







目录
一、工具定位与目标
工具名称:公众号文章链接批量提取助手
核心功能:通过输入公众号名称 / 关键词,批量获取其历史文章链接,支持按时间 / 阅读量筛选,适配多公众号批量操作。
应用场景:
- 新媒体运营者采集竞品内容
- 研究者批量获取特定领域公众号数据
- 企业品牌监测公众号相关报道
二、COZE 功能模块搭建
1. 触发方式
- 用户输入触发:用户在对话中输入 “提取公众号文章链接”+ 关键词(如 “提取 科技美学 文章链接”)。
- 按钮触发:在 COZE 界面添加 “批量提取” 按钮,点击后唤起输入框引导用户填写公众号名称 / 多个名称(用逗号分隔)。
2. 核心能力配置
(1)公众号搜索模块
- 调用接口:通过 COZE 的 “网络搜索” 能力,对接微信公众平台搜索接口(需合规授权,或使用第三方数据平台如清博指数、新榜的 API)。
- 参数解析:
- 提取用户输入的公众号名称(支持模糊搜索,如 “财经” 可匹配多个相关公众号)。
- 可选筛选条件:时间范围(近 7 天 / 30 天 / 自定义)、阅读量阈值(如≥10000)。
(2)文章链接抓取模块
- 模拟登录:通过 COZE 的 “自动化流程” 能力,模拟用户登录微信公众平台(需用户授权登录凭证,或使用 cookies 池技术)。
- 分页爬取:
- 进入目标公众号主页,识别历史文章列表分页按钮,自动翻页抓取链接。
- 解析文章列表页 HTML,提取每篇文章的标题、发布时间、链接地址。
(3)数据清洗与格式化
- 去重处理:通过 COZE 的 “数据处理” 节点,对重复链接进行过滤(基于 URL 哈希值)。
- 结构化输出:将结果整理为表格格式,包含字段:
序号 公众号名称 文章标题 发布时间 阅读量 链接 (阅读量需通过文章详情页二次爬取,或调用第三方数据接口获取)。
(4)结果交付模块
- 消息回复:在 COZE 对话中直接返回前 10 条链接,超过部分生成 “查看全部” 按钮,点击后跳转至网页版结果页。
- 文件下载:支持将结果导出为 Excel/CSV 文件,通过 COZE 的 “文件传输” 功能发送给用户。
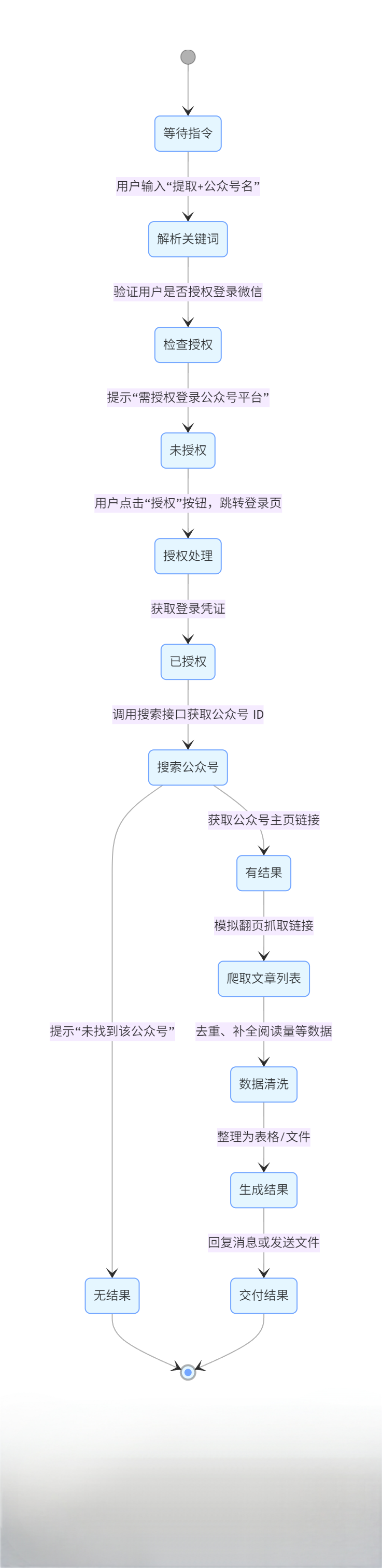
三、流程逻辑设计(状态机示例)
四、关键技术与合规性
1. 技术实现要点
- 反爬机制应对:
- 模拟真人操作频率(设置请求间隔≥3 秒)。
- 随机切换 IP 代理(通过 COZE 的 “代理池” 插件实现)。
- 识别并处理验证码(调用第三方打码平台,如 云验证码服务)。
- 数据存储:使用 COZE 内置数据库临时存储爬取结果,7 天后自动删除,避免隐私泄露。
2. 合规性说明
- 用户授权:明确告知用户工具仅用于合法用途(如内容分析、学术研究),禁止爬取涉密或侵权内容。
- 平台规则:遵守微信公众平台《开发者服务协议》,不使用暴力破解、恶意刷量等违规手段。
- 数据隐私:承诺不存储用户登录凭证,爬取的文章内容仅用于生成链接列表,不解析正文内容。
五、优化与扩展方向
- 增量更新:记录已爬取的文章链接,下次提取时仅返回新发布内容。
- 智能筛选:支持按关键词过滤文章(如提取标题含 “AI” 的文章)。
- 多平台适配:扩展其他内容平台的链接提取。
- API 开放:为企业用户提供定制化 API,支持接入自有系统进行数据集成。
通过 COZE 的可视化流程搭建能力,可快速实现上述逻辑,结合代码插件(Python/Node.js)补充核心爬取功能,最终形成一个高效、合规的公众号文章链接批量提取工具。如需进一步细化某个模块,可联系我提供更多开发参数或配置细节。

















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









