







文章目录
HPC行业简介
什么是HPC
HPC是高性能计算(High Performance Computing)
使用很多的处理器或者是某一集群中的几台计算机的硬件资源、计算系统和环境,将大规模的运算任务拆分成很多的小任务分发到各个服务器上并行计算,再将计算结果汇总成最终的一个结果。

这是一个关于华为云HPC解决方案的介绍:https://bbs.huaweicloud.com/videos/100690
在算力方面,如果说通用计算是家用小轿车,那么高性能计算就是方程式赛车。在算力上是高出通用计算很多的。
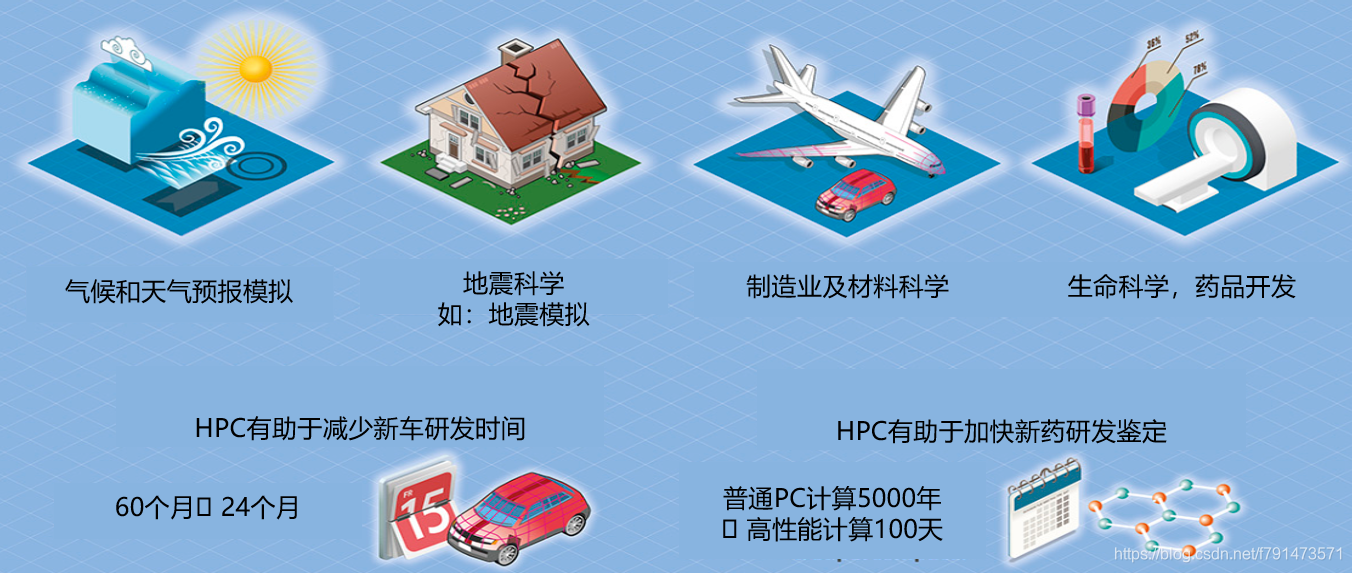
第二个是应用场景,比如政府投资的超算中心,企业的CAD、CAE,医疗上的基因测序等,还有石油地质勘探等方方面面都是HPC的应用场景。
HPC+大数据 = HPDA,像大数据能够提供体量巨大的数据集,那么对大体量的数据进行处理的时候就需要用到非常强大的算力,这也是HPC所能提供的。
HPC涵盖了3个方面:
计算:提供超强算力,可以使用除了一般的计算,还有英伟达p系列,FPGA等进行配合的异构计算加速。
存储:例如视频中提到的Lustre,这是一个开源的并行的分布式文件系统。
网络:由于高性能计算通常是组建集群的形式,在集群当中有多个节点,每个节点之间的任务调度、分配都会对网络提出一定的要求,例如高带宽、低时延。例如IB网络(无线带宽网络技术,现在快的有400GB/s,延迟在微秒级别)
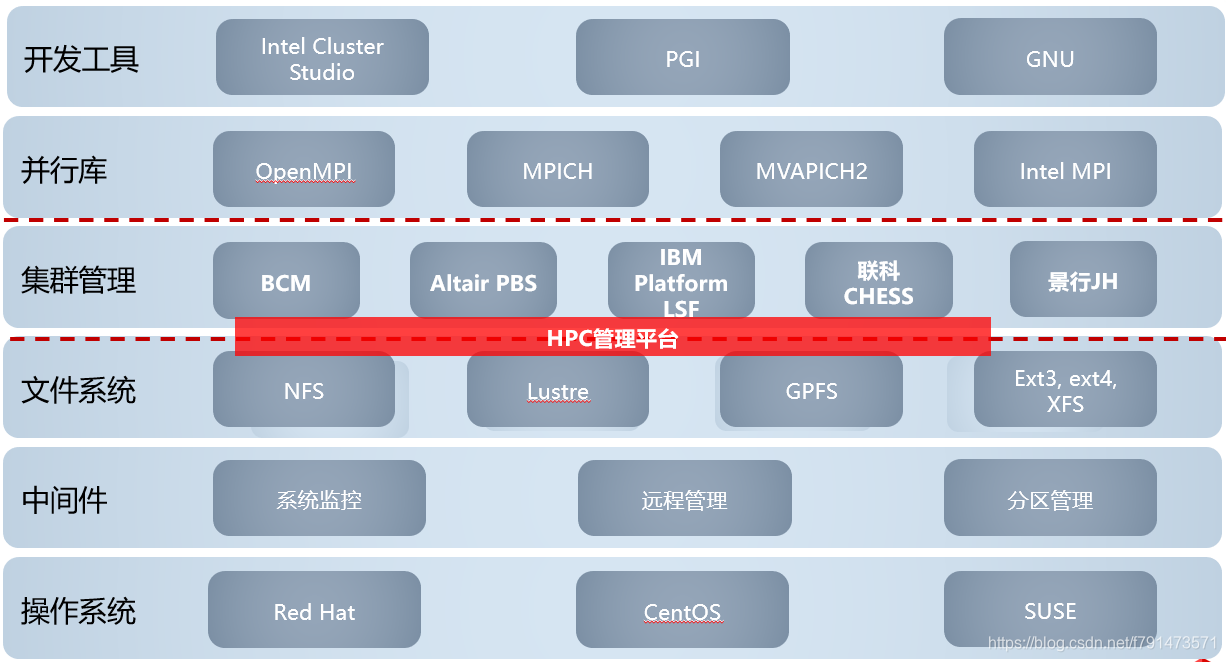
HPC关键技术
