







之前也有了解过网页爬虫,但是只是按照网上教程练习过,今天想自己写一个爬图片的爬虫,一边写一边查资料,但是只是做了单页的爬虫,后续会继续学习做广度或深度的全网页的爬虫。
我的思路是
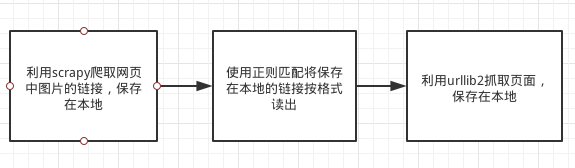
首先,
因为要使用scrapy,需要新建一个项目,tutorial为项目名称
scrapy startproject tutorial创建了一个文件夹,结构如下:
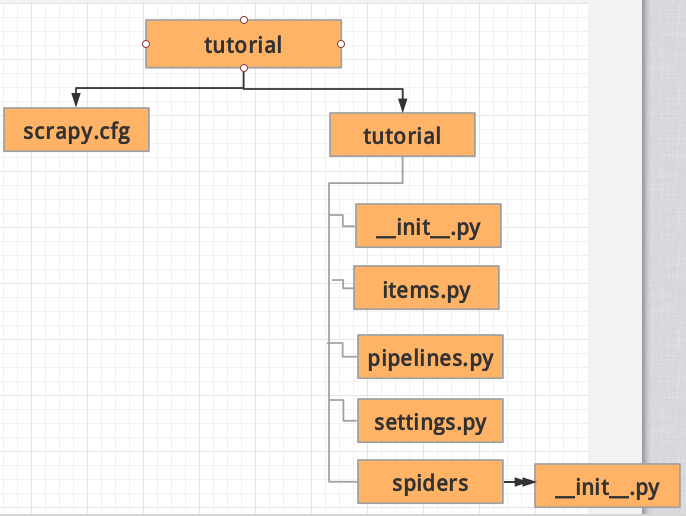
*scrapy.cfg:项目的配置文件
tutorial/:项目的Python模块,将会从这里引用代码
tutorial/items.py:项目的items文件
tutorial/pipelines.py:项目的pipelines文件
tutorial/settings.py:项目的设置文件
tutorial/spiders/:存储爬虫的目录*
建立这个爬虫分为三步:
将新创建的爬虫的item类写入tutorial/items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.
from scrapy.item import Item,Field
class TutorialItem(Item):
# define the fields for your item here like:
# name = Field()
pass
class DmozItem(Item):
title = Field()
link = Field()
desc = Field()将新创建的爬虫类写入/spiders下
vim dmoz_spider.py
#!/usr/bin/env python
# coding=utf-8
from scrapy.spiders import Spider
from scrapy.selector import Selector
from items import DmozItem
class DmozSpider(Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"https://picjumbo.com/touch-of-life-fingers-on-plasma-ball-lamp/",
]
def parse(self,response):
sel = Selector(response)
sites = sel.xpath('//a/img/@src')
print '**************************\n'
print sites
print '**************************\n'
items = []
for site in sites:
item = DmozItem()
item['link'] = site.extract()
items.append(item)
return items但是做完上述两步并没有结束哦,还要执行
scrapy crawl dmoz -o pic -t json dmoz:爬虫的name
-o pic : pic是我保存的文件名
-t json : 以json的类型保存
经过上述三步,我们已经将爬取的代码保存在pic文件中
[{"link": "https://picjumbo.com/wp-content/themes/picjumbofree/data/picjumbo_logo.png"},
{"link": "/wp-content/themes/picjumbofree/data/promo-line-premium.jpg"},
{"link": "//assets.pinterest.com/images/pidgets/pinit_fg_en_rect_red_28.png"},
{"link": "/wp-content/themes/picjumbofree/data/picj-banner.jpeg"},
{"link": "https://picjumbo.com/wp-content/themes/picjumbofree/data/latest_premium_sidebar.png"},
{"link": "https://picjumbo.com/wp-content/uploads/picjumbo-premium-website-layout-collection.jpg"},
{"link": "https://picjumbo.com/wp-content/uploads/website-layout-collection-collage-small.jpg"},
{"link": "https://d3ui957tjb5bqd.cloudfront.net/images/bundles/july-big-bundle-2016_email.jpg"},
{"link": "/wp-content/themes/picjumbofree/data/promo-line-premium.jpg"},
{"link": "https://picjumbo.com/wp-content/uploads/picjumbo-premium-website-layout-collection.jpg"},
{"link": "https://picjumbo.com/wp-content/uploads/website-layout-collection-collage-small.jpg"},
{"link": "//picjumbo.imgix.net/IMG_5766.jpg?q=40&w=1000&sharp=30"},
{"link": "//picjumbo.imgix.net/IMG_0744.jpg?q=40&w=1000&sharp=30"},
{"link": "//picjumbo.imgix.net/HNCK2219.jpg?q=40&w=1000&sharp=30"},
{"link": "//picjumbo.imgix.net/HNCK0182.jpg?q=40&w=1000&sharp=30"},
{"link": "//picjumbo.imgix.net/HNCK5769.jpg?q=40&w=1000&sharp=30"},
{"link": "//picjumbo.imgix.net/HNCK5108.jpg?q=40&w=1000&sharp=30"},
{"link": "//picjumbo.imgix.net/HNCK8242.jpg?q=40&w=1000&sharp=30"},
{"link": "//picjumbo.imgix.net/HNCK2127.jpg?q=40&w=1000&sharp=30"},
{"link": "//picjumbo.imgix.net/HNCK86321.jpg?q=40&w=1000&sharp=30"},
{"link": "//picjumbo.imgix.net/HNCK7373.jpg?q=40&w=1000&sharp=30"},
{"link": "https://picjumbo.com/wp-content/themes/picjumbofree/data/logo_footer.png"}]接下来就可以开始爬图片啦!
其实代码非常的简短==
这个过程分为两步
1. 将现有的pic文件中格式不为网页链接形式的字符串,利用正则匹配,并和固定字符串连接形成网页链接。
2. 将这些网页链接利用urllib2从网络保存到本地。
#!/usr/bin/env python
# coding=utf-8
import re
import urllib2
cnt=0
f=open('pic')
for i in f.readlines():
a=re.search('//picjumbo.imgix.net(\S+)*"',i)
if a:
furl='https:'+a.group()
url=furl[:-1]
cnt=cnt+1
f=open('spt'+str(cnt),'w+')
m=urllib2.urlopen(url).read()
f.write(m)
f.close()运行后可以看到图片被保存到本地啦

这个简单的爬虫就到这里做完啦,之后会学习做可以爬取整个网页的爬虫,而不但局限于一张网页,还需要学习一下算法==















 1491
1491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









