







之前写了一个读取文件的代码,发现每次读取的行数都比实际多一行。文档是一行行的数据,最后确实有一个空行,这是因为输出这个文档的时候,每一行都有一个换行符,所以必然导致最后一行有一个空行。这是一个非常普遍的现象,本文就研究一下如何正确的读取文本。
首先,我们的测试文档如下,最后的点表示这是一个空行,实际中并没有。
new 1.23
fan 2
jin 4.444
ge 0.10203
.1. 使用eof来判断
先看一段错误的代码
int read_1()
{
std::ifstream file("test.txt");
std::vector<std::string> word;
std::vector<float> value;
while (true) {
// A word and a double value were both read successfully
float value_tmp;
std::string word_tmp;
file >> word_tmp >> value_tmp; // >> 在添加头文件sstream之后可以使用,否则会报错
value.push_back(value_tmp);
word.push_back(word_tmp);
if( file.eof() )
break;
}
std::cout <<"--------------"<<std::endl;
for (int i = 0; i<value.size(); i++)
{
std::cout << "word:" << word[i] <<", value:" << value[i] <<std::endl;
}
file.close();
return 0;
}或者这么写也一样
while (!file.eof()) {
// A word and a double value were both read successfully
float value_tmp;
std::string word_tmp;
file >> word_tmp >> value_tmp; //>>在添加头文件sstream之后可以使用,否则会报错
value.push_back(value_tmp);
word.push_back(word_tmp);
}输出结果
--------------
word:new, value:1.23
word:fan, value:2
word:jin, value:4.444
word:ge, value:0.10203
word:, value:0.10203可以看到多了一行。
分析:eof从字面意思来看,当然是end of file,用于表明当前已经到了文件末尾,不能再读了。
但这里有一个很迷惑的陷阱:只要遇到结束符,流就会将状态置为EOF,而不管置位前的操作是否成功。
例如,使用getline函数读取文件的最后一行,如果这一行是因为遇到了EOF而结束的,那么getline操作是成功的,但eof还是会置位。
2. while循环中输出
代码如下:
int read_2()
{
std::ifstream file("test.txt");
std::vector<std::string> word;
std::vector<float> value;
float value_tmp;
std::string word_tmp;
while (file >> word_tmp >> value_tmp) {
// A word and a double value were both read successfully
value.push_back(value_tmp);
word.push_back(word_tmp);
}
if (!file.eof()) throw std::runtime_error("Invalid data from file");
std::cout <<"--------------"<<std::endl;
for (int i = 0; i<value.size(); i++)
{
std::cout << "word:" << word[i] <<", value:" << value[i] <<std::endl;
}
file.close();
return 0;
}运行结果:
--------------
word:new, value:1.23
word:fan, value:2
word:jin, value:4.444
word:ge, value:0.10203运行正确。
3. 使用fail进行判断
int read_3()
{
std::ifstream file("test.txt");
std::string input_str;
std::vector<std::string> str;
while(file)
{
getline(file,input_str);
if(file.fail())
break;
str.push_back(input_str);
}
std::cout <<"--------------"<<std::endl;
for (int i = 0; i<str.size(); i++)
{
std::cout << str[i] <<std::endl;
}
file.close();
return 0;
}输出
--------------
new 1.23
fan 2
jin 4.444
ge 0.102034. peek()进行判断
peek()方法预读取下一个字符(不管是何符号)。从流中取出一个字符,但不移动流指针位置。
int read_4()
{
std::ifstream file("test.txt");
std::vector<std::string> word;
std::vector<float> value;
while (!file.eof()) {
// A word and a double value were both read successfully
float value_tmp;
std::string word_tmp;
file >> word_tmp >> value_tmp; //>>在添加头文件sstream之后可以使用,否则会报错
value.push_back(value_tmp);
word.push_back(word_tmp);
file.get(); // 读取最后的回车符
if(file.peek() == '\n') break;
}
std::cout <<"--------------"<<std::endl;
for (int i = 0; i<value.size(); i++)
{
std::cout << "word:" << word[i] <<", value:" << value[i] <<std::endl;
}
file.close();
return 0;
}或者这么写也可以
while (!file.eof() && file.peek()!=EOF) {
// A word and a double value were both read successfully
float value_tmp;
std::string word_tmp;
file >> word_tmp >> value_tmp; //>>在添加头文件sstream之后可以使用,否则会报错
value.push_back(value_tmp);
word.push_back(word_tmp);
file.get(); // 读取最后的回车符
}运行结果:
--------------
word:new, value:1.23
word:fan, value:2
word:jin, value:4.444
word:ge, value:0.10203运行正确。其实本质就是读完了一行数据后,再把接下来的换行符读入,再判断下一个符号是什么。如果还是换行符,说明已经结束了。
参考
1. C++ 读取文件最后一行
2. 小心为上:注意C++ fstream给你设下的陷阱
3. c++读取文件操作之peek、>>和get
[附 1]摘录防丢失:小心为上:注意C++ fstream给你设下的陷阱
透过名字看本质:到底什么是stream?
