






 文章介绍了使用图像处理(Canny边缘检测和轮廓提取)以及深度学习(YOLO)的方法来识别万用表屏幕上的数字。针对屏幕不稳定的情况,作者优化了代码并实现了300ms以内的识别速度。
文章介绍了使用图像处理(Canny边缘检测和轮廓提取)以及深度学习(YOLO)的方法来识别万用表屏幕上的数字。针对屏幕不稳定的情况,作者优化了代码并实现了300ms以内的识别速度。
读取数字方法主要有两种,1是选用图像处理,比较等方法识别,2是用深度学习的方法,比如yolo,识别数字。
如果万用表屏幕能够稳定的读取,可以选用方法1进行,如果万用表屏幕不固定,选用方法2比较好。
感谢三维重建及点云的电表识别源码本文采用方法1识别数字,基于yolo的识别也在进行中。在此感谢三维重建及点云的电表识别源码,他的源码各方面处理的极好,对于一些比较耗时的函数,我改成了较为省时的CV内置函数,整体识别时间从最早6秒左右到现在的300ms以下。
一,图像基本处理及画轮廓
图像原始图像为图1,把照片适当压扁,并进行灰度化,转换成HSV格式,取色调h通道进行滤波,求反,见图2,二值化,膨胀操作,见图3,取外轮廓,并在图上画出,见图4 。数字识别的关键就在于屏幕轮廓的选择上,可以做个小函数来实时看每个图像处理参数的效果,这样能选择到最适合自己的参数。




图1 图2 图3 图4
图像处理参数实时效果函数:
import cv2
import numpy as np
import imutils
def nothing(x):
pass
img = cv2.imread('test.jpg')
image = imutils.resize(img, height=300)
image = cv2.resize(image, None, fx=0.5, fy=0.5,interpolation=cv2.INTER_CUBIC)
img_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 创建窗口
cv2.namedWindow('Canny')
# 创建滑动条,分别对应Canny的两个阈值
cv2.createTrackbar('threshold1', 'Canny', 0, 255, nothing)
cv2.createTrackbar('threshold2', 'Canny', 0, 255, nothing)
#cv2.createTrackbar('threshold3', 'Canny', 0, 255, nothing)
while (1):
# 返回当前阈值
threshold1 = cv2.getTrackbarPos('threshold1', 'Canny')
threshold2 = cv2.getTrackbarPos('threshold2', 'Canny')
#threshold3 = cv2.getTrackbarPos('threshold3', 'Canny')
_, img_output = cv2.threshold(img_gray, threshold1, threshold2, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 显示图片
cv2.imshow('original', img)
cv2.imshow('Canny', img_output)
# 空格跳出
if cv2.waitKey(1) == ord(' '):
break
# 摧毁所有窗口
cv2.destroyAllWindows()
二,选取屏幕区域
对所有轮廓排序,从大到小计算,如果宽高比在4~6.5范围内,且面积在大小阈值内的,即为屏幕区域,如图5所示。进行霍夫变换,旋转图像至水平,灰度化图像,局部均衡化,局部二值化(比较耗时),处理完的屏幕如图6。


图5 图6
三,分割数字
先进行水平分割,只取有数字部分,再进行垂直分割,取出各数字和小数点。

![]()



四,识别数字
根据图像特征,判断数字,其中,1和"."的图像很窄,需要单独判断一下。
if result.shape[1] < 100: #如果宽度过小,则为1或"."
# 计算白色像素占比
total_pixels = result.shape[0] * result.shape[1]
white_pixels = np.count_nonzero(result == 255)
white_pixel_ratio = white_pixels / total_pixels
if 0 < white_pixel_ratio < 0.33:
number = 1
digits.append(number)
else:
if white_pixel_ratio > 0.66 or white_pixel_ratio == 0:
number = '.'
digits.append(number)
其它数字可按照数字段数的定义,结合字典,读取数字值 。
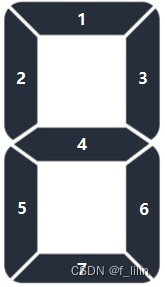
数码管定义
字典:
DIGITS_LOOKUP = {
(1, 1, 1, 0, 1, 1, 1): 0,
(0, 0, 1, 0, 0, 1, 0): 1,
(1, 0, 1, 1, 1, 0, 1): 2,
(1, 0, 1, 1, 0, 1, 1): 3,
(0, 1, 1, 1, 0, 1, 0): 4,
(1, 1, 0, 1, 0, 1, 1): 5,
(1, 1, 0, 1, 1, 1, 1): 6,
(1, 0, 1, 0, 0, 1, 0): 7,
(1, 1, 1, 1, 1, 1, 1): 8,
(1, 1, 1, 1, 0, 1, 1): 9,
}
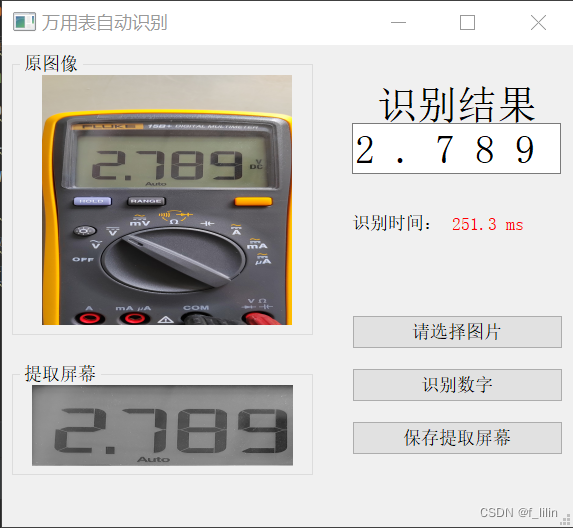
五、运行效果
如图所示,识别速度在300ms以内。
六、总结
采用图像处理的方式读取数字,需要读取的图像稳定一致,最好光线、角度、分辨率均统一,识别率才高。后续将采用yolo试试识别效果怎么样。

















 6098
6098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