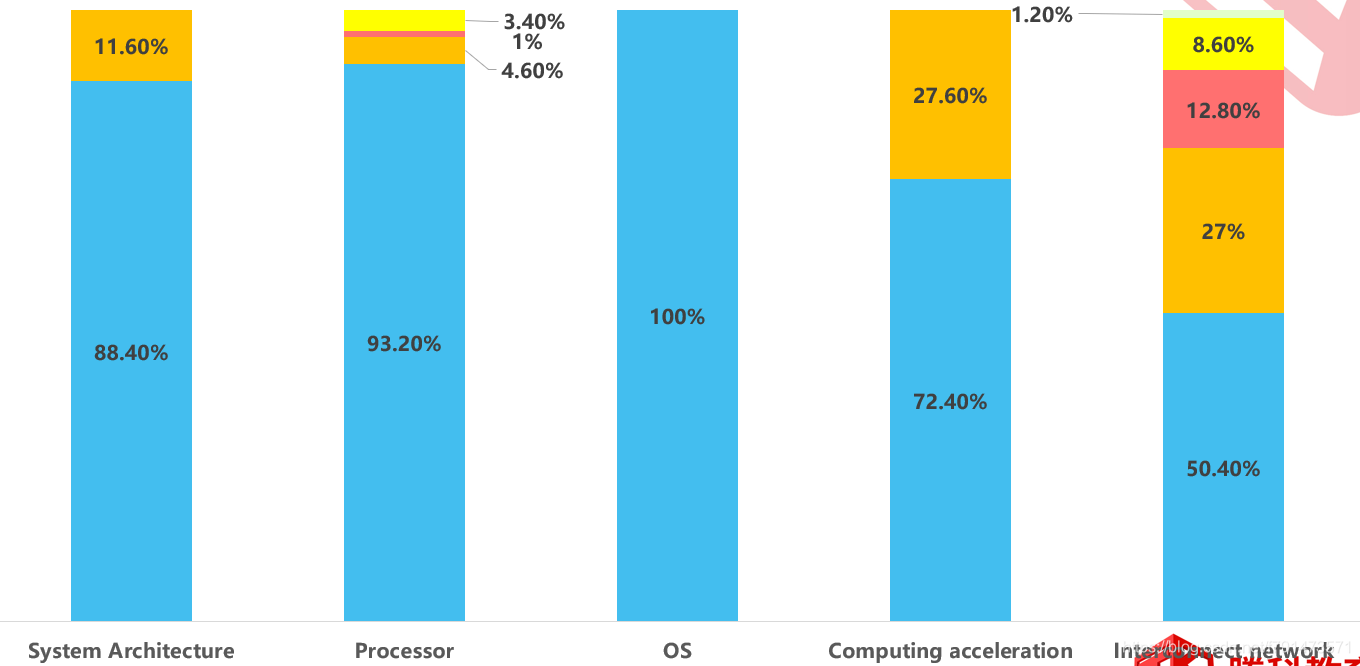
上图是HPC TOP500的统计情况
可以看到在系统架构层面,88.40%是Cluster这种集群的形式,另外的11.60%是MMP的形式。
MPP—是比较紧耦合的,比如说它一台服务器,它可以通过借助其他的CPU来做并行处理。节点数一般大于100以上
Cluster—比较松耦合,比如说这种架构的每个节点都有自己独立的CPU、内存、硬盘等等。节点数一般100以下
然后看处理器这块,在HPC场景下,主流的还是x86架构,当然像华为的KunPeng也是支持HPC相应的软件,不过份额比较少,处于3.4%这块。1%是SPARC,4.6%是Power。
操作系统部分,可以看到Linux占了全部,而没有Windows。因为我们说Linux的稳定性更强,而服务器的稳定性至关重要。
计算加速部分,传统情况下,CPU算力不足以应对复杂场景,所以我们可以通过CPU+GPU或者FPGA的一些方式来增强算力。图中72.4%是CPU,27.6%则是CPU+GPU,借助图形处理器来提升算力。
网络部分,由于每个节点之间需要相互通信,任务的协同处理,所以离不开网络设备,并且对网络的时延、带宽提出了很高的要求。目前50.4%是以太网,27%是IB网络,剩下还有一些其他的网络技术。
通过上图我们可以了解到当前HPC它涉及到哪些关键的技术。
HPC发展趋势

前面有讲到华为云HPC解决方案,所以HPC支持私有云、公有云还有混合云的部署
HPC云化主要有这几个特点:
1.弹性伸缩,可以根据业务需求进行灵活扩充减少。
2.按需付费,可以对资源进行灵活调度,客户根据当前经济条件、业务需求来购买,降低门槛、投资成本。
