







二维数组
1.⼆维数组的概念
前⾯学习的数组被称为⼀维数组,数组的元素都是内置类型的,如果我们把⼀维数组做为数组的元素,这时候就是⼆维数组,⼆维数组作为数组元素的数组被称为三维数组,⼆维数组以上的数组统称为多维数组。
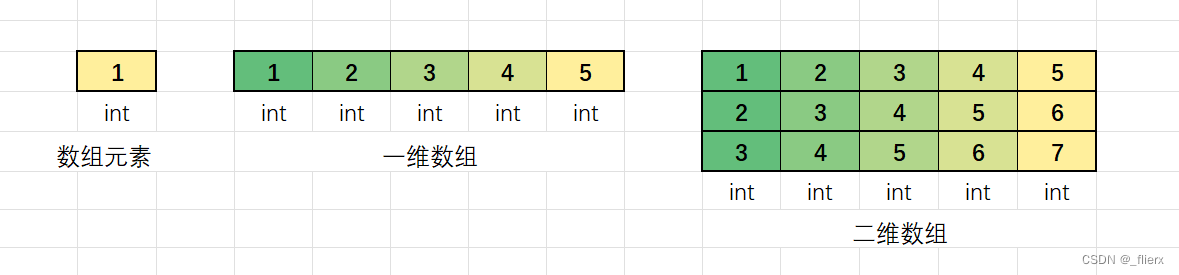
1.1⼆维数组的创建
那我们如何定义⼆维数组呢?语法如下:
type arr_name[常量值1][常量值2];
例如:
int arr[3][5];
double data[2][8];
解释:上述代码中出现的信息
• 3表⽰数组有3⾏
• 5表⽰每⼀⾏有5个元素
• int 表⽰数组的每个元素是整型类型
• arr 是数组名,可以根据⾃⼰的需要指定名字
data数组意思基本⼀致。
2.⼆维数组的初始化
在创建变量或者数组的时候,给定⼀些初始值,被称为初始化。
那⼆维数组如何初始化呢?像⼀维数组⼀样,也是使⽤⼤括号初始化的。
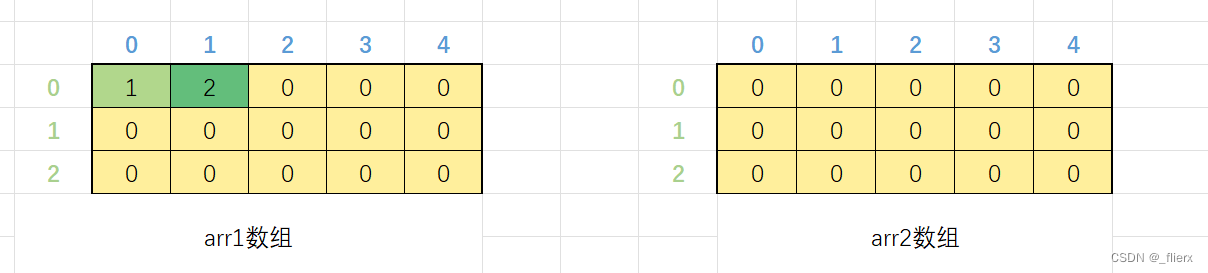
2.1 不完全初始化
int arr1[3][5] = {1,2};
int arr2[3][5] = {0};
2.2 完全初始化
int arr3[3][5] = {1,2,3,4,5, 2,3,4,5,6, 3,4,5,6,7};

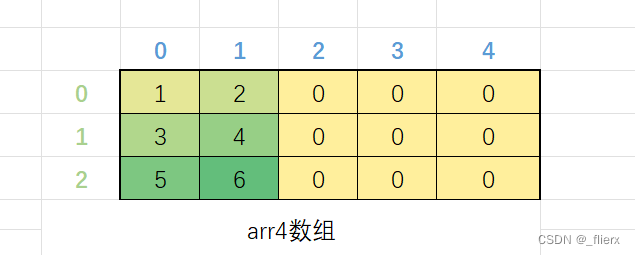
2.3 按照⾏初始化
int arr4[3][5] = {{1,2},{3,4},{5,6}}
2.4 初始化时省略⾏,但是不能省略列
int arr5[][5] = {1,2,3};
int arr6[][5] = {1,2,3,4,5,6,7};
int arr7[][5] = {{1,2}, {3,4}, {5,6}};

3.⼆维数组的使⽤
3.1 ⼆维数组的下标
当我们掌握了⼆维数组的创建和初始化,那我们怎么使⽤⼆维数组呢?
其实⼆维数组访问也是使⽤下标的形式的,⼆维数组是有⾏和列的,只要锁定了⾏和列就能唯⼀锁定数组中的⼀个元素。
C语⾔规定,⼆维数组的⾏是从0开始的,列也是从0开始的,如下所⽰:
int arr[3][5] = {1,2,3,4,5, 2,3,4,5,6, 3,4,5,6,7};
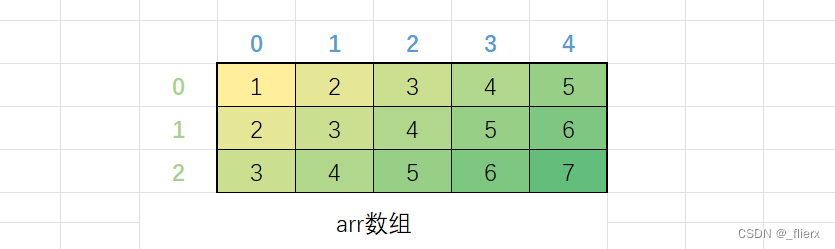
图中最右侧绿⾊的数字表⽰⾏号,第⼀⾏蓝⾊的数字表⽰列号,都是从0开始的,⽐如,我们说:第2⾏,第4列,快速就能定位出7。
#include <stdio.h>
int main()
{
int arr[3][5] = {1,2,3,4,5, 2,3,4,5,6, 3,4,5,6,7};
printf("%d\n", arr[2][4]);
return 0;
}
输出的结果如下:

8.2 ⼆维数组的输⼊和输出
访问⼆维数组的单个元素我们知道了,那如何访问整个⼆维数组呢?
其实我们只要能够按照⼀定的规律产⽣所有的⾏和列的数字就⾏;以上⼀段代码中的arr数组为例,⾏的选择范围是0 ~ 2,列的取值范围是0~4,所以我们可以借助循环实现⽣成所有的下标。
#include <stdio.h>
int main()
{
int arr[3][5] = {1,2,3,4,5, 2,3,4,5,6, 3,4,5,6,7};
int i = 0;//遍历⾏
//输⼊
for(i=0; i<3; i++) //产⽣⾏号
{
int j = 0;
for(j=0; j<5; j++) //产⽣列号
{
scanf("%d", &arr[i][j]); //输⼊数据
}
}
//输出
for(i=0; i<3; i++) //产⽣⾏号
{
int j = 0;
for(j=0; j<5; j++) //产⽣列号
{
printf("%d ", arr[i][j]); //输出数据
}
printf("\n");
}
return 0;
}
输⼊和输出的结果:

3. ⼆维数组在内存中的存储
像⼀维数组⼀样,我们如果想研究⼆维数组在内存中的存储⽅式,我们也是可以打印出数组所有元素的地址的。代码如下:
#include <stdio.h>
int main()
{
int arr[3][5] = { 0 };
int i = 0;
int j = 0;
for (i = 0; i < 3; i++)
{
for (j = 0; j < 5; j++)
{
printf("&arr[%d][%d] = %p\n", i, j, &arr[i][j]);
}
}
return 0;
}
输出的结果:

从输出的结果来看,每⼀⾏内部的每个元素都是相邻的,地址之间相差4个字节,跨⾏位置处的两个元素(如:arr[0][4]和arr[1][0])之间也是差4个字节,所以⼆维数组中的每个元素都是连续存放的。
如下图所⽰:

了解清楚⼆维数组在内存中的布局,有利于我们后期使⽤指针来访问数组的学习。
4. C99中的变⻓数组
在C99标准之前,C语⾔在创建数组的时候,数组⼤⼩的指定只能使⽤常量、常量表达式,或者如果我们初始化数据的话,可以省略数组⼤⼩。
如
int arr1[10];
int arr2[3+5];
int arr3[] = {1,2,3};
这样的语法限制,让我们创建数组就不够灵活,有时候数组⼤了浪费空间,有时候数组⼜⼩了不够⽤的.
C99中给⼀个变⻓数组(variable-length array,简称 VLA)的新特性,允许我们可以使⽤变量指定数组⼤⼩。
请看下⾯的代码:
int n = a+b;
int arr[n];
上⾯⽰例中,数组 arr 就是变⻓数组,因为它的⻓度取决于变量 n 的值,编译器没法事先确定,只有运⾏时才能知道 n 是多少。
变⻓数组的根本特征,就是数组⻓度只有运⾏时才能确定,所以变⻓数组不能初始化。它的好处是程序员不必在开发时,随意为数组指定⼀个估计的⻓度,程序可以在运⾏时为数组分配精确的⻓度。有⼀个⽐较迷惑的点,变⻓数组的意思是数组的⼤⼩是可以使⽤变量来指定的,在程序运⾏的时候,根据变量的⼤⼩来指定数组的元素个数,⽽不是说数组的⼤⼩是可变的。数组的⼤⼩⼀旦确定就不能再变化了。
遗憾的是在VS2022上,虽然⽀持⼤部分C99的语法,没有⽀持C99中的变⻓数组,没法测试;
5.数组练习
⼆分查找
在⼀个升序的数组中查找指定的数字n,很容易想到的⽅法就是遍历数组,但是这种⽅法效率⽐较低。
⽐如我买了⼀双鞋,你好奇问我多少钱,我说不超过300元。你还是好奇,你想知道到底多少,我就让你猜,你会怎么猜?你会1,2,3,4…这样猜吗?显然很慢;⼀般你都会猜中间数字,⽐如:150,然后看⼤了还是⼩了,这就是⼆分查找,也叫折半查找。
#include <stdio.h>
int main()
{
int arr[] = {1,2,3,4,5,6,7,8,9,10};
int left = 0;
int right = sizeof(arr)/sizeof(arr[0])-1;
int key = 7;//要找的数字
int mid = 0;//记录中间元素的下标
int find = 0;
while(left<=right)
{
mid = (left+right)/2;
if(arr[mid]>key)
{
right = mid-1;
}
else if(arr[mid] < key)
{
left = mid+1;
}
else
{
find = 1;
break;
}
}
if(1 == find )
printf("找到了,下标是%d\n", mid);
else
printf("找不到\n");
}
求中间元素的下标,使⽤ mid = (left+right)/2 ,如果left和right⽐较⼤的时候可能存在问
题,可以使⽤下⾯的⽅式:
mid = left+(right-left)>>1;
完。。。
















 1240
1240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











