









maven,git的学习,flink的编译
1. Flink DataSet语义注解
- 语义注解可用于为 Flink 提供有关函数行为的提示。它们告诉系统函数读取和评估函数输入的哪些字段,以及
未修改的函数将哪些字段从其输入转发到输出。 语义注解是加快执行速度的强大方法,因为它们使系统能够推理出在多个操作之间重用排序顺序或分区。使用语义注解最终可以使程序免于不必要的数据改组或不必要的排序,并显着提高程序的性能。
1.1. ForwardedFields转发字段
所谓转发字段,字面理解就是某个字段不经过处理直接存储到另一位置, ForwardedFields可以分为两类,一类是以map算子为代表的转发字段,另一类是join算子的转发字段,这两类算子的主要区别就是输入的DataSet个数。
1.1.1. 单输入算子转发字段
-
withForwardedFields("_n"):要求该算子输入数据的第n个字段与输出的第n个字段相匹配,若有多个类似匹配,可用分号分隔。
val env = ExecutionEnvironment.getExecutionEnvironment val ds: DataSet[Point] = env.fromElements(Point("a", 10.0), Point("b", 20.0), Point("a", 30.0)) val value: DataSet[(String, Double, Long)] = ds.map(t => (t.x, t.y)) .map { x => (x._1, x._2, 1L) }.withForwardedFields("_1; _2") // 第一字段,第二字段个输入匹配 value.print()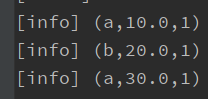
val env = ExecutionEnvironment.getExecutionEnvironment val ds: DataSet[Point] = env.fromElements(Point("a", 10.0), Point("b", 20.0), Point("a", 30.0)) val value: DataSet[(String, Double, Long)] = ds.map(t => (t.x, t.y)) .map { x => (x._1, x._2, 1L) }.withForwardedFields("_1; _2") .reduce{(p1, p2) => (p1._1, p1._2 + p2._2, p1._3 + p2._3)}.withForwardedFields("_1") // 第一个字段匹配 value.print()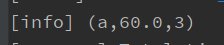
-
withForwardedFields("_n->x"):要求该算子的输出类型是某个class,并且x是该class中的某个属性,且输入数据的第n个字段与输出类型中的属性x相匹配
val env = ExecutionEnvironment.getExecutionEnvironment val ds: DataSet[Point] = env.fromElements(Point("a", 10.0), Point("b", 20.0), Point("a", 30.0)) val value: DataSet[Point] = ds.map(t => (t.x, t.y)) .map { x => (x._1, x._2, 1L) }.withForwardedFields("_1; _2") .reduce { (p1, p2) => (p1._1, p1._2 + p2._2, p1._3 + p2._3) }.withForwardedFields("_1") .map { x => new Point(x._1, x._2 / x._3) }.withForwardedFields("_1->x") value.print()