E级计算:指的是每秒可以达到的运算次数百亿亿次,图中所展示的是我国的神威太湖之光,它之前蝉联了3届HPC的TOP1。(当时它由48个机柜组成每个机柜有1024个CPU,每天耗电费用达到20万人民币。)
HPC主要应用场景的需求分布
主要从五个维度去看:浮点运算、内存带宽、网络带宽、网络时延、IO
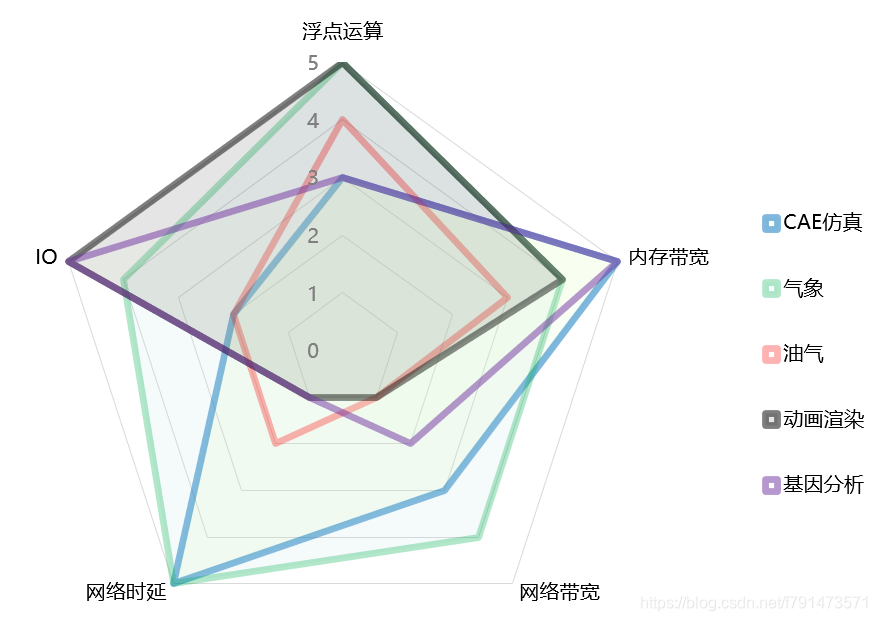
图中可以看到不同场景下对HPC的五个维度的指标也是不尽相同
由此可以分为内存约束型(大内存、高带宽)、计算密集型(高速CPU)、网络密集型怕(高速网络互联)、IO密集型(高带宽、大容量存储)
挑战和解决方案
HPC面临的行业挑战
- 计算需求持续增长:每个人产生的数据逐渐增多,那么业务分析、计算任务就逐渐增多,所以计算的需求也是持续增长的状态。
- 使用、部署和管理的门槛高:从上面讲的“太湖之光”也可以了解到,HPC是比较烧钱的,同样管理也需要专门的技术,培养管理人才也是一笔不菲的费用。
- 应用多元化:比如上面的图,在气象预测、石油天然气勘探、动画渲染等,他们对HPC各个维度的要求都是不相同的。
- 能耗费用持续增长:还是那个“太湖之光”例子,它每天的耗电量达到20万人民币,可以看出HPC的能耗费用是非常巨大的。
HPC解决方案架构
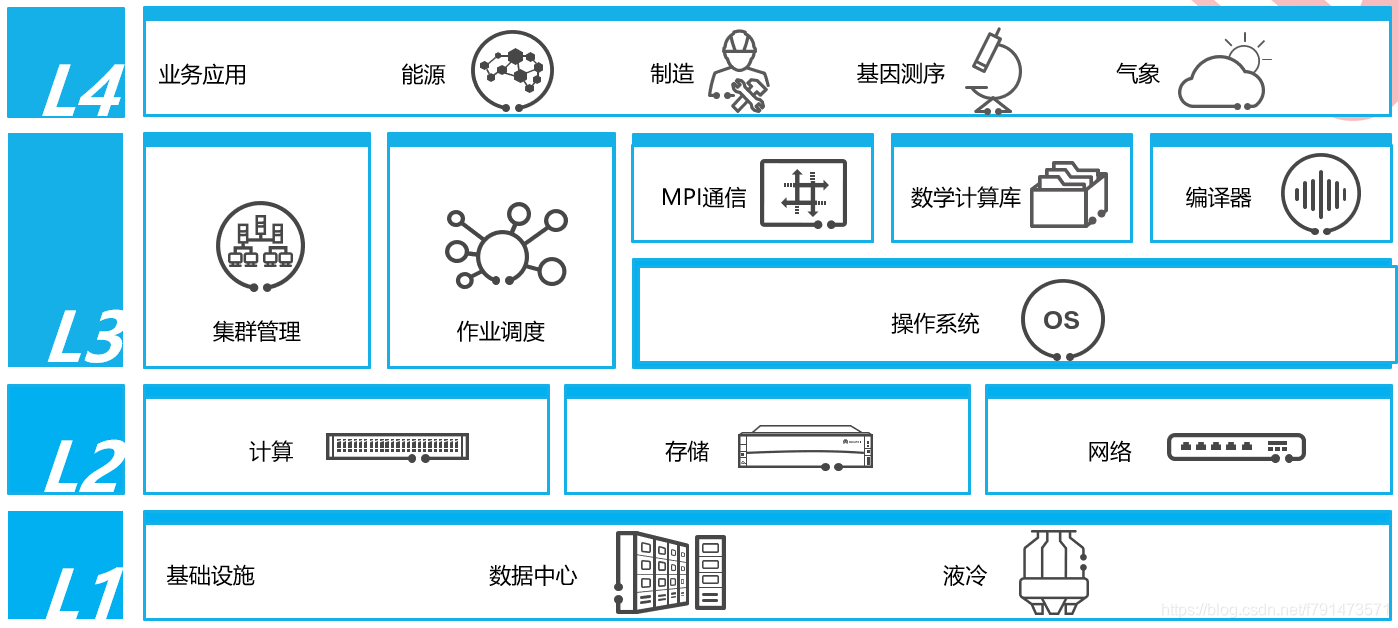
整个架构一共可以看作是四层
第一层是一些基础设施,比如模块化的数据中心,方便快速组装。还有像液冷,我们通常机房当中用的都是风冷。在HPC场景下由于服务器的功耗很大,产热也多,通过液冷来散热可以降低功耗,降低了功耗就降低了费用,从而降低了运营成本。
