









树链剖分总结:
这几天也是学习了树链剖分,刚开始一脸懵逼,完全不知道在讲什么东西,现在终于理解了一点,感觉要想理解这个算法的话,其实结合着图题目加模板来看的话是最快的。
首先是概述(纯属个人瞎扯,扯错了请各位大佬指出,感激不尽)
树链剖分其实很像一类题目,就是将一棵树转换为线性结构,通过dfs序来遍历最终使得树上的结点成为线性的连续区间,然后利用一系列数据结构进行解题(弱鸡如我当前只会线段树),树链剖分其实就是将树上的边转换为了线性结构,但是转换的时候通过一些办法保证了时间复杂度。反正我他喵是不会证,
谈一下理解吧,个人觉得先讲明一些概念比较好,只讲比较关键的几个,首先是重儿子,u的重儿子其实就是以u为父结点的所有子结点中子树最多的那一个儿子节点,可以简单的理解为最重最复杂的那个儿子,重链呢就是把所有重儿子连接起来的链就是重链,废话不多说,上图,图是网上找的,侵删。
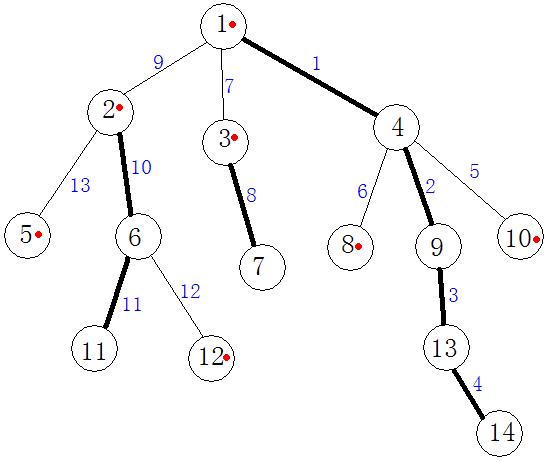
暂时先别管重链怎么得到的,可以看到上面的1 4 9 13 14 是明显的重链,从头连到尾,那么其他黑色边代表了其他的重链呢,其实就是对于每一个结点来说,都延伸了一个向下的重链,这样我们可以看到链上的编号是线性连续的,那么我们就可以利用数据结构来维护了。
接下来是比较关键的查询操作,查询某u,v结点间的所有边。
首先令 f1=top[u],f2=top[v];
首先判断u,v是否在一条重链上,(在此先默认是u的深度小于v,即v在u的下面),那么直接查询即可。若不在一条重链上的话,假设f1深度大于f2,那么先查询w[f1],w[u],然后令u=fa[f1],即向上爬一格。
拿上面的图举个例子,当我查询11,14的时候,我会先判断发现不在一条重链上,然后发现top[11]比top[14]大,接着查询 9 10 11号点,然后u爬到了1,接着发现1和14在同一条重链上,所以直接查询即可。
理解上面的思想后,接下来主要是通过模板和题目进行一些细节部分的讲解,模板包括两个dfs,我的模板用的是链式前向星写法,理解了这个vector写法应该不难,
以下是模板中各个数组的作用,懒得自己写了,用一下大佬的。
size[]数组,用来保存以当前节点为根的子树节点个数
top[]数组,用来保存当前节点的所在链的顶端节点
son[]数组,用来保存重儿子
dep[]数组,用来保存当前节点的深度
fa[]数组,用来保存当前节点的父亲
w[]数组,用来保存树中每个节点剖分后的新编号
以下贴代码,为spoj的Qtree,就是单纯的查询操作,也算是模板题了,通过这道题讲一下树链剖分应用部分的细节,
#include <iostream>
#include <cstdio>
#include <cstring>
#include <string>
#include <cstdlib>
#include <cmath>
#include <vector>
#include <queue>
#include <map>
#include <algorithm>
#include <set>
#include <functional>
#define pb push_back
#define lson rt<<1
#define rson rt<<1|1
using namespace std;
typedef long long ll;
const int N=10010;
const int INF=1e9+7;
int cnt,n,step,ans;
int dep[N],size[N],son[N],top[N],w[N],fa[N];
int head[N];
char s[20];
struct node //链式前向星
{
int u,v,w;
int next;
}edge[N<<1];
struct tree
{
int l,r,mid;
int ma;
}t[N<<2];
void add(int u,int v,int w) //建边注意cnt从0开始
{
edge[cnt].u=u;edge[cnt].v=v;edge[cnt].w=w;
edge[cnt].next=head[u];head[u]=cnt++;
return ;
}
void dfs1(int u,int fat,int de) //dfs1找出每个结点的重儿子,父亲结点,深度
{
dep[u]=de;fa[u]=fat;size[u]=1;son[u]=0;
for(int i=head[u];i!=-1;i=edge[i].next)
{
int v=edge[i].v; //当前结点所有的子节点
if(v==fat) //这里是因为无向边的问题
continue;
dfs1(v,u,de+1);
size[u]+=size[v];
