 包含多个带有性能监控单元 (PMU) 的子块。M2IOSF 为 Compute Express Link (CXL) 设备提供相同的桥接功能
- IIO:集成的 I/O 单元,由用于排队请求的入站和出站流量控制器组成;
它负责遵循 PCI Express 排序规则,并将 PCI Express 请求转换为 IRP 的内部命令,反之亦然。IIO PMU 提供每个器件的分辨率(高达 x4 分叉)。“inbound” 是指发送到 CPU(也称为上游)的 I/O 设备发起的请求,而“outbound”是指 CPU 发起发送到 I/O 设备(也称为下游)的请求。 - 在具有多级内存层次结构的系统中,对驻留在较高缓存层中的数据的访问比对 DRAM 的访问具有更低的延迟。在没有 Intel® DDIO 的系统中(Intel Xeon® 处理器 E5 系列和 Intel® Xeon® 处理器 E7 v2 系列之前®),入站 DMA 写入在系统内存中终止,从而导致数据使用者经历相对较长的延迟。使用 Intel® DDIO,入站写入在 CPU 的 LLC 中分配,使使用者能够更快地获取数据
- 在 Intel 架构中,设备发起的入站事务通过集成的 I/O 控制器,该控制器充当 CPU 的连贯域接口。M2IOSF 与 CHA 协商事务,CHA 还包含 CPU 的 LLC 缓存的切片。在此协商期间,在某些情况下,M2IOSF 可能会请求缓存行的临时投机所有权,如果可能,在事务期间保留它。Intel DDIO 事务的最大粒度为 1 个高速缓存行(64 字节),但允许小于 64B 的数据大小,这称为部分事务。M2IOSF 的任务是将较大的事务分解为缓存行粒度。
- CHA 检查缓存命中或未命中,并执行必要的一致性作,
- A high-level的入站 I/O 事务流
- I/O 设备启动入站读取请求或入站写入事务。
- M2IOSF 将交易分成 64B 块(不一定),并将交易转发给 CHA。
- CHA 检查缓存命中或未命中,并执行必要的一致性作,例如 snoops。在数据读取情况下,CHA 还负责从其当前位置(例如缓存代理、另一个套接字或内存)获取数据。
- 在数据读取情况下,CHA 将数据发送回集成 I/O 控制器。
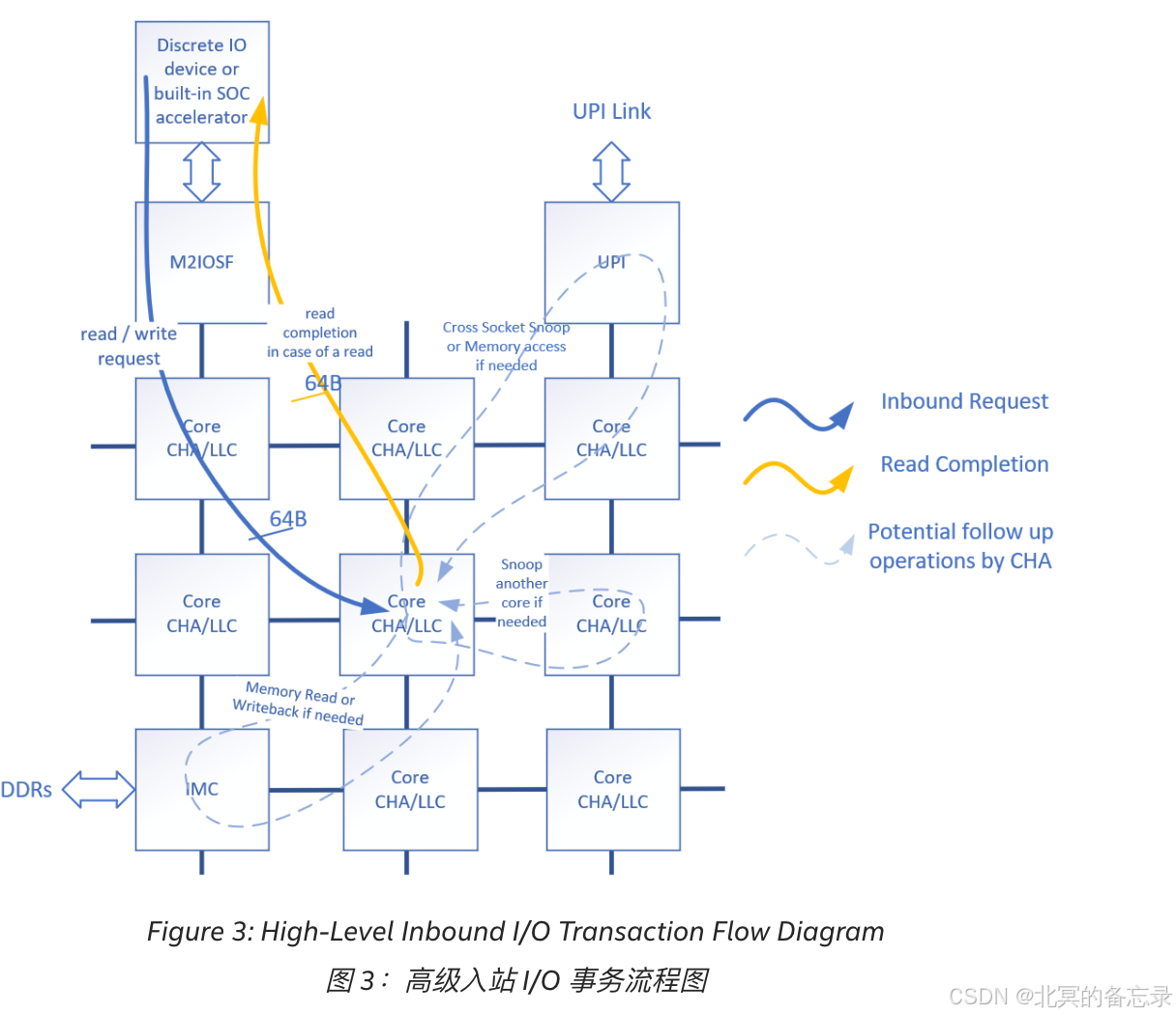
- 入站事务可分为读取或写入、LLC 命中或未命中以及完整或部分事务。写入可以进一步分为分配 (BIOS 默认) 和非分配。