第二层是HPC实现的基础:计算、存储、网络。后面我们的解决方案也是围绕这三点展开。比如计算有哪些节点,存储有哪些类型,网络需要有哪些网络平面、它们之间如何互相组网。
第三层在底层基础设备、系统搭好的基础上,涉及到集群管理、作业调度。在操作系统之上,需要有消息传递的通信,各种运算的库,还有编译器等等。
第四层是偏向于行业的各种业务所需要使用的应用,这就我们前面有提到的能源勘探、CAD仿真,基因测序、气象预测等等。
总结:那我们主要关注的是在L2层,计算网络存储怎么去设计。
华为HPC解决方案能力
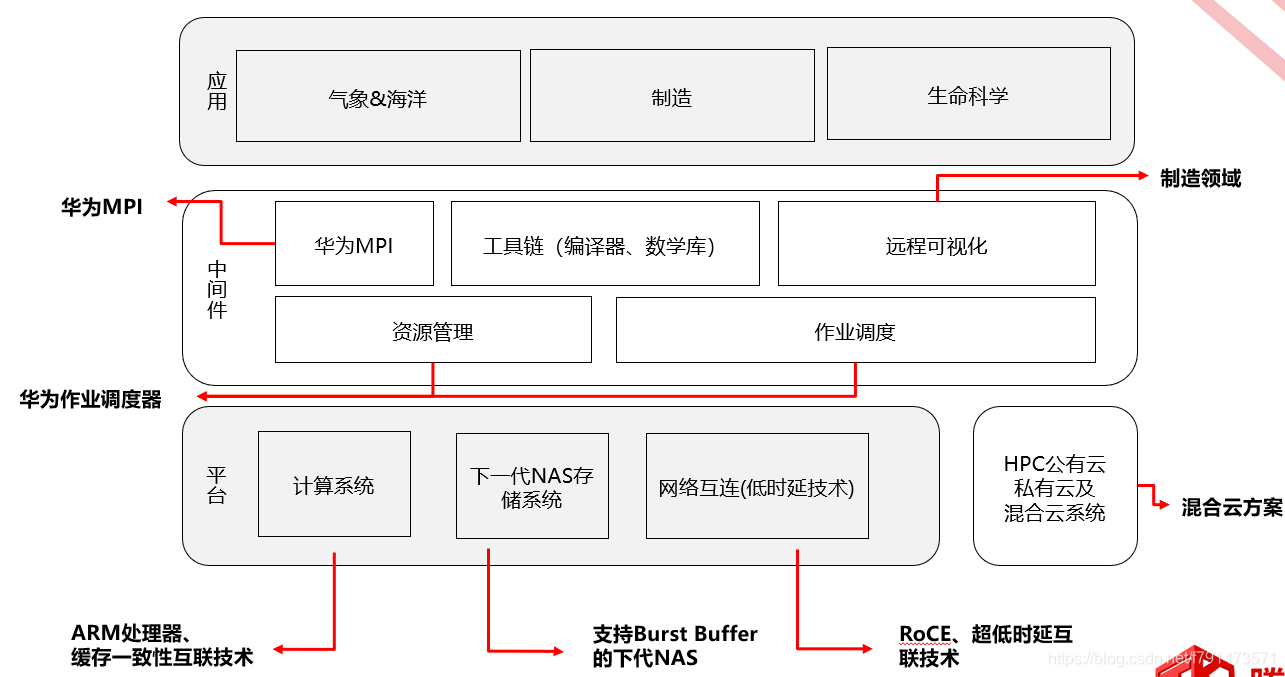
首先看底层平台
计算这一块,像ARM处理器也就是鲲鹏920,单个处理器可以提供8通道的内存,所以它的优势相比于x86在于大内存,以及缓存一致性互联技术。
存储这块,它支持Burst Buffer这种向量NAS文件系统。
(解释一下Burst Buffer,例如HDD存储容量大,但是性能差。SSD性能高,但是全用SSD部署成本很高。Burst Buffer,在计算过程当中我们使用性能较高的硬盘(SSD)组成一个缓冲层,那么计算都在都在这种高性能缓冲层当中进行。当计算得到最终结果,再将数据落盘到性能较差、容量较大的硬盘当中(HDD)。)
网络这块,需要低时延就会用到像RoCE、IB(无限带宽技术)等这些技术
(RoCE—允许通过以太网使用远程直接内存访问(RDMA)的网络协议)
同时也支持公有云、私有云、混合云的部署方案
然后第二层中间件