1. stream的定义
stream的中文翻译为“流”,不是很好理解,我们来看英文关于stream的定义,比较常见的有两个:
1. A stream is an abstraction that represents a device on which input and output operations are performed.
2. A stream is a “stream of data” in which character sequences “flow.”
英文看起来比较累,总结一下,提炼如下几个关键点:
1. abstraction that represents a device:代表一个设备;
2. stream of data:数据流,隐含了FIFO的一个特性;
3. character sequences flow:字符序列在其中流动,而不是二进制在其中流动;
多说无益,还是看图说话:
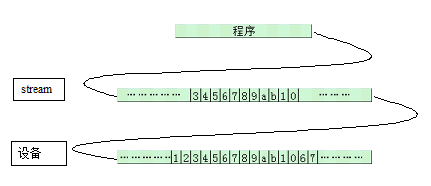
注:上图中暗含一个玄机:stream的数据是设备数据的一个子集,因为stream只是代表一个设备,而并不是完全等于一个设备。
2. 关公战秦琼: stream vs buffer
一个容易和stream混淆的概念就是大家常见的buffer,buffer的定义为(参见WIKI Data Buffer):A buffer is a region of memory used to temporarily hold data while it is being moved from one place to another.
英文看起来也比较累,还是总结一下:
1. region of memory:一块内存区域,因此就隐含了随机访问和二进制的操作方式;
2. one place to another:数据移动过程中使用
经过对两个术语定义的分析总结,相信大家都明白了这两者之间的差异了,其实这就是一个关公战秦琼的例子,因为它们两个实际上并不是一个竞争关系。
汇总对比点如下:
| 对比点 | stream | buffer |
|---|---|---|
| 访问方式 | FIFO | 随机访问 |
| 数据内容 | 字符流 | 二进制 |
当然,并不是说stream和buffer就毫无关系了,stream为了提高性能,实现的时候就用到了buffer。
小心为上:注意fstream设下的陷阱
3. char和wchar_t的操作
当你使用<<输出的时候,任何字符都可以输出;但当使用>>进行输入的时候,开头的空白字符缺省情况下是跳过的。
例如:假设文件中有这么一个字符串“ test”,则使用>>读入的时候,直接就读到了字母‘t’,而不会是空格。
避免这个陷阱的招数:
1. 清除skipws标志:unsetf(ios::skipws)
2. 使用get()函数
4. 指针类型的操作
(1) char*
char*类型的数据输出时会将字符串全部输出,但输入的时候你千万要注意,输入的时候默认会将前面的空白字符全部去掉;而且输入时默认是以空格来作为分隔符的,例如:“This is a test C-string.”可以全部输出,但如果文件中有这么一串字符串,那么用<<是无法全部读入的,只能读入“This”“is”“a”“test”“C-string”.
避免这个陷阱的招数:
1. 如果想改变默认去掉头部空白字符的操作方式,请参考skipws
2. 如果想改变以空格作为结束符的操作方式,对不起,用<<是没有办法的,只能用istream& istream::get (char* str, streamsize count, char delim)或者
istream& istream::getline (char* str, streamsize count, char delim)
(2)void*
直接输出指针地址。
(3) 其它指针
不管是指向int/double等标准数据类型,还是自定义的struct/class类型,都是输出指针指向的地址,而不是输出指针指向的对象。
5. eof和fail
(1) eof
eof从字面意思来看,当然是end of file,用于表明当前已经到了文件末尾,不能再读了。
但这里有一个很迷惑的陷阱:只要遇到结束符,流就会将状态置为EOF,而不管置位前的操作是否成功。
例如,使用getline函数读取文件的最后一行,如果这一行是因为遇到了EOF而结束的,那么getline操作是成功的,但eof还是会置位。
因此,不能在调用函数后通过eof来判断函数调用是否读到文件末尾了,而应该直接判断调用本身是否成功,具体样例请看fail。
(2) fail
导致fail标志位置位的有如下常见的情况:
1. 文件不存在;
2. 文件不能创建;
3. eof标志位置位;
4. 非法的格式,例如当你期望数字的时候,而文件里面却是字母
注意第三种情况,在文件eof的时候也会同时置fail,所以,循环读取文件的时候,要将fail和eof结合起来使用:在循环判断中使用fail,fail失败后再使用eof。
错误的用法:
std::ifstream file("test.txt");
std::string word;
double value;
while ( true ) {
// A word and a double value were both read successfully
file >> word >> value;
if( file.eof() )
break;
}正确的用法
std::ifstream file("test.txt");
std::string word;
double value;
while (file >> word >> value) {