Inbound Writes 入站写入概述
从 M2IOSF 的角度来看,入站写入包括两个阶段:所有权和数据回写。在所有权阶段,M2IOSF 使用 ITOM 或 ITOMCacheNear作码向 CHA 发送所有权请求,CHA 通过将目标缓存行的所有权交给 M2IOSF 并相应地更新 snoop 过滤器来做出响应。与非 IO作一样,将缓存行的所有权授予 M2IOSF 需要通过 snoops 通知缓存行的其他所有者,以遵循 MESIF 一致性协议使其副本无效。所有权阶段结束后,M2IOSF 将数据消息 MTOI 发送到同一个 CHA。CHA 在 LLC 中查找数据并确定是否需要维修 LLC 命中或 LLC 未命中。以下部分介绍了 CHA 如何处理 LLC 命中和 LLC 未命中情况。
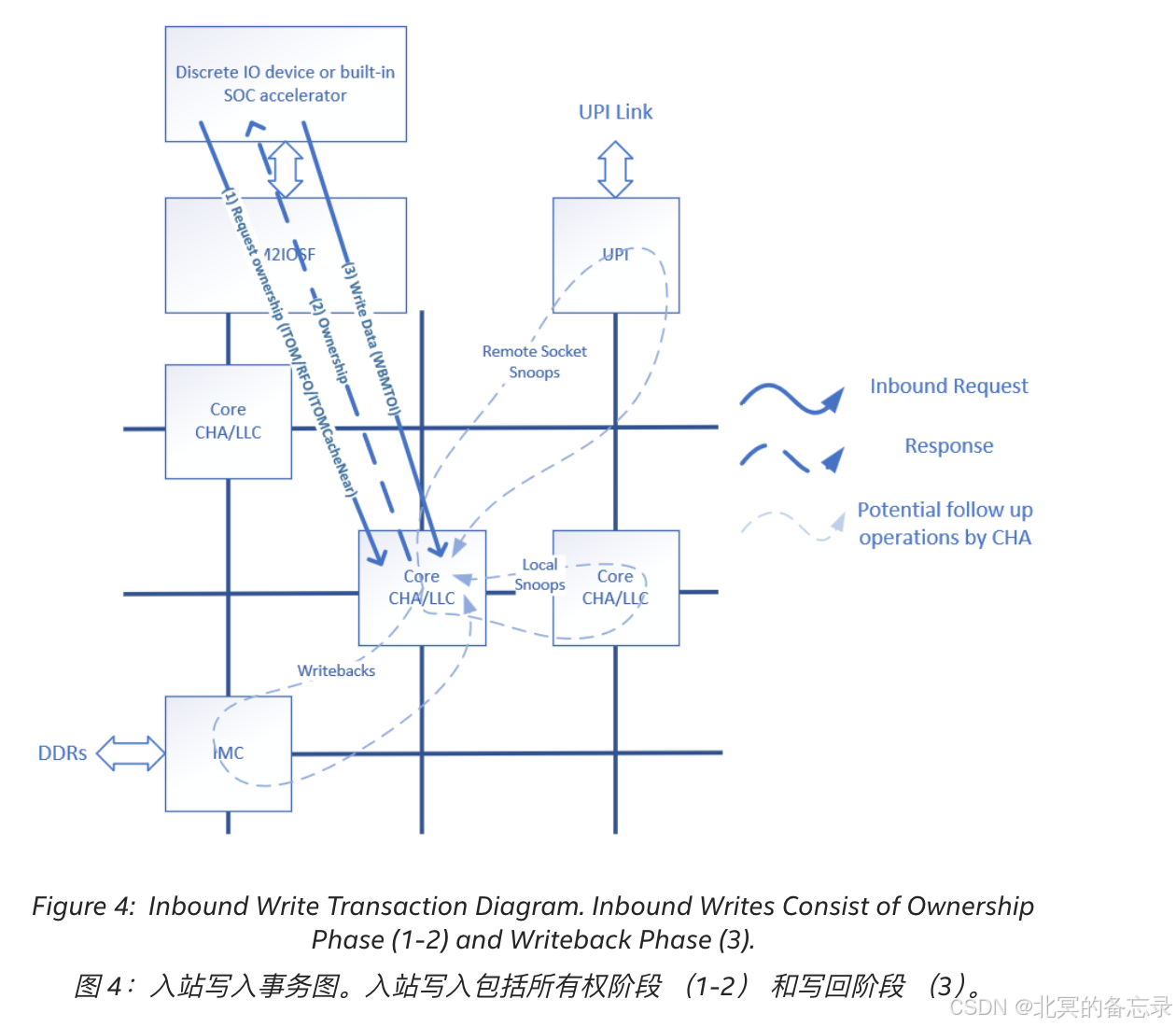
入站写入 LLC 命中
LLC 命中是入站写入最理想的结果,因为它通常会导致 CPU 为写入提供服务所产生的最低开销。如果 LLC 命中,CHA 只需更新 LLC 中的缓存行。对于完整的 cache line 事务,整个 cache 行将被新数据覆盖;对于部分缓存行事务,缓存行在 CHA 内合并。
虽然 LLC 命中是入站写入的最简单结果,但如果在其他缓存代理(例如内核或其他 CPU 插槽中的缓存)中也找到了数据的副本,则需要侦听作来使来自这些缓存代理的数据失效,以保持一致性。
还有Non-Allocating Inbound Writes非分配入站写入和IO LLC 方式写入
Inbound Reads入站读取
入站 I/O 读取事务也受益于 Intel® DDIO,因为它允许设备从系统缓存而不是系统内存中读取数据,从而减少延迟并节省内存需求。入站 I/O 读取请求本质上不会导致 LLC 分配。但是,他们必须遵循平台的一致性协议,该平台可能需要在窥探后将数据分配到 LLC 中。与入站写入请求一样,读取请求可能会命中或错过 LLC。
Inbound Reads LLC Hit 入站读取 LLC 命中
入站读取请求由 M2IOSF 发起,并针对由目标地址的哈希确定的特定 CHA。CHA 在 LLC 中查找数据,如果存在数据,则将完整的缓存行返回给请求者 M2IOSF。M2IOSF 不保留 cache 行的副本,因此不需要更新 snoop 过滤器。