在这一层,华为有自己的MPI和作业调度器。在Taishan服务器上也支持其他一些开源的通用的工具,还有编译器、数学库这些。
第三层就是一些业务应用,涉及到气象预测、工业制造、生命科学这些。
总结:华为HPC的解决能力主要体现在L1和L2当中,L3层是和商业合作伙伴相关的。
比如在计算这边,就可以售卖华为泰山X6000这些高密服务器或者是RH系列的服务器。
目前HPC解决方案大部分是基于x86架构的,那么华为的泰山服务器是支持和x86混合部署的,业务一样可以正常运行、互相兼容。
存储这边,华为有自己的Oceanstore系列企业级的存储。
网络这块,华为也有自己的交换机,例如CE系列交换机、S系列交换机。
HPC硬件平台通用架构
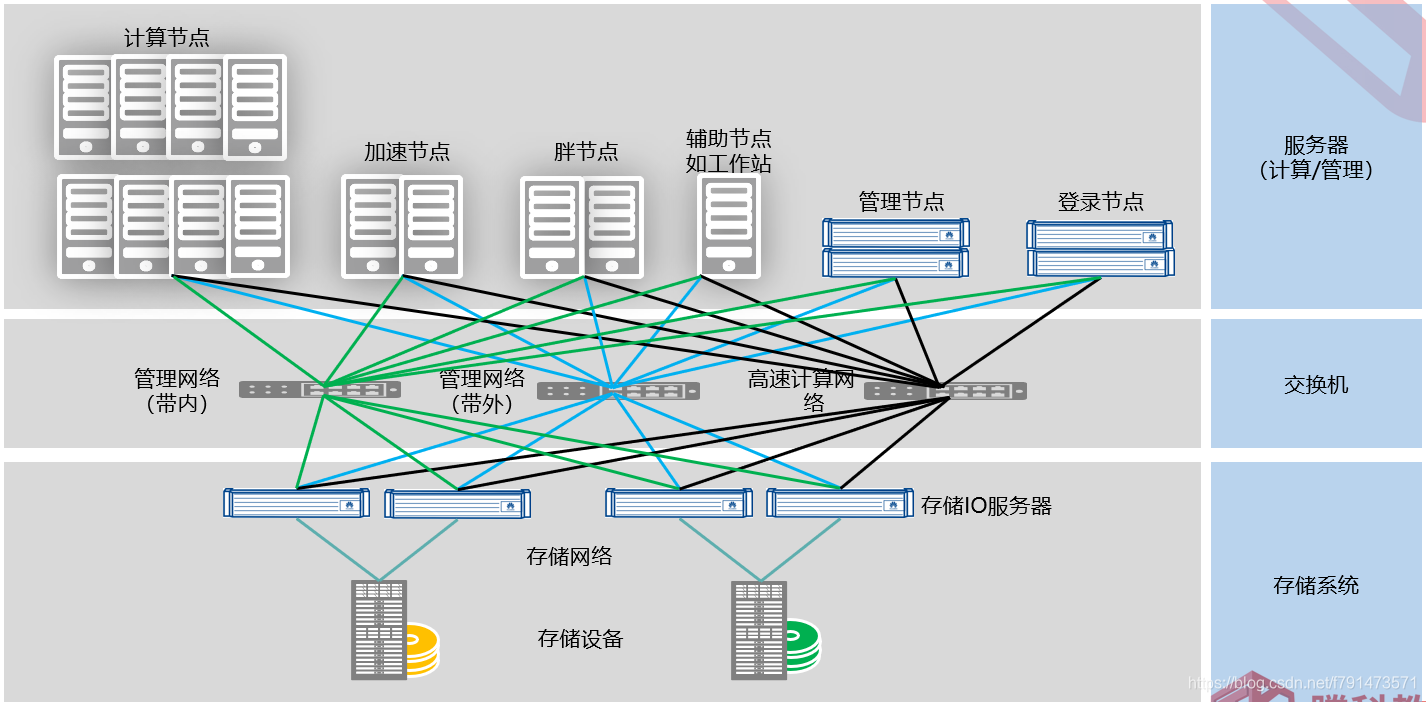
如图所示
主要也是从三个方面去看
计算、存储、网络
计算当中主要包括以下节点:
计算节点(瘦节点:负责一般计算)
胖节点(具有很高的CPU和内存,例如华为的X6000高密服务器)
加速节点(例如对图像处理的场景下,可以在服务器上插GPU卡来进行应用加速。)
辅助节点(如工作站)
登录节点(如客户端)
管理节点(集群之间需要进行管理)
网络部分,主要分为三个网络平面
高速计算网络:计算平面,用于各个计算节点之间相互通信(就像一个小组内的人员要互相沟通,任务完成的进度之类的。)
存储网络:存储平面,HPC有专门的存储系统,那么集群当中的节点都需要与存储设备进行相互通信,因此需要搭建一个存储网络。
管理网络:管理平面,整个集群之间资源的调度,任务的安排部署都是由管理平面来做的。
管理平面实际上分为两个:
一个是带内的(负责集群间任务协调、分配、管理的平面)
另外一个是带外的(可以通过iBMC进行带外管理,比如上下电等操作)
这样将管理平面分为带内和带外的,管理网络系统和业务系统不共用同一个平面。当业务系统出现故障,管理人员还可以通过带外的管理网络—也就是iBMC登录去登录iBMC的控制台来管理服务器(不然就去需要跑去机房找相应的服务器进行操作了)。(冗余保护的作用)
存储系统
支持NAS、华为Oceanstore9000以及开源的Lustre(行分布式文件系统,通常用于大型计算机集群和超级电脑,目前大部分HPC采用的文件系统都是Lustre文件系统)
总结:以上就是计算、网络、存储,三层的应用架构。
业务流程:(图同上)
第一步安装软件,准备上传数据进行计算。(登录到登录节点上传需要计算的数据,数据上传到管理节点)
第二步,管理节点根据作业调度器分配到计算节点进行计算
第三步,如果在计算的过程当中,需要存储当中的相关数据,那么就需要通过存储网络到存储设备中,拿到相关的数据再返回。
第四步,计算完成后的数据存放在存储设备当中,用户可以从登录节点访问存储获取计算结果。
性能指标
系统效率 = Rmax/Rpeak,(Rmax-实测最大值,Rpeak-理论峰值)
常用组件和技术
计算部分
华为服务器产品
TaiShan服务器
TaiShanX6000,高密服务器,非常大的内存、CPU,适合HPC场景。
TaiShan2280,通用服务器,
TaiShan5280,偏向于存储密集型
鲲鹏920
主要提升在于内存带宽,因为920支持8通道。(一般intel的芯片是6通道的)
所以说,鲲鹏芯片的内存非常大,像HPC场景都需要很大的内存空间,这是920的一个很大优势。
