






文章目录
前言
本博客主要出于记录阶段性工作,内容如果有误,还请各位小伙伴不吝指正!
网络结构: 这个博客是以yolov5为例的 ,但是这一套流程我是用ResNet分类、FCN分割和yolo检测都是能走通的,更重要的方法掌握。
环境配置和依赖: 本人C++菜鸡,项目使用的是TensorRT文件夹下的sample/sample_mnist项目,然后在里面写cpp文件,这个方式对我这样的新手很友好~(github上的sln属实没有一个能配置成功的)。
基础知识: 有关于YOLO、TensorRT基本原理的这篇就不详细介绍了。
TensorRT: 这里使用最简单的模式,即固定宽高、固定batch数目。
一、yolov5->ONNX
我使用的是yolo官方github的v6.0版本,移除了Focus模块并且激活函数替换为了SiLU。官方项目中自带了转ONNX的export.py文件,下载权重后直接运行就可以导出。
导出后就可以使用netron查看模型结构了,https://netron.app/这个链接可以直接查看。
这里面有一些细节可以可以关注,比如最开始的下采样模块在原始的v1.0版本使用的Focus模块,在做之前我还担心TensorRT不支持,不过V6.0中已经变成了两个卷积。
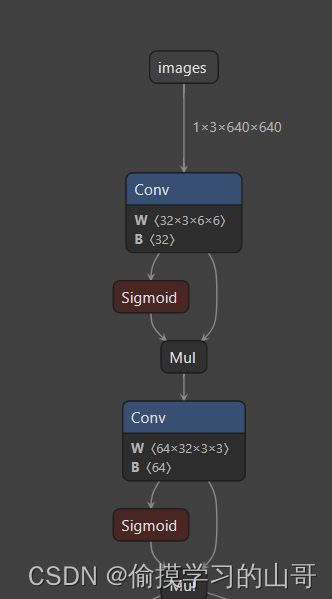
另外激活函数已也做了调整,貌似mish或者swish激活函数TensorRT都不支持,现在的SiLU其实就是x*sigmoid(x),非常友好。

二、TensorRT简介
1、TensorRT工作原理
首先明确TensorRT中用于执行推理的是engine,可以理解为是torch中的model,有了engine我们就可以进行类似于out = engine(image)的操作。
然后还有一个序列化、反序列化、原始模型二进制数据(自己起的名,代表了IHostmemory类)、TensorRT格式的模型(代表了INetworkDefinition类) 四个概念。
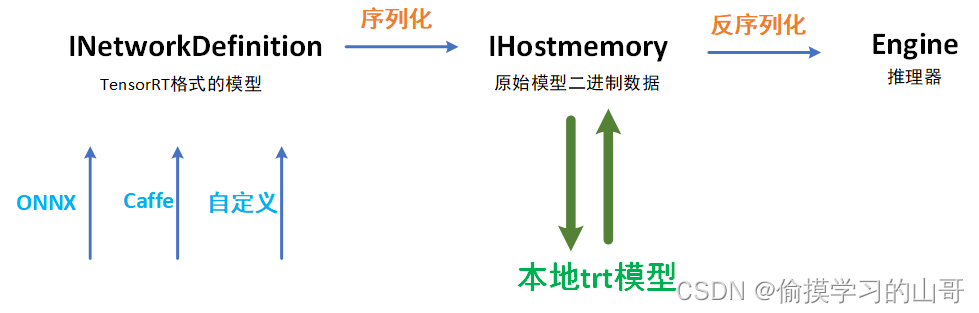
序列化指的是TensorRT格式的模型转为原始模型二进制数据,反序列化指的是原始模型二进制数据转为engine。生成TensorRT格式的模型的方式有很多种,可以通过ONNX,Caffe、TF或者直接在TensorRT中写每一层定义。
2、trt模型是什么?
这个过程中最耗时的是序列化过程,我本机耗时大概在2分钟左右。所以在实际部署中不能每次都从ONNX开始执行,一般都是保存中间的原始模型二进制数据,再直接进行反序列化。 我们可以通过二进制存储、读取的方式将IHostmemory保存到本地,本地的文件就是trt模型。
3、Host、Buffer、CUDA数据如何通信?