Inbound Read LLC Miss 入站读取 LLC 未命中
如果 CHA 在 LLC 中找不到请求的数据,则必须在系统中的其他位置找到这些数据。这可以是内核的本地缓存,也可以是另一个套接字中的缓存,或者是系统内存。CHA 查找 snoop 过滤器以确定数据是否在另一个内核的缓存中可用,并读取内存以确定它是否存在于另一个套接字中。默认情况下,如果数据是从内存中读取的,则不会将其缓存在 LLC 中。
事件
当 CHA 单元收到来自代理(如核心或 I/O 设备)的请求时,它会将该请求放入其请求队列中,称为“请求表”(TOR)。与此 TOR 关联的一组事件提供有关该请求的信息,例如请求来自哪种类型的代理、请求类型以及缓存是否满足请求(缓存命中)或未满足(缓存未命中)。这些事件是 UNC_TOR_INSERTS 事件。
术语
-
TOR: “table of requests” (TOR)
-
LLC:last-level cache (LLC) : CPU的最后一级缓存
-
CHA:Caching and Home Agent: 缓存主代理
-
M2IOSF:Mesh to I/O Scalable Fabric: mesh到io的可扩展网络。 核心是F是网络,M2IO表明方向。 这里的Mesh指的是网卡互联的这个mesh
-
MESIF 是一种一致性协议。在 Intel 架构中,当涉及到缓存一致性操作时会用到该协议。
-
inbound和outbound: 是指入队和出队。“inbound” 是指发送到 CPU(也称为上游)的 I/O 设备发起的请求,而“outbound”是指 CPU 发起发送到 I/O 设备(也称为下游)的请求。为什么叫bound?表示“界限”或“边界”。在计算机领域,尤其是与I/O(输入/输出)操作相关的语境中,“bound”通常用来描述数据传输的方向,强调数据是从一个“边界”(如CPU)流向另一个“边界”(如I/O设备)。这个请求就像是被绑定了方向一样,是从 I/O 设备这个方向朝着 CPU 这个方向去的,就好像被一种方向的界限给束缚住了,所以用 “bound” 来形容它这种有明确方向性(从外向内,即从 I/O 设备向 CPU)的特点。
-
IIO:Integrated I/O unit:集成IO单元。由多个inbound and outbound traffic 控制器组成,主要用于queueing requests,缓存request。是把PCIe的请求转为IRP请求互转的。
