







 本文介绍了如何使用selenium和BeautifulSoup结合爬取B站视频搜索页面上的视频标题和对应URL。通过定位特定的HTML标签,提取出含有视频信息的部分,并展示了在爬取过程中遇到的空链接和最后一页处理问题。
本文介绍了如何使用selenium和BeautifulSoup结合爬取B站视频搜索页面上的视频标题和对应URL。通过定位特定的HTML标签,提取出含有视频信息的部分,并展示了在爬取过程中遇到的空链接和最后一页处理问题。
初探 selenium 及 BeautifulSoup
上周写过一个爬取图片的小爬虫,当时说希望之后可以写一个可以递归或者遍历的爬虫,因为这几天比较累,所以正好想写一个爬取b站的爬虫放松一下心情。
首先,明确要爬什么。我看了一下b站网页上的内容,决定,还是以爬取视屏标题以及对应网址作为内容。看一下他的搜索页面网页源代码:
比如:
搜索:我的危险妻子(这是一部日剧),跳转到搜索页面:

可以看到与视频链接相关的比较具有特征的是div标签class属性为headline,链接在a标签的href属性中那么,我们可以用简单的语句把他们提取出来

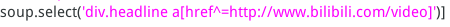
这里的response是浏览器传来的页面源代码,这个我们后面再说,通过以上两句,我们已经可以从网页源代码中挑选出符合我们要求的标签列表。
这里说明一下,
* div.headline 表示div标签class属性为headline
a[href^=http://] 表示a标签href属性的值以http://作为开始 *
匹配我觉
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2169
2169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