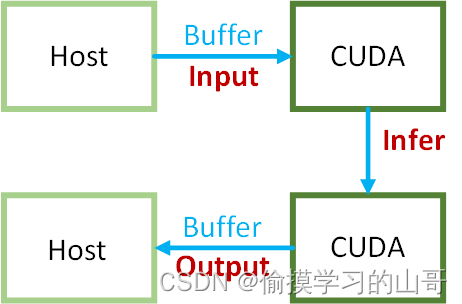
输入->Buffer->CUDA->执行推理->Buffer->输出
Host就是本机内存,输入和输出最终都是要返回到Host的。
三、代码
C++基础薄弱,个别地方写的很简陋,请谅解!
1、ONNX->模型二进制数据流(IHostmemory) ,序列化
提前说明的是,TensorRT模型(INetworkDefinition类) 不代表类似torch中的model,它是一个空壳子,我们需要把模型结构、参数等塞进去。上面说过torch中model应该更接近于TensorRT中的engine,是一个执行器。
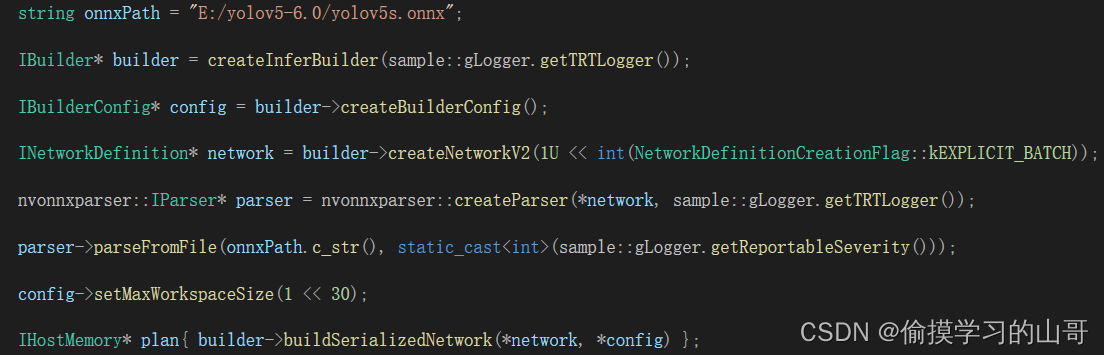
建立的过程其实都是模板化的东西,当然后续高阶用户使用动态宽高或者自定义组件时还需要修改。
1、创建builder,其中Logger也是模板化的固定代码,用于显示执行过程的信息。
2、创建config。
3、创建network,其中参数为显示的batch维度,固定的代码。
4、创捷一个parser并读取ONNX文件,parser有很多种有caffe的和TF,注意看IParser的命名空间 。
5、设置最大工作空间。
6、序列化network,得到二进制数据流(IHostmemory)。
2、如何保存和读取trt模型?
上面已经介绍过trt模型是什么,以及为什么要保存trt模型。
1、保存

保存的话的前提是我们已经获取到了模型二进制数据流(IHostmemory),代码中就是plan。
2、读取

上面说过,如说使用读取本地的trt模型来构建engine,那么就不需要序列化的部分了。所以使用该方式后那么 三.1章节 的代码段就不需要了,因为我们直接获取到了模型二进制数据流(IHostmemory)——serilaziedData。
3、模型二进制数据流(IHostmemory) ->engine,反序列化

代码就两行,mEngine就是我们想要的推理器。
4、推理
1、构建context
context是engine的一个线程,意思是说我们在得到了一个engine后可以开启多个context进行多线程推理。

一行代码,后面还会用到context。
2、初始化Buffer和Host空间
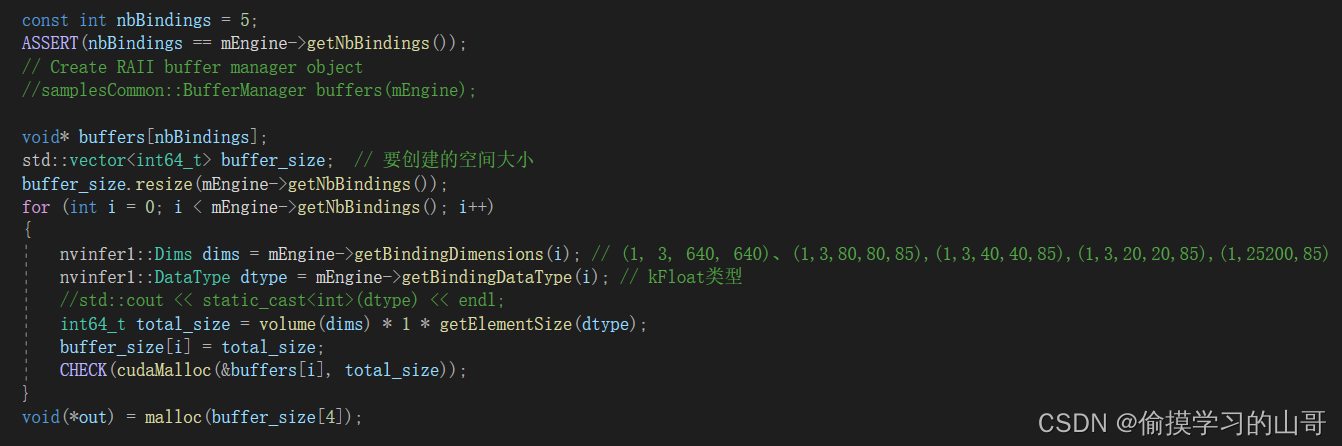
1、要确定Bindings,Bindings是模型中输入和输出的tensor。对于yolo来讲一共有5个Bindbings,分别是输入:(1, 3, 640, 640)、三个头的输出:(1,3,80,80,85),(1,3,40,40,85),(1,3,20,20,85) 、合并所有anchor的总和:(1,25200,85)。维度为什么是这样,这里不详细说了,这个就是yolo的基本原理。
2、定义buffer空间,这里使用一个for循环,把每一个tensor的大小都保存起来,并向CUDA申请显存。
3、同样在Host也申请一份内存。
3、输入图像处理
float* SampleOnnxMNIST::verifyInput(cv::Mat &resize)