-
IRP:IO to Ring Port unit: IO到ring port单元。有时称为缓存跟踪器,负责将 IIO 请求(来自 PCIe/CXL 或集成加速器代理)转换为网格请求,反之亦然。IRP 包含用于加速入站写入请求的本地写入缓存。此缓存不应与处理器 L1、L2 缓存或 CHA LLC 混淆,并且可以将其视为临时写入缓冲区。IRP PMU 提供每个 M2IOSF 分辨率,而不是像 IIO 那样按设备提供。
-
M2PCIE:Mesh 到 PCI Express 单元,桥接 Mesh 和 IRP。
入栈栈方式:
其他关键信息
- intel 志强系列
英特尔至强(Xeon®)处理器从1998年发展至今,经历了多个世代
2017 年推出第一代英特尔至强可扩展处理器(代号为 Skylake - SP),采用全新的 Mesh 网格式架构设计。
2018 年推出的第二代智能英特尔至强处理器(代号为 Cascade Lake),是在 Skylake - SP 基础上增强,新增支持傲腾 DC 一致性内存等。
2021 年推出的第三代英特尔至强处理器(代号为 Ice Lake - SP 或 Copper Lake),支持下一代机器学习加速、BFloat16 指令等。
2023 年推出第四代英特尔至强可扩展处理器(代号为 Sapphire Rapids,简称 SPR),采用全新架构,每路配备多达 60 个内核,内置加速器提升性能。
2023 年 12 月 14 日发布第五代英特尔至强处理器(代号为 Emerald Rapids),引入全新的能效核(E - core)架构。
2024 年 6 月 4 日:在台北国际电脑展上,英特尔推出了至强 6 处理器的能效核(E - core)版本,代号为 “Sierra Forest”。该版本采用了新的制程工艺,具有更高的机架密度、更多的内核数量,碳排放量大幅减少,能源效率得到提升。
参考:
https://www.intel.com/content/www/us/en/developer/articles/technical/ddio-analysis-performance-monitoring.html

















 1429
1429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