-
withForwardedFields("*->_n"):要求该算子输入数据的所有字段与输出的第n个字段相匹配
val env = ExecutionEnvironment.getExecutionEnvironment val ds: DataSet[Point] = env.fromElements(Point("a", 10.0), Point("b", 20.0), Point("a", 30.0)) val value: DataSet[(Int, Point)] = ds.map(t => (t.x, t.y)) .map { x => (x._1, x._2, 1L) }.withForwardedFields("_1; _2") .reduce { (p1, p2) => (p1._1, p1._2 + p2._2, p1._3 + p2._3) }.withForwardedFields("_1") .map { x => new Point(x._1, x._2 / x._3) }.withForwardedFields("_1->x") .map(t => (1, t)).withForwardedFields("*->_2") value.print()
-
withForwardedFields("_n1->_n2"):要求该算子输入数据的第n1个字段与输出的第n2个字段相匹配
val env = ExecutionEnvironment.getExecutionEnvironment val ds: DataSet[Point] = env.fromElements(Point("a", 10.0), Point("b", 20.0), Point("a", 30.0)) val value: DataSet[(String, Int)] = ds.map(t => (t.x, t.y)) .map { x => (x._1, x._2, 1L) }.withForwardedFields("_1; _2") .reduce { (p1, p2) => (p1._1, p1._2 + p2._2, p1._3 + p2._3) }.withForwardedFields("_1") .map { x => new Point(x._1, x._2 / x._3) }.withForwardedFields("_1->x") .map(t => (1, t)).withForwardedFields("*->_2") .map(p => ("test", p._1)).withForwardedFields("_1->_2") // 输入的第一个字段和输出的第二个字段匹配 value.print()
1.1.2. 双输入算子转发字段
withForwardFieldsFirst函数的第一个输入规则定义,定义内容语法与 withForwardedFields 一致withForwardedFieldsSecond函数的第二个输入规则定义,定义内容语法与 withForwardedFields 一致
val env = ExecutionEnvironment.getExecutionEnvironment
val ds1 = env.fromElements((1, "a"), (1, "b"), (2, "c"), (3, "d"))
val ds2 = env.fromElements((1, "just"), (2, "have"), (3, "a"), (4, "try"))
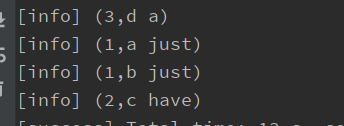
val result = ds1.join(ds2).where(0).equalTo(0) {
(p1, p2) => (p1._1, p1._2 + " " + p2._2)
}.withForwardedFieldsFirst("_1")
result.print()
注意:如果某一个算子使用的是创建RichMapFunction富函数的方式对数据集进行操作,则可以通过添加@ForwardedFields(Array("*->_2"))注释的方式定义转发字段。
1.2. Read Fields(读取字段注解)
-
在指定读取字段信息时,必须将在条件语句中评估或用于计算的字段标记为已读。只有未经修改的字段转发到输出,而不评估其值或根本不被访问的字段不被视为被读取。
@ReadFields("_1; _4") // _1 and _4 2 个字段分别用于函数条件语句判断与结果计算. class MyMap extends MapFunction[(Int, Int, Int, Int), (Int, Int)]{ def map(value: (Int, Int, Int, Int)): (Int, Int) = { if (value._1 == 42) { return (value._1, value._2) } else { return (value._4 + 10, value._2) } } }
2. Flink 1.10源代码编译,基于Flink release-1.10分支Centos6
本次编译是基于hadoop-2.8.3和hadoop-2.9.2两种情况进行编译
2.1. maven的安装
-
- 拷贝下载链接
cd /home/hadoop/fanjh wget https://archive.apache.org/dist/maven/maven-3/3.5.4/binaries/apache-maven-3.5.4-bin.tar.gz
- 拷贝下载链接
-
解压
tar -zxvf apache-maven-3.5.4-bin.tar.gz mv apache-maven-3.5.4 /usr/local/ -
配置环境变量
vi /etc/profile export MAVEN_HOME=/usr/local/apache-maven-3.5.4 export PATH=$PATH:$MAVEN_HOME/bin source /etc/profile #使配置文件生效 -
测试
mvn -v
-
编译构建工具,最好在构建maven环境时将maven运行的Xmx和Xms参数适当调大 -
在Maven settings.xml中配置阿里的maven仓库地址,可加速依赖下载速度.
<mirrors> <mirror> <id>nexus-aliyun</id> <mirrorOf>central</mirrorOf> <name>Nexus aliyun</name> <url>https://maven.aliyun.com/nexus/content/groups/public</url> </mirror> <!-- <mirror> <id>cloudera</id> <name>cloudera</name> <url>https://repository.cloudera.com/artifactory/cloudera-repos</url> <mirrorOf>*,!mapr-releases,!confluent</mirrorOf> </mirror>--> <mirror> <id>nexus-aliyun-apache</id> <mirrorOf>central</mirrorOf> <name>Nexus aliyun apache</name> <url>https://maven.aliyun.com/nexus/content/repositories/apache-snapshots/</url> </mirror> <mirror> <id>mapr-public</id> <mirrorOf>mapr-releases</mirrorOf> <name>mapr-releases</name> <url>https://maven.aliyun.com/repository/mapr-public</url> </mirror> </mirrors> -
注意!!!修改settings.xml文件,配置本地仓库<localRepository>D:\apache-maven-3.5.4\local_repository</localRepository>
2.2. Linux下安装git
-
注意
确认安装gcc环境变量配置注意事项:echo “export PATH=$PATH:/usr/local/git/bin” >> /etc/profile这里的双引号是英文的引号·

-
测试

-
idea中设置git步骤

-
解决中文乱码问题# 解决IDEA下的terminal中文Unicode编码问题 export LANG="zh_CN.UTF-8" export LC_ALL="zh_CN.UTF-8"



