







简介
半监督学习主要是研究如何在有标签和无标签的数据中学习,其目的是设计算法来满足既包含有标记数据,又包含无标记数据的情况,并理解对于这种混合数据下学习的差异性。很多时候,人工标记的数据是很少的,而且代价是很大的,为了改善在缺少训练数据情况下的有监督学习,可以使用半监督学习来利用未标记数据。这里,主要介绍几种半监督学习的算法,如self-training、mixture models、co-training、graph-based methods和semi-supervised support vector machines。半监督学习的成功是基于一些关键性假设的,所以具有一定的适用性。对半监督学习的研究主要有两个方面的原因:实际价值体现在构建更好的算法;理论价值体现在可以更好地理解机器和人的学习方式。
非监督学习任务主要包括以下三种:
- 聚类
- 异常点检测
- 降维
监督学习:
- 分类
- 回归
从字面意思看,半监督学习是介于有监督学习和无监督学习中间的一种机器学习方法。事实上,半监督学习是有监督学习或无监督学习的一种延伸,只是其中包含了一些附加信息。主要包括:
- Semi-supervised classification
这是有监督分类的延伸,训练数据包含 l 个有标签的样本和u 个无标签样本,通常情况下 l≫u 。半监督分类的目标是从有标签和无标签数据中训练一个分类器,使得分类器的性能优于只用有标签数据训练得到的分类器。 - Constrained clustering
这是无监督聚类的延伸,训练数据包含无标签样本和一些有监督的信息,如must-link约束,某些样本必须在同一个类别中;cannot-link约束,某些样本不能在同一个类别中;某些类别中样本数的限制。Constrained clustering的目标是获得一个相比于用无标签数据聚类更好的聚类。
除了上面两种无监督学习的方法,如基于有标签和无标签数据的回归、基于有标签数据的降维等。这里主要介绍半监督分类。
乍一看,似乎存在一个矛盾,即从无标签数据中学习预测器 f ,但
下图是一个简单的半监督学习的例子。每个样本只有一个特征,总共存在两个类别:正例和负例。
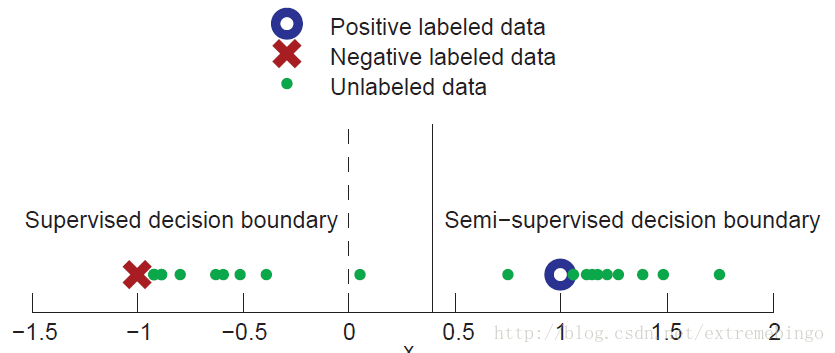
考虑以下两种场景:
- 在有监督学习中,给定两个有标签的样本 (x1,y1)=(−1,−) 和 (x2,y2)=(1,+) ,显然,决策边界的最佳估计是 x=0 :所有 x<0 的样本被划分为负类, x>0 的样本被划分为正类。
