






1.make_layer循环堆叠残差块网络结构
2.BN与Relu的作用
3.网络结构构建()与输出值(输入参数X自动使用forward类方法)
4.类与实例化与继承
nn.BatchNorm2d(palnes[0])详解
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
num_features:通道数,eps用于分母添加一个极小数防止除以0
affine:对gamma,beta参数具有可学习能力
momentum:用来计算平均值和方差的值,默认值为0.1
输入参数(N,C,H,W)输出(N,C,H,W)
作用:把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
3x3,1x1卷积块
# 进行权值初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))##初始化权重
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)##BN归一化
m.bias.data.zero_()初始化
class DarkNet(nn.Module):
def __init__(self, layers):
super(DarkNet, self).__init__()继承类创建,super继承父类,模板,layers为调用Darknet需要初始化的参数
残差块创建
def _make_layer(self, planes, blocks):
layers = []
# 下采样,步长为2,卷积核大小为3
layers.append(("ds_conv", nn.Conv2d(self.inplanes, planes[1], kernel_size=3, stride=2, padding=1, bias=False)))
layers.append(("ds_bn", nn.BatchNorm2d(planes[1])))
layers.append(("ds_relu", nn.LeakyReLU(0.1)))larers.append处通道数已变为[1]
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes[0], kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes[0])
self.relu1 = nn.LeakyReLU(0.1)
self.conv2 = nn.Conv2d(planes[0], planes[1], kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes[1])
self.relu2 = nn.LeakyReLU(0.1)
在残差块中通道数:planes[1]->[0]->[1]
for i in range(0, blocks):##迭代创建残差块层结构
layers.append(("residual_{}".format(i), BasicBlock(self.inplanes, planes)))
return nn.Sequential(OrderedDict(layers))##列表转字典转容器循环创建残差块blocks,创建个数
通过makelayer创建多个类似的残差块堆叠结构
self.inplanes = 32
# 416,416,3 -> 416,416,32
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplanes)
self.relu1 = nn.LeakyReLU(0.1)
# 416,416,32 -> 208,208,64
self.layer1 = self._make_layer([32, 64], layers[0])
# 208,208,64 -> 104,104,128
self.layer2 = self._make_layer([64, 128], layers[1])
# 104,104,128 -> 52,52,256
self.layer3 = self._make_layer([128, 256], layers[2])
# 52,52,256 -> 26,26,512
self.layer4 = self._make_layer([256, 512], layers[3])
# 26,26,512 -> 13,13,1024
self.layer5 = self._make_layer([512, 1024], layers[4])
self.layers_out_filters = [64, 128, 256, 512, 1024]
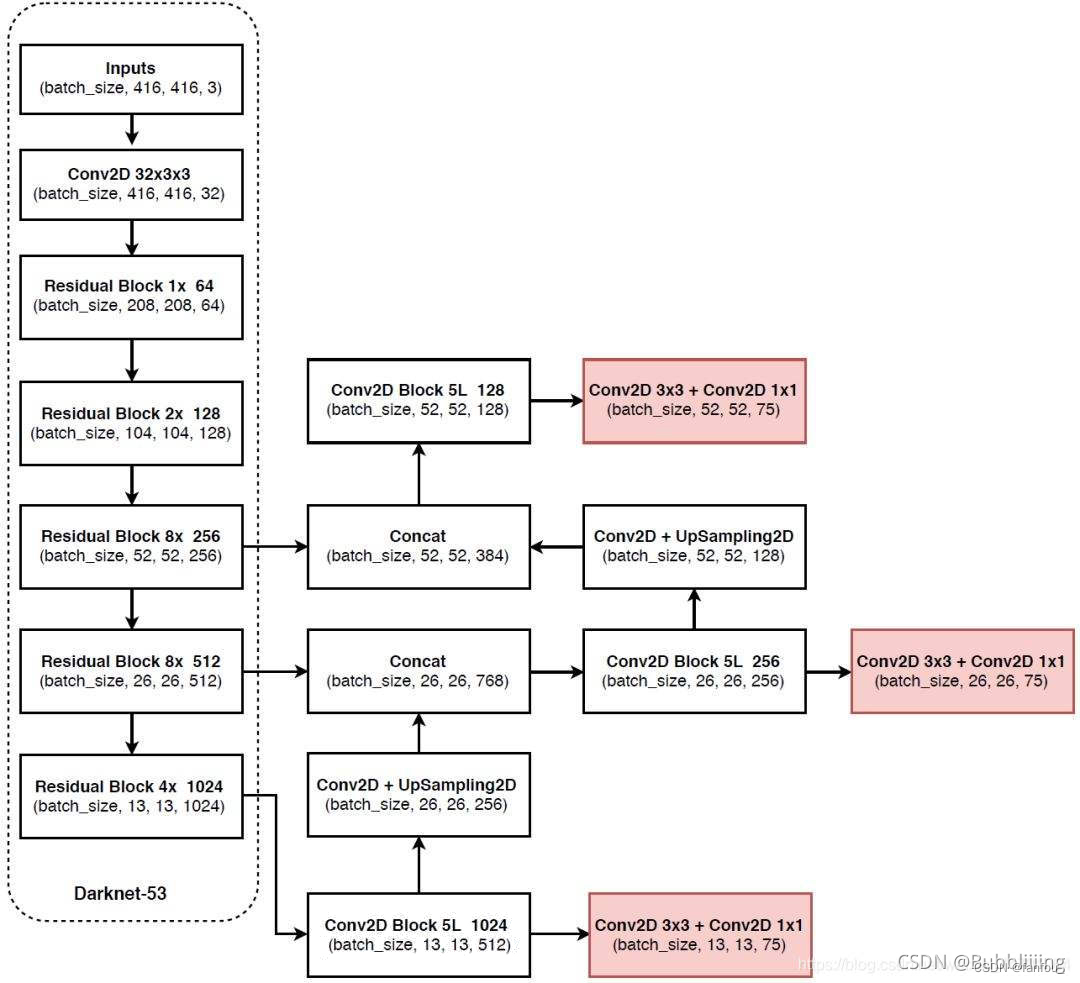 3->32->64->128->256->512->1024
3->32->64->128->256->512->1024
layers参数为残差块迭代次数(个数)
# 进行权值初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))##初始化权重
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)##BN归一化
m.bias.data.zero_()权重、参数初始化
for m in self.modules
self.modules是nn.Module的类方法,会返回所有的网络结构
conv初始化w,batch初始化b
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsw的参数个数卷积块长宽尺寸与通道数相乘如下图3x3x3