2.3. 开始构建
-
创建工作目录:
mkdir flink_code_location -
将 [flink] 项目仓库fork到自己的github

-
从自己的github中pull flink的源代码
git clone git@github.com:fanjianhai/flink.git-
Git配置SSH访问GitHub
-
生成秘钥对:
ssh-keygen -t rsa -C "594042358@qq.com"(注意:此处邮箱为github账号邮箱)

-
拷贝公钥到github
id_rsa.pub -> Github -> Settings→SSH kyes→Add SSH key

-
测试
git config --global user.name "xiaofan" git config --global user.email "594042358@qq.com" ssh -T git@github.com
-
注意:根据测试的warning信息,需要修改/etc/hosts文件

-
不同的机器用同一个账户访问github时,同样需要重新生成ssh key

-
-
配置管理SSH key
当本地存储使用多个ssh key时,需要通过config文件(/home/hadoop/.ssh/config)来切换默认账户,ssh config文件常用配置如下:Host github.com Hostname github.com User git Identityfile ~/.ssh/id_rsa_github- Host: “personal.github.com"是一个"别名”,可以随意命名, 像github-PERSONAL这样的命名也可以;
- HostName:比如我工作的git仓储地址是ssh://g@gitlab.baidu.com/abc.git, 那么我的HostName就要填"baidu.com";
- IdentityFile: 所使用的公钥文件;
-
多个SSH key测试


-
从自己的github中pull flink的源代码成功效果展示

-
-
分支准备:进入flink代码目录,
cd flink;(注意:要检出指定版本的远程分支,下文有介绍)- 切换到flink-1.10分支,
git checkout release-1.10 - 从此分支构建自己的分支,
git checkout -b my_branch_base_release-1.10
- 切换到flink-1.10分支,
-
执行编译:
mvn clean package -T 4 -Dfast -Pinclude-hadoop -Dhadoop.version=2.8.3 -Dmaven.compile.fork=true -DskipTests -Dscala-2.11 -
参数说明:
mvn \ #清理往次的maven构建记录和结果 clean \ #安装/打包 install /package \ #支持多处理器或者处理器核数参数,加快构建速度,推荐Maven3.3及以上(本次编译用的maven3.5.4.版本) -T 4 \ #在flink根目录下pom.xml文件中fast配置项目中含快速设置,其中包含了多项构建时的跳过参数. #例如apache的文件头(rat)合法校验,代码风格检查,javadoc生成的跳过等,详细可阅读pom.xml -Dfast \ #官方文档中声明有预构建完成的几个版本,可参考官方文档.本地版调试学习如果不涉及到state的文件系统存储持久化则不需要开启此配置项 -Pinclude-hadoop -Dhadoop.version=2.8.3 \ #允许多线程编译,推荐maven在3.3及以上 -Dmaven.compile.fork=true \ -DskipTests \ #之所以不开启-Dmaven.test.skip=true而使用此选项时因为如果要完整构建flink项目, #其中flink-test*模块中的代码非test范围,而其中使用了flink-runtime中test代码构建, # 所以如果不在根目录pom.xml中注释掉flink-test*模块,使用此选项会报错找不到相关包或者类 -Dscala-2.11 #制定flink的scala版本代码 -
编译结果
编译成功以后可用的flink文件夹资源在flink/build-target文件夹下


-
集群本地模式启动

端口冲突了,依据log日志修改一下端口

-
大功告成!!!
2.4. 对于在编译过程当中找不到flink-shaded-hadoop-2的情况
-
报错情况

原因是cdh 的flink-shaded-hadoop-2的jar 包在mvn 中央仓库是没有编译版本的,我们需要先对flink 的前置依赖flink-shaded-hadoop-2进行打包,在进行编译 -
创建flink-shaded-hadoop-2编译工作目录
mkdir flink-shaded-hadoop-2 -
进入,flink-shaded-hadoop-2 github仓库, 获取flink-shaded git 源码
注意:要先fork到之前自己配好的github仓库,然后进行克隆

-
如何选择flink-shaded的版本
-
根据报错情
Could not find artifact org.apache.flink:flink-shaded-hadoop-2:jar:2.9.2-9.0 in central (https://repo.maven.apache.org/maven2),此处缺少版本9.0 -
检测当前flink-shaded对应版本的分支
git tag