- 另外,给定了大量的无标记样本,即图中的绿色点。通过观察发现,他们形成了两个group。假设每个类别中的样本构成一个高斯分布,类中的样本围绕一个中心平均值。虽然没有标签,但是这部分无标记的样本可以给我们提供额外的信息。从图中可以看出,两个有标签数据并能很好地代表两个类,决策边界的半监督估计将在这两个group中间,即 x≈0.4 。
如果假设是正确的,则使用有标签和无标签数据可以得到一个更可靠的决策边界的估计。也就是说,无标签数据的分布可以帮助确定具有相同标签的数据所在的区域,然后通过少量的有标签数据来确定真实的label。
说明:对于一个特定的任务,盲目地选择一个半监督学习方法并不一定能在监督学习的基础上进一步改善性能。实际上,错误的假设会导致比监督学习更糟糕的结果。目前,主要的观点是半监督学习的表现取决于模型所提出的假设的正确性。
例:考虑一个二分类问题,每个类都服从高斯分布,两个高斯分布有部分重叠,如下图所示。真正的决策边界在两个分布的中间,如图中虚线所示。由于已知真实分布,可以根据每个高斯分布的概率密度来计算测试样本的错误率。
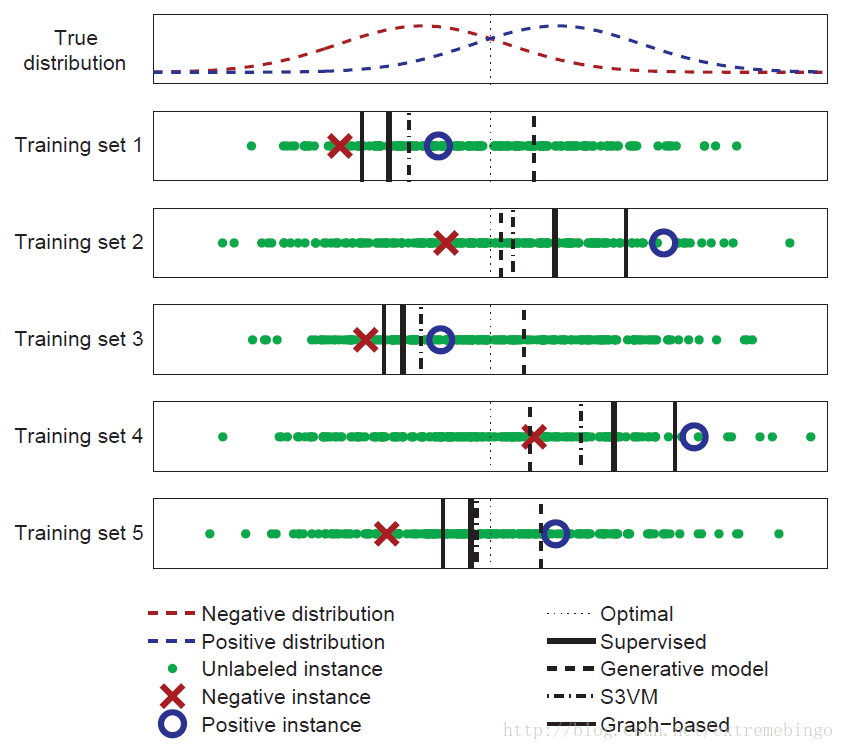
对于监督学习,忽略无标签数据,决策边界在两个有标记样本的中间,如Training Set 1所示,它远离最佳的决策边界,这是因为两个有标记样本是随机采样的。如果重新随机抽取两个有标签数据,决策边界将会发生变化,但是很可能还是远离最佳决策边界,如其它的粗实线所示。通常,期望学习到一个决策边界与真实的决策边界一致,但是,对于任何给定的标签数据,它都会有所偏差,我们称学习的决策边界存在高方差。
下面将介绍几种常用的半监督学习算法。
半监督学习算法
Self-Training Models
Self-training的特点是学习过程中,利用它自己对无标签数据的预测结果来学习。也就是先使用有标签数据来训练得到一个预测器,然后基于预测器来预测无标签数据,再将所有的有标签数据作为训练数据重新训练。
Algorithm 1. Self-training
输入:有标签数据 {
(xi,yi)}li=1 ,无标签数据 {
xj}l+uj=l+1
1. 首先,令 L={
(xi,yi)}li=1 , U={
xj}l+uj=l+1
2. 重复3,4,5,直到 U 为空
3. 使用监督学习从
4. 将
5. 移除
Self-training的主要思想是先基于有标签数据训练
Self-Training Assumption:无标签数据的预测值,至少是高置信度的那些,被认为是正确的。
当类之间能够很好地分开时,上述假设很可能是正确的。