{
string path = "E:\\torch_deloy\\car.jpeg";
const int c = 3; // 3
const int h = 640; // 224
const int w = 640; // 224
cv::Mat img = cv::imread(path);
auto scaleSize = cv::Size(w, h);
cv::Mat rgb;
cv::cvtColor(img, rgb, cv::COLOR_BGR2RGB);
cv::Mat resized;
cv::resize(rgb, resized, scaleSize);
resize = resized;
float* data;
data = (float*)calloc(h * w * c, sizeof(float));
for (int c = 0; c < 3; ++c)
{
for (int i = 0; i < resized.rows; ++i)
{ //获取第i行首像素指针
cv::Vec3b* p1 = resized.ptr<cv::Vec3b>(i);
//cv::Vec3b *p2 = image.ptr<cv::Vec3b>(i);
for (int j = 0; j < resized.cols; ++j)
{
data[c * resized.cols * resized.rows + i * resized.cols + j] = (p1[j][c] / 255.0f);
}
}
}
return data;
}
输入数据是以RRRR…GGGGG…BBBB…的格式进行转递的。
4、数据拷贝和执行推理
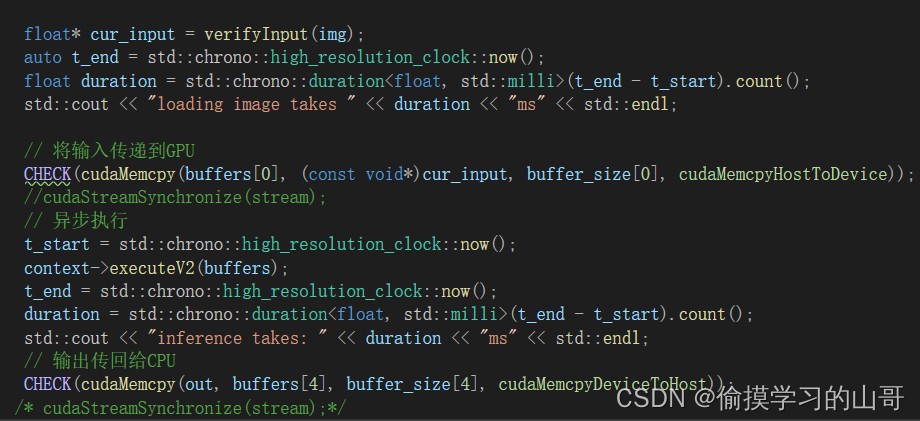
这里需要关注是的
// 将输入传递到GPU
CHECK(cudaMemcpy(buffers[0], (const void*)cur_input, buffer_size[0], cudaMemcpyHostToDevice));
// 输出传回给CPU
CHECK(cudaMemcpy(out, buffers[4], buffer_size[4], cudaMemcpyDeviceToHost));
buffer[0]是我们之前申请的第一个Binding的空间,也就是输入。
buffer[4]是我们之前申请的第最后Binding的空间,也就是(1,25200,85)。
buffer[1-3]我们并没有使用,这部分可以在申请空间时删除,但是我懒得弄了。
再执行完成后,out就是Host中的结果了。
out的数据排列格式为为:
anchor1的x, anchor1的y, anchor1的w,anchor1的h,anchor1的conf, anchor1的80类置信度, anchor2的x, anchor2的y, anchor2的w,................. anchor25200的x, anchor25200的y, anchor25200的w...........