// A word and a double value were both read successfully
}
if (!file.eof()) throw std::runtime_error("Invalid data from file");6. fstream的binary打开方式
文件流的打开方式中有一个binary,从字面意思来看,应该是按照二进制打开文件,然后进行二进制读写。
然而这样理解的话,就陷入了C++的陷阱:binary实际上和二进制读写没有关系,binary只是为了告诉系统是否将不同操作系统间特定的字符替换,最典型的是换行符,在windows上是/r/n,而在Unix类系统上是/n,如果加了这个binary标志,流就不会自动替换。
那C++的fstream流如何进行二进制读写呢?其实很简单:只需要调用get/read和put/write即可。也就是说:是否是二进制读写和文件打开方式无关,而是和调用函数有关。如果使用<<和>>,则就是按照字符流进行读写;如果使用get/read和put/write,则按照二进制读写。
前面说过流是character sequences flow,那为什么这里又说fstream能够按照二进制读写呢?由于没有研究过相关的实现代码,因此这里无法给出分析,个人推断应该是流的内部实现将字符流转换为二进制了。
[附 2]摘录防丢失:c++读取文件操作之peek、>>和get
预备知识:
fstream提供了三个类,用来实现c++对文件的操作。(文件的创建、读、写)。
ifstream – 从已有的文件读
ofstream – 向文件写内容
fstream – 打开文件供读写
文件打开模式:
ios::in 读
ios::out 写
ios::app 从文件末尾开始写
ios::binary 二进制模式
ios::nocreate 打开一个文件时,如果文件不存在,不创建文件。
ios::noreplace 打开一个文件时,如果文件不存在,创建该文件
ios::trunc 打开一个文件,然后清空内容
ios::ate 打开一个文件时,将位置移动到文件尾
文件指针位置在c++中的用法:
ios::beg 文件头
ios::end 文件尾
ios::cur 当前位置
例子:
file.seekg(0,ios::beg); //让文件指针定位到文件开头
file.seekg(0,ios::end); //让文件指针定位到文件末尾
file.seekg(10,ios::cur); //让文件指针从当前位置向文件末方向移动10个字节
file.seekg(-10,ios::cur); //让文件指针从当前位置向文件开始方向移动10个字节
file.seekg(10,ios::beg); //让文件指针定位到离文件开头10个字节的位置
常用的错误判断方法:
good() 如果文件打开成功
bad() 打开文件时发生错误
eof() 到达文件尾
以上摘自:http://blog.csdn.net/wangshihui512/article/details/8921919应注意的地方:
1、在文件读取时,>>操作符会自动忽略空格以及换行。例如,输入文件内容如下:
8
#0 1 11 0
15 59 60 63 132 169 176 192
17 4 13 30 49 56 60 92 114 132 162 165 169 176 182
21 2 30 50 57 63 92 94 100 114 126 162 165 176 182 192
#1 1 2 0
1 11 31 35 69 114 162 165 182
6 18 67 107 110 158 162 183
.注意每一行后面都没有空格,最后一行是空行。
有如下三个代码:
代码1:
fstream inFile;
inFile.open(fileName, ios::in);
int iNum;
inFile>>iNum;
cout<<(char)inFile.peek()<<endl;猜猜输出的是什么?
A.换行符
B. #
代码2:
fstream inFile;
inFile.open(fileName, ios::in);
int iNum;
inFile>>iNum;
char c;
inFile>>c;
cout<<c<<endl;猜猜输出的是什么?
A.换行符
B. #
代码3:
fstream inFile;
inFile.open(fileName, ios::in);
int iNum;
inFile>>iNum;
char c;
inFile.get(c);
cout<<c<<endl;猜猜输出的是什么?
A.换行符
B. #
相信大多数人可能会犯和我同样的错误,认为都是输出#,或者弄混淆。
其实代码1和代码3输出的是换行符,代码2输出的为#。
据此,我们可以得出以下结论:(1)>>操作符会忽略前面的空白符和换行符,但不会越过后面的换行符和空白符
(2)get()方法不会略过任何符号
(3)peek()方法预读取下一个字符(不管是何符号)
2、利用peek()判断读取完毕
同样是1中的输入文件,若读取的代码如下:
fstream inFile;
inFile.open(fileName, ios::in);
while(!inFile.eof()){
//相关的读取操作
}最后一行空行也会进入循环,导致读取错误。
因此可以利用peek()方法来避免这个问题:
fstream inFile;
inFile.open(fileName, ios::in);
while(!inFile.eof()&&inFile.peek()!=EOF){
//相关的读取操作
}














 6600
6600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