self-training的主要优点是简单,并且是一个包装方法(wrapper method)。也就是步骤3中 f 的选择是任意的,既可以是简单的KNN算法,也可以很复杂的分类器。self-training虽然简单,但是,可能出现
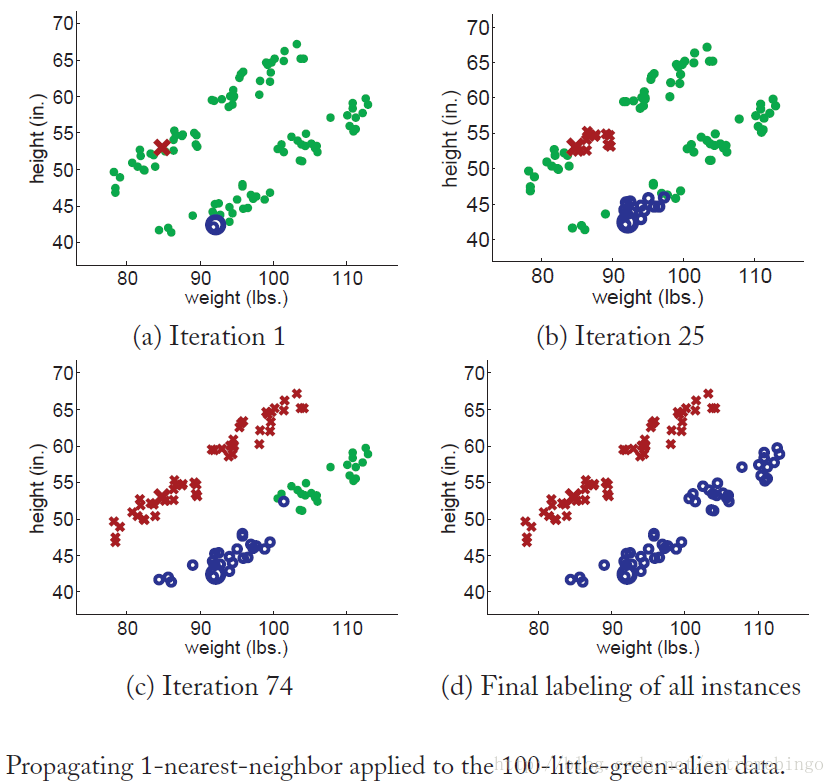
Algorithm 2. Propagating 1-Nearest-Neighbor

在上述算法中,每一次迭代只选择最靠近标签数据的无标签数据(其中的标签数据有一部分是通过之前的迭代得到的)。
如下图所示,有100个人的身高和体重数据,假设只有两个有标签数据(一男一女),98个无标签数据,现在需要按性别分类,这里采用Propagating 1-Nearest-Neighbor算法。从图中可以看出,使用该算法得到了很好的结果,这是因为满足不同的类之间能够很好地分开。
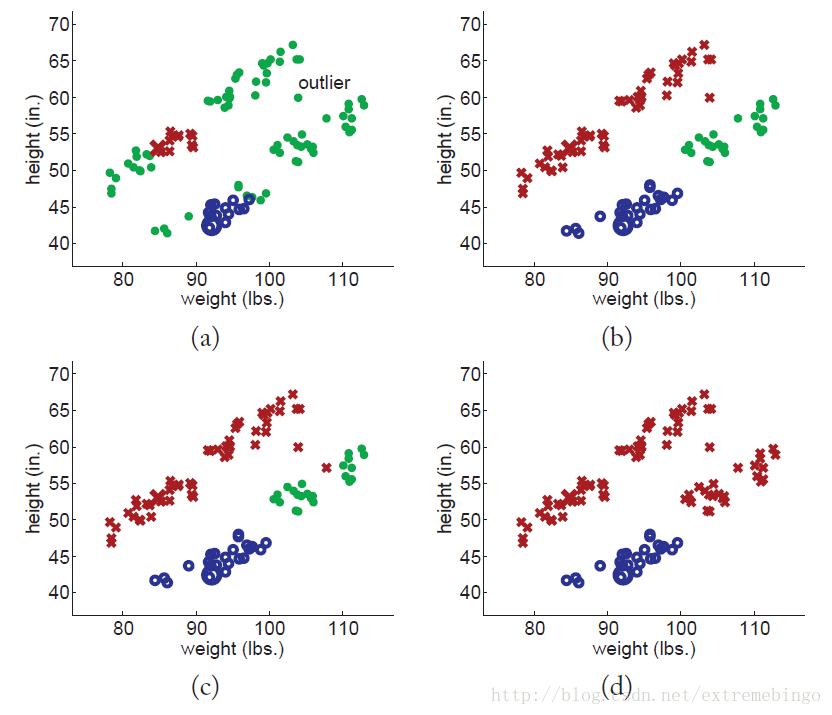
下面对数据做略微的修改,引入一个outlier,该outlier落在两个类的中间,如下图所示。由于outlier的存在,使得不同类别的数据能够很好地分开的假设不能满足,最终导致糟糕的结果。很明显,像propagating 1-nearest-neighbor这样的self-training方法对异常点是敏感的,会传播错误信息。避免这个问题的方法是考虑更多的其他信息,而不是只考虑单个最近邻点。
Mixture Models and EM
混合模型的思想是,如果已知每个类中样本的分布情况,可以把混合的分布分解到单个类中。
有监督分类的混合模型
假设训练数据来自两个一维的高斯分布,如下图所示。图中展示了 p(x|y) 的分布及一部分的训练样本,其中只有两个有标记样本。
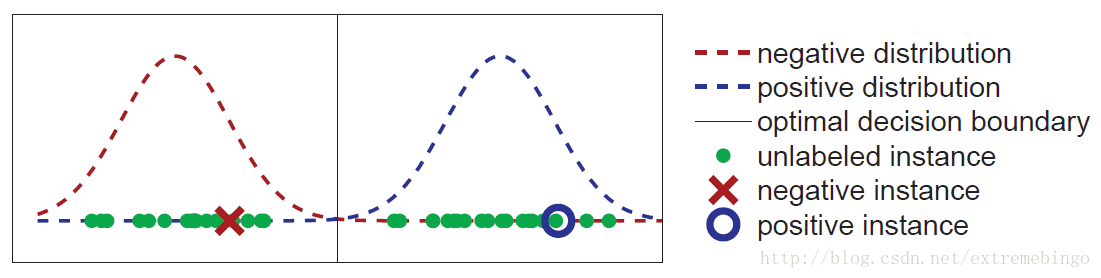
假设已知数据来自两个高斯分布,但其参数未知(均值、方差、先验概率)。使用有标签数据和无标签数据来估计两个分布的参数。在这个例子中,有标签的数据实际上是会产生误导的,它们都处于真实分布均值的偏右方。但是,无标签数据可以帮助确定两个高斯分布的均值。从计算方面考虑,需要选择参数,使得模型产生训练数据的概率最大。
x∈X 代表一个样本,需要预测该样本的label y 。使用概率的方法来最大化条件概率
使用贝叶斯公式计算该条件概率
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2307
2307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