5、后处理
对于检测来说就是一个NMS了,对于分类、分割其实要简单很多。
NMS我是网上抄的,然后修改了一些部分。代码很烂,有些地方为了方便写的很随意,轻喷~
static float get_iou_value(Rect rect1, Rect rect2)
{
int xx1, yy1, xx2, yy2;
xx1 = max(rect1.x, rect2.x);
yy1 = max(rect1.y, rect2.y);
xx2 = min(rect1.x + rect1.width - 1, rect2.x + rect2.width - 1);
yy2 = min(rect1.y + rect1.height - 1, rect2.y + rect2.height - 1);
int insection_width, insection_height;
insection_width = max(0, xx2 - xx1 + 1);
insection_height = max(0, yy2 - yy1 + 1);
float insection_area, union_area, iou;
insection_area = float(insection_width) * insection_height;
union_area = float(rect1.width * rect1.height + rect2.width * rect2.height - insection_area);
iou = insection_area / union_area;
return iou;
}
//input: boxes: 原始检测框集合;
//input: confidences:原始检测框对应的置信度值集合
//input: confThreshold 和 nmsThreshold 分别是 检测框置信度阈值以及做nms时的阈值
//output: indices 经过上面两个阈值过滤后剩下的检测框的index
void nms_boxes(vector<Rect>& boxes, vector<float>& confidences, float confThreshold, float nmsThreshold, vector<int>& indices)
{
BBOX bbox;
vector<BBOX> bboxes;
int i, j;
for (i = 0; i < boxes.size(); i++)
{
bbox.box = boxes[i];
bbox.confidence = confidences[i];
bbox.index = i;
bboxes.push_back(bbox);
}
sort(bboxes.begin(), bboxes.end(), [](const BBOX& a, const BBOX& b) { return a.confidence > b.confidence; });
int updated_size = bboxes.size();
for (i = 0; i < updated_size; i++)
{
if (bboxes[i].confidence < confThreshold)
continue;
indices.push_back(bboxes[i].index);
for (j = i + 1; j < updated_size; j++)
{
float iou = get_iou_value(bboxes[i].box, bboxes[j].box);