-
根据自己缺少的版本切换对应的代码分支,这里我缺少的是
9.0版本的flink-shaded-hadoop-2git switch -c release-9.0
-
-
修改flink-shaded项目中的pom.xml 这里修改是为了加入cdh 等中央仓库,否则编译对应版本可能找不到cdh 相关的包
<profile> <id>vendor-repos</id> <activation> <property> <name>vendor-repos</name> </property> </activation> <!-- Add vendor maven repositories --> <repositories> <!-- Cloudera --> <repository> <id>cloudera-releases</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </repository> <!-- Hortonworks --> <repository> <id>HDPReleases</id> <name>HDP Releases</name> <url>https://repo.hortonworks.com/content/repositories/releases/</url> <snapshots><enabled>false</enabled></snapshots> <releases><enabled>true</enabled></releases> </repository> <repository> <id>HortonworksJettyHadoop</id> <name>HDP Jetty</name> <url>https://repo.hortonworks.com/content/repositories/jetty-hadoop</url> <snapshots><enabled>false</enabled></snapshots> <releases><enabled>true</enabled></releases> </repository> <!-- MapR --> <repository> <id>mapr-releases</id> <url>https://repository.mapr.com/maven/</url> <snapshots><enabled>false</enabled></snapshots> <releases><enabled>true</enabled></releases> </repository> </repositories> </profile> -
编译cdh flink-shaded-hadoop-2
mvn clean install -DskipTests -Drat.skip=true -Pvendor-repos -Dhadoop.version=2.9.2

-
将编译的源码包下的
/home/hadoop/flink_code_location/flink-shaded-hadoop-2/flink-shaded/flink-shaded-hadoop-2-uber/target/flink-shaded-hadoop-2-uber-2.9.2-9.0.jar拷贝到$FLINK_HOME/lib/下即可。这里一定要使用flink-shaded-hadoop2-uber下的包,如果使用flink-shaded-hadoop2会缺少类。

-
编译flink
mvn clean package -T 4 -Dfast -Drat.skip=true -Pinclude-hadoop -Dhadoop.version=2.9.2 -Dmaven.compile.fork=true -DskipTests -Dscala-2.11

-
至此,就编译好了基于
hadoop-2.9.2的Flink-1.10版本,可以部署集群提交到yarn集群了(我们公司目前用的hadoop2.9.2) -
注意:先编译flink-shaded,再编译flink,编译完flink,相应的flink-shaded-hadoop-2-uber-2.9.2-9.0.jar包就会进入flink的lib目录

2.5. 参考链接
3. git/github学习笔记
3.1. 通过git命令提交文件到github演示


3.2. git命令大全

3.3. 详细实战
-
常用名词

Workspace:工作区 Index / Stage:暂存区 Repository:仓库区(或本地仓库) Remote:远程仓库 -
新建代码库# 在当前目录新建一个Git代码库 $ git init # 新建一个目录,将其初始化为Git代码库 $ git init [project-name] # 下载一个项目和它的整个代码历史 $ git clone [url]
-
Git的设置文件为.gitconfig,它可以在用户家目录下(全局配置),也可以在项目目录下.git/config(项目配置)。# 显示当前的Git配置 $ git config --list # 编辑Git配置文件 $ git config -e [--global] # 设置提交代码时的用户信息 $ git config [--global] user.name "[name]" $ git config [--global] user.email "[email address]” git 修改当前的project的用户名的命令为: $ git config user.name 你的目标用户名; git修改当前的project提交邮箱的命令为: $ git config user.email 你的目标邮箱名; 如果你要修改当前全局的用户名和邮箱时,需要在上面的两条命令中添加一个参数,–global,代表的是全局。 命令分别为: $ git config --global user.name 你的目标用户名; $ git config --global user.email 你的目标邮箱名;
-
增加/删除文件# 添加指定文件到暂存区 $ git add [file1] [file2] ... # 添加指定目录到暂存区,包括子目录 $ git add [dir] # 添加当前目录的所有文件到暂存区 $ git add . # 添加每个变化前,都会要求确认 # 对于同一个文件的多处变化,可以实现分次提交 $ git add -p # 删除工作区文件,并且将这次删除放入暂存区 $ git rm [file1] [file2] ... # 停止追踪指定文件,但该文件会保留在工作区 $ git rm --cached [file] # 改名文件,并且将这个改名放入暂存区 $ git mv [file-original] [file-renamed]git add -p对于同一个文件的多处变化,可以实现分次提交(提交到暂存,感觉实用性不是很强, 一般一个文件修改了都会提交到暂存吧)
-
代码提交# 提交暂存区到仓库区 $ git commit -m [message] # 提交暂存区的指定文件到仓库区 $ git commit [file1] [file2] ... -m [message] # 提交工作区自上次commit之后的变化,直接到仓库区 $ git commit -a # 提交时显示所有diff信息 $ git commit -v # 使用一次新的commit,替代上一次提交 # 如果代码没有任何新变化,则用来改写上一次commit的提交信息 $ git commit --amend -m [message] # 重做上一次commit,并包括指定文件的新变化 $ git commit --amend [file1] [file2] ... -
分支(重点)# 列出所有本地分支 $ git branch # 列出所有远程分支 $ git branch -r # 列出所有本地分支和远程分支 $ git branch -a # 新建一个分支,但依然停留在当前分支 $ git branch [branch-name] # 新建一个分支,并切换到该分支 $ git checkout -b [branch] git checkout -b appoint_box(别名) origin/feature/20181128_1491627_appoint_box_1(分支名) # 新建一个分支,指向指定commit $ git branch [branch] [commit] # 新建一个分支,与指定的远程分支建立追踪关系 $ git branch --track [branch] [remote-branch] # 切换到指定分支,并更新工作区 $ git checkout [branch-name] # 切换到上一个分支 $ git checkout - # 建立追踪关系,在现有分支与指定的远程分支之间 $ git branch --set-upstream [branch] [remote-branch] # 合并指定分支到当前分支 $ git merge [branch] # 选择一个commit,合并进当前分支 $ git cherry-pick [commit] # 删除分支 $ git branch -d [branch-name] # 删除远程分支 $ git push origin --delete [branch-name] $ git branch -dr [remote/branch]-
查看分支
- 列出所有本地分支
git branch - 列出所有远程分支
git branch -r - 列出所有本地分支和远程分支
git branch -a