if(son[v]==-1||(size[son[u]]<size[v])) //找出重儿子
son[u]=v;
}
return ;
}
void dfs2(int u,int tp) //dfs2将重链连接起来
{
top[u]=tp; //更新当前结点所在链的头结点
w[u]=++step; //更新u结点编号
if(son[u]>0) //优先连接重儿子形成重链
dfs2(son[u],tp);
for(int i=head[u];i!=-1;i=edge[i].next)
{
int v=edge[i].v; //从其他儿子开始往下重新连接重链
if(v==fa[u]||v==son[u]) //排除一些不可能的选项
continue;
dfs2(v,v);
}
return ;
}
void build(int l,int r,int rt) //线段树部分就不写了
{
int m=(l+r)>>1;
t[rt].l=l;t[rt].r=r;
t[rt].mid=m;
t[rt].ma=0;
if(l==r)
return ;
build(l,m,lson);
build(m+1,r,rson);
}
void pushup(int rt)
{
t[rt].ma=max(t[lson].ma,t[rson].ma);
}
void query(int p,int q,int rt)
{
if(t[rt].l>=p&&t[rt].r<=q)
{
ans=max(ans,t[rt].ma);
return ;
}
if(p<=t[rt].mid)
query(p,q,lson);
if(q>t[rt].mid)
query(p,q,rson);
pushup(rt);
}
void update(int pos,int flag,int rt)
{
if(t[rt].l==t[rt].r)
{
t[rt].ma=flag;
return ;
}
if(pos<=t[rt].mid)
update(pos,flag,lson);
if(pos>t[rt].mid)
update(pos,flag,rson);
pushup(rt);
}
void vs(int u,int v)
{
int f1,f2;
ans=-INF;
while(u!=v) //这里就是查询操作了 写法比较多 这只是其中一种
{
if(dep[u]>dep[v]) //首先判断深度
swap(u,v);
f1=top[u];f2=top[v];
if(f1==f2) //同一条重链上
{
query(w[son[u]],w[v],1);
v=u;
}
else if(dep[f1]>dep[f2]) //不在同一条重链上按照之前说的先查询深度大的链
{
query(w[f1],w[u],1);
u=fa[f1]; //结点向上爬一位
}
else //同上
{
query(w[f2],w[v],1);
v=fa[f2];
}
}
if(ans==-INF)
ans=0;
printf("%d\n",ans);
return ;
}
void slove()
{
build(0,step,1);
for(int i=0;i<n-1;i++) //注意这里的范围 因为用的链式前向星建的无向边
{
int x=edge[i*2].u; //下面每个下标 *2 保证边的不重复
int y=edge[i*2].v;
if(dep[x]>dep[y]) //判断深度
swap(edge[i*2].u,edge[i*2].v);
update(w[edge[i*2].v],edge[i*2].w,1); //更新边的权值
}
int p,q;
while(scanf(" %s",s))
{
if(s[0]=='D')
break;
scanf("%d%d",&p,&q);
if(s[0]=='Q')
vs(p,q);
if(s[0]=='C')
update(w[edge[(p-1)*2].v],q,1); //直接更新 注意*2
}
}
int main()
{
int QAQ;
scanf("%d",&QAQ);
while(QAQ--)
{
cnt=0;
memset(head,-1,sizeof head); //链式前向星初始化
scanf("%d",&n);
int u,v,w;
for(int i=1;i<n;i++)
{
scanf("%d%d%d",&u,&v,&w);
add(u,v,w); //建边 注意无向
add(v,u,w);
}
step=0; //编号初始化
dfs1(1,0,1);
dfs2(1,1);
slove();
}
}















 241
241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