if (iou > nmsThreshold)
{
bboxes.erase(bboxes.begin() + j);
j--;
updated_size = bboxes.size();
}
}
}
}
bool SampleOnnxMNIST::postporessing(float* buffer, cv::Mat &img) {
vector<Rect> boxes;
vector<float> confidences;
float confThreshold = 0.5;
float nmsThreshold = 0.5;
vector<int> indexList;
vector<int> Classes;
for (int i = 0; i < 25200; i++) {
Rect temp;
temp.x = ((float*)buffer)[i * 85];
temp.y = ((float*)buffer)[i * 85 + 1];
temp.width = ((float*)buffer)[i * 85 + 2];
temp.height = ((float*)buffer)[i * 85 + 3];
float tempConf = *max_element(&buffer[i * 85 + 5], &buffer[(i + 1) * 85]);
int tempClass = max_element(&buffer[i * 85 + 5], &buffer[(i + 1) * 85]) - &buffer[i * 85 +5];
Classes.push_back(tempClass);
confidences.push_back(((float*)buffer)[i * 85+4] * tempConf);
boxes.push_back(temp);
}
nms_boxes(boxes, confidences, confThreshold, nmsThreshold, indexList);
for (int i = 0; i < size(indexList); i++) {
int x1 = boxes[indexList[i]].x - 0.5 * boxes[indexList[i]].width;
int x2 = boxes[indexList[i]].x + 0.5 * boxes[indexList[i]].width;
int y1 = boxes[indexList[i]].y - 0.5 * boxes[indexList[i]].height;
int y2 = boxes[indexList[i]].y + 0.5 * boxes[indexList[i]].height;
cv::rectangle(img, cv::Point(x1, y1), cv::Point(x2, y2), cv::Scalar(0, 0, 255));
}
cv::imshow("00", img);
cv::waitKey(0);
return 0;
}
四、结果
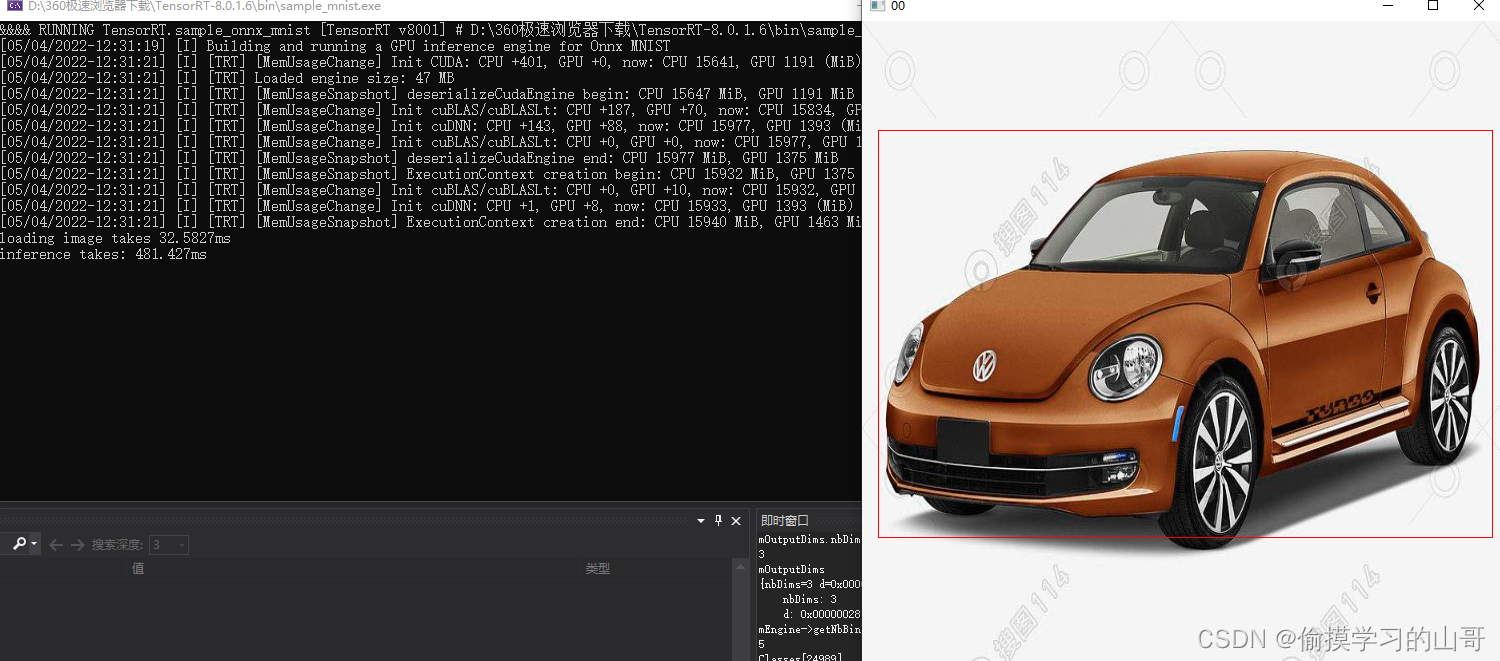
哦对了,忘了显示类别了。。。
还有就是速度贼慢,应该是后处理有问题,各位如果有好的后处理代码可以一起分享哈~~















 1976
1976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