- 列出所有本地分支
-
新建分支
- 新建一个分支,但依然停留在当前分支
git branch [branch-name] - 新建一个分支,并切换到该分支
git checkout -b [branch] - 新建一个分支,指向指定commit
git branch [branch] [commit] - 新建一个分支,与指定的远程分支建立追踪关系
git branch --track [branch] [remote-branch]



- 新建一个分支,但依然停留在当前分支
-
切换分支
- 切换到指定分支,并更新工作区
git checkout [branch-name] - 切换到上一个分支
git checkout - - [git checkout 可替换命令 git switch 和 git restore]

- 切换到指定分支,并更新工作区
-
合并分支
- 新建一个分支,与指定的远程分支建立追踪关系
git branch --track [branch] [remote-branch] - git 创建远程新分支
- 合并指定分支到当前分支
git merge [branch]
提示Your branch is up-to-date with ‘origin/master’ 该怎么办 - 选择一个commit,合并进当前分支
git cherry-pick [commit]
- 新建一个分支,与指定的远程分支建立追踪关系
-
删除分支
- 本地
git branch -d [branch-name] - 远程
git push origin --delete [branch-name](不要带origin/)
- 本地
-
-
标签# 列出所有tag $ git tag # 新建一个tag在当前commit $ git tag [tag] # 新建一个tag在指定commit $ git tag [tag] [commit] # 删除本地tag $ git tag -d [tag] # 删除远程tag $ git push origin :refs/tags/[tagName] # 查看tag信息 $ git show [tag] # 提交指定tag $ git push [remote] [tag] # 提交所有tag $ git push [remote] --tags # 新建一个分支,指向某个tag $ git checkout -b [branch] [tag] -
查看信息- 显示有变更的文件
git status
- 显示当前分支的版本历史
git log

- 显示指定文件相关的每一次diff
git log -p [file]

- 显示过去5次提交
git log -5 --pretty --oneline - 显示所有提交过的用户,按提交次数排序
git shortlog -sn - 显示指定文件是什么人在什么时间修改过
git blame [file]
- 显示有变更的文件
-
远程同步$ git remote update --更新远程仓储 # 下载远程仓库的所有变动 $ git fetch [remote] # 显示所有远程仓库 $ git remote -v # 显示某个远程仓库的信息 $ git remote show [remote] # 增加一个新的远程仓库,并命名 $ git remote add [shortname] [url] # 取回远程仓库的变化,并与本地分支合并 $ git pull [remote] [branch] # 上传本地指定分支到远程仓库 $ git push [remote] [branch] # 强行推送当前分支到远程仓库,即使有冲突 $ git push [remote] --force # 推送所有分支到远程仓库 $ git push [remote] --all -
上传本地项目到远程仓库

3.4. git原理
3.5. git从远程仓库gitLab上拉取指定分支到本地仓库
















 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