m.weight.data->得到一个张量tensor
m.weight->得到可训练参数list

上述构建的为具体的网络结构,应用还需要具体的值
m = nn.LeakyReLU(0.1) # 构建LeakyReLU函数
input = torch.randn(2) # 输入
output = m(input) # 对输入应用LeakyReLU函数需要对应的input值与如m的值来封装网络结构
darknet实例化
if __name__=="__main__":
import torch
# from torchvision.models.detection import darknet53
# 创建DarkNet53模型
model = darknet53() def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.layer1(x)
x = self.layer2(x)
out3 = self.layer3(x)
out4 = self.layer4(out3)
out5 = self.layer5(out4)
return out3, out4, out5 input_image = torch.randn(1, 3, 416, 416)
# 将输入数据送入模型进行前向传播
out3, out4, out5 = model(input_image)实例化后输入参数x(处理图像),自动调用类中含有X的函数forword得到三个特征提取层
该forword为darknet的类方法,输入张量x传递给网络即会自动使用
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes[0], kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes[0])
self.relu1 = nn.LeakyReLU(0.1)
self.conv2 = nn.Conv2d(planes[0], planes[1], kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes[1])
self.relu2 = nn.LeakyReLU(0.1)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
out += residual
return out残差块构建,当输入张量x时使用类方法forward
for i in range(0, blocks):##迭代创建残差块层结构
layers.append(("residual_{}".format(i), BasicBlock(self.inplanes, planes)))再darknet中的forward类方法中的make_layer会循环进入basicblock启用forward类方法
实例化的网络结构可以处理x参数而不需要说明?















 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