X6000高密服务器
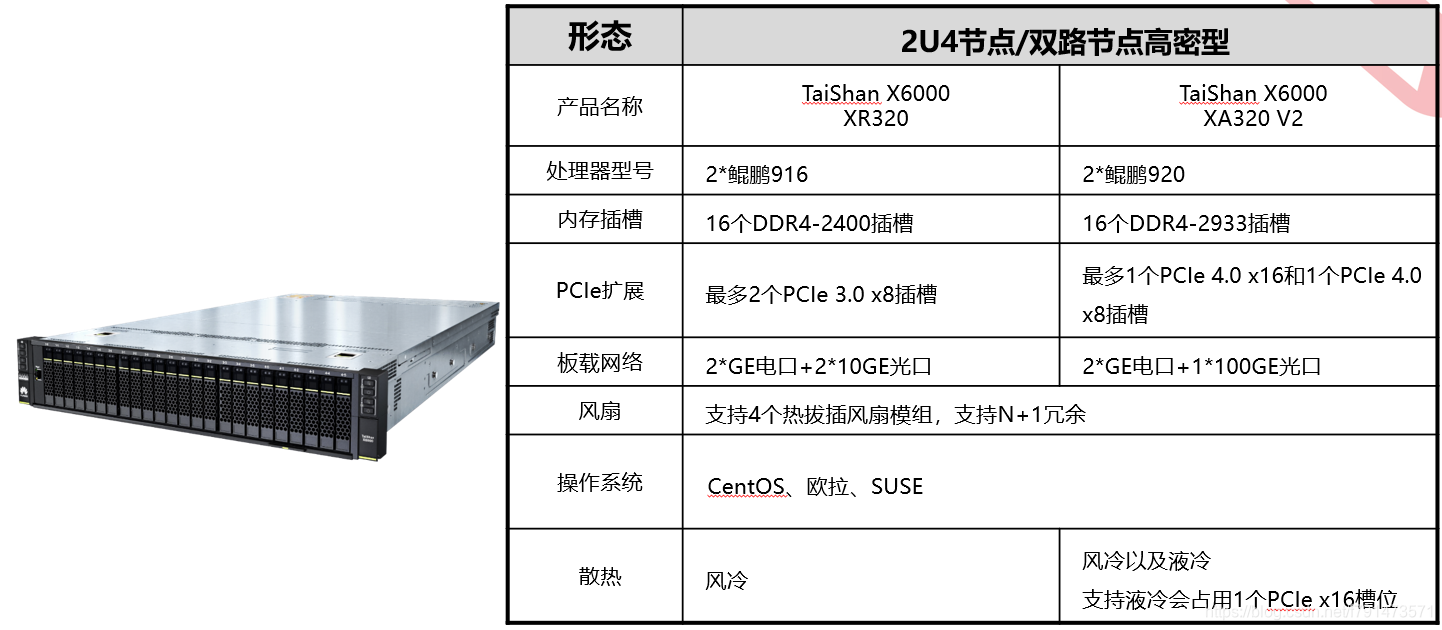
有两种不同型号,其处理器型号不同,PCIe扩展槽不同,还有就是散热的模式不同。
解释一些词汇
风冷:机房当中空调的风能散热
液冷:能够更好的降低能耗,就是通过一个接口让冷水从服务器内部通道走一圈,带走热量
(华为液冷解决方案视频https://e.huawei.com/cn/videos/cn/older/201412101742)
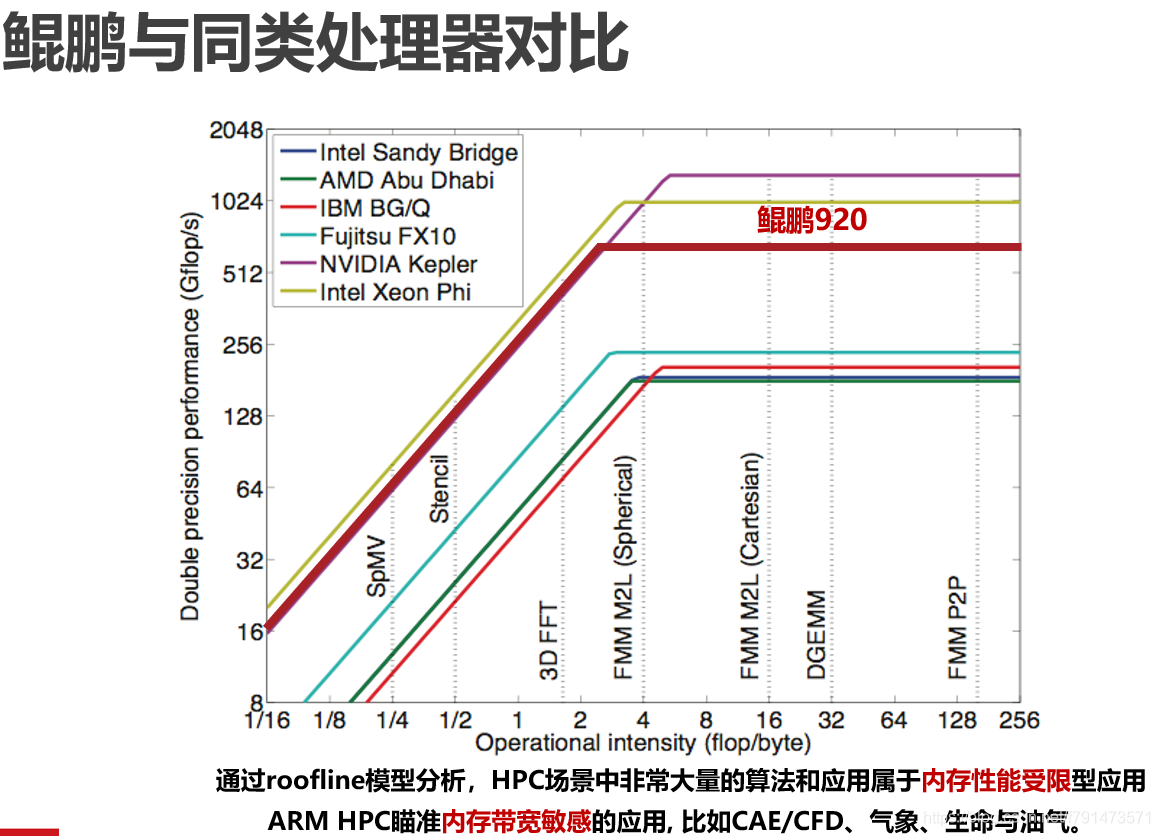
上图主要表达的是,鲲鹏920芯片,主要针对的内存带宽敏感型的应用,例如CAE、气象、油气等等。这也是得益于大内存,8通道的特点。
而且HPC场景下很多应用都是属于内存受限型的,即内存限制了业务。所以说鲲鹏的一些处理器就比较适合。
这里与x86架构下,intel的一款处理器做对比
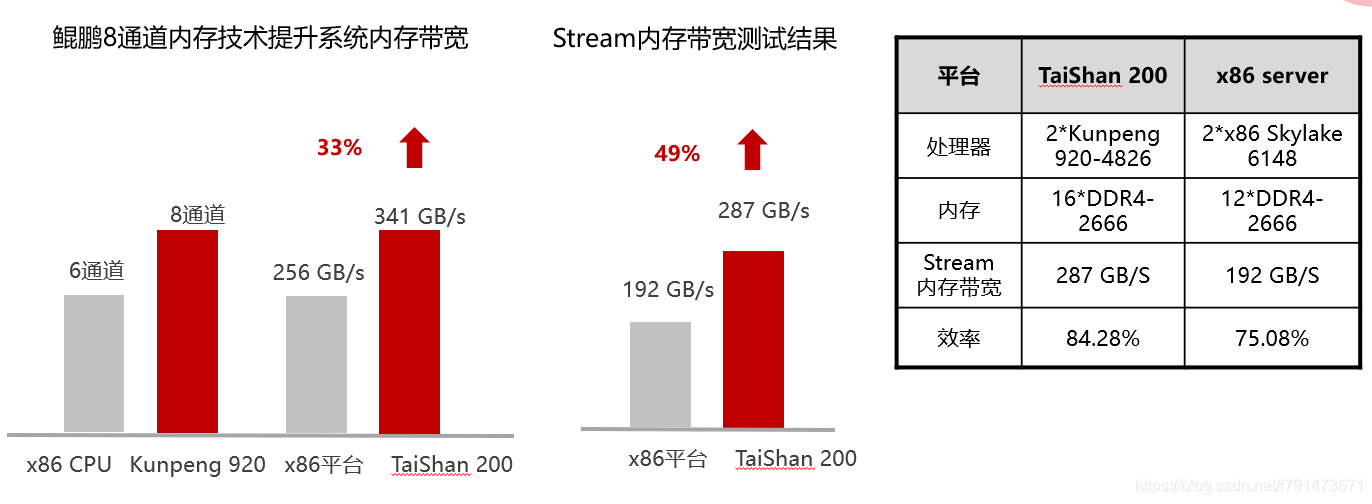
可以看出,8通道相比于6通道而言,对内存带宽的提升是非常明显的。
以上主要是计算部分
网络部分
在HPC场景下, 由于集群之间需要相互通信,所以对网络的带宽和时延要求是比较高的(应用之间带宽>40Gbps,时延<10us微秒)
现有的TCP/IP软硬件结构无法满足该需求

从这张图上看,数据在传递通过TCP/IP协议进行传输。
首先需要拷贝到OS中进行数据封装,然后再传输到网卡上,通过网卡发送到网络。
包括网络转发也存在一定的时延。
然后到目标主机,也要过网卡的Buffer(缓冲器)当中,然后到OS,再解封装到应用当中。
如何解决?
RDMA技术(Remote Direct Memory Access)
远程直接内存访问

前面有讲了传统的模式,这里不再赘述
RDMA模式
对数据包的加工都在网卡内完成。因此就跳过了操作系统,直接把数据发送到网卡内,少了应用内存与内核数据之间的交互,所以速度上更快,时延更短。
那么RDMA的体系架构主要有三种
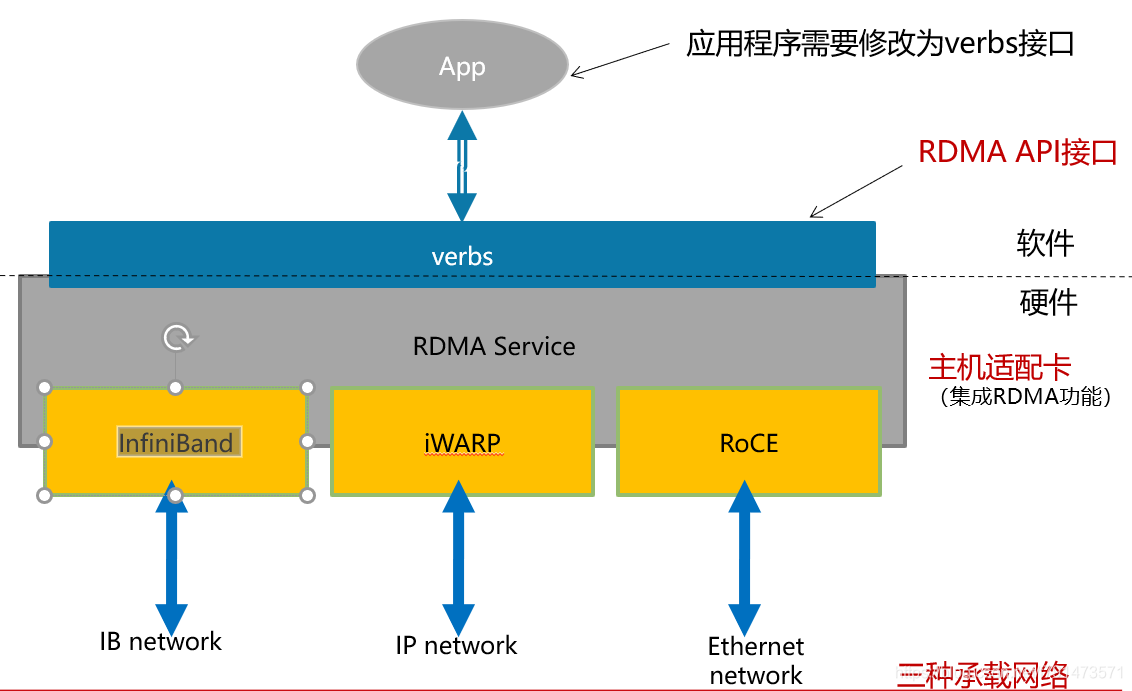
IB网络(基于无限带宽技术,这种网络有很高的带宽(100Gb/s以上)和非常低的时延(毫秒级))
后面两种是基于以太网的,iWARP—基于传输层的。RoCE分为两种v1和v2,v1作用在数据链路层,允许在同一个广播域内进行相互通信。v2作用在网络层,可以路由。
HPC高速网络拓扑
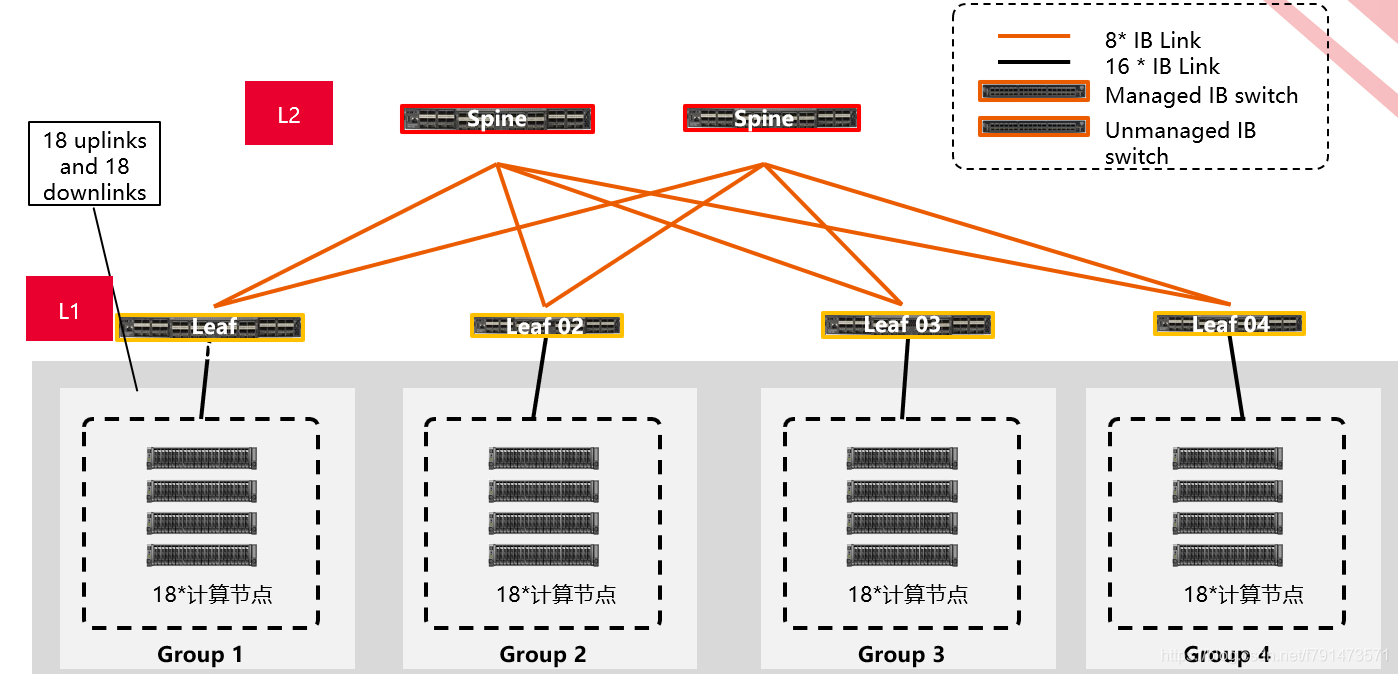
类似于上图,采用Spine-leaf架构,可以进行横向的扩展延伸,方便管理。
存储解决方案
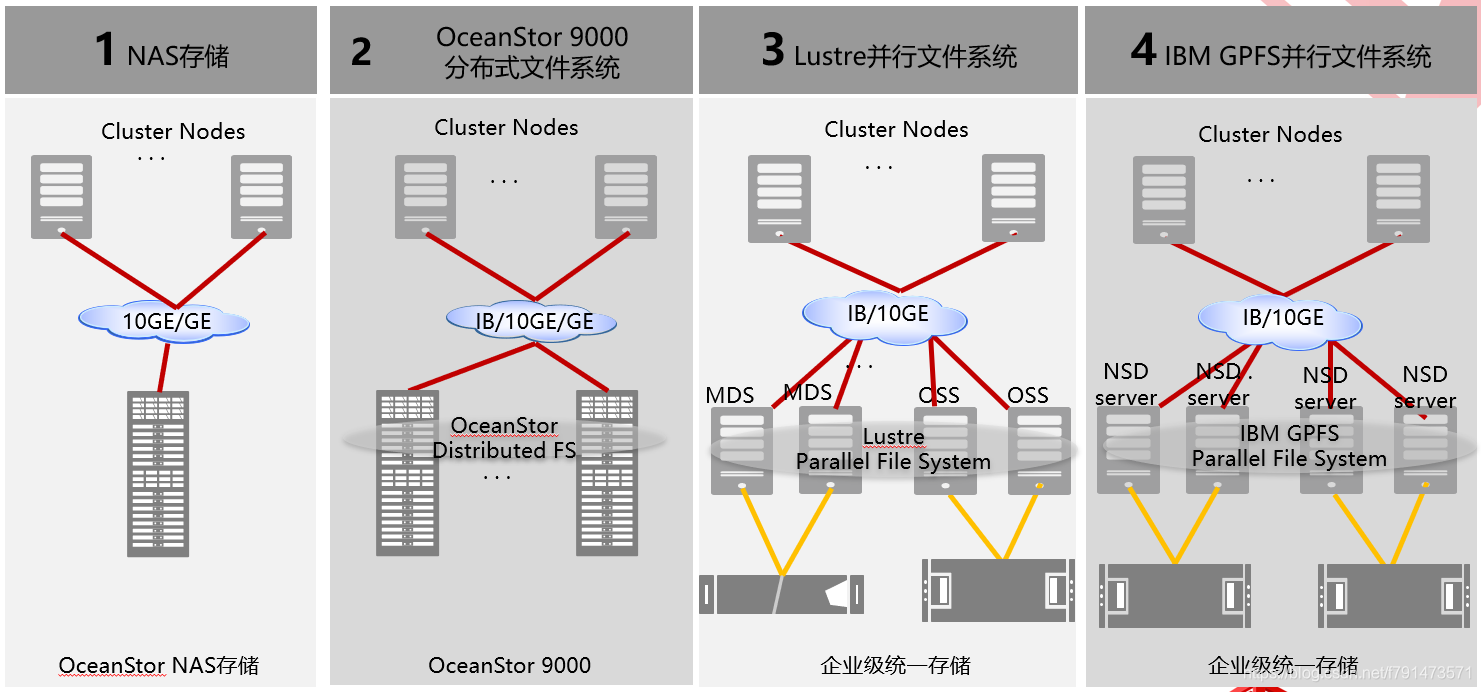
支持OceanStor v3 NAS存储
OceanStor 9000可以搭配IB网络进行使用
支持开源的Lustre并行文件系统,这款也是目前业界主流的HPC场景下的存储,由intel开源出来的。
也支持IBM GPFS并行文件系统
最后一张华为HPC架构图,总结上面的内容

















 1435
1435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









