







鉴于网上的一些相关文章对于堆排序原理讲的是正确的,但算法实现上其时间复杂度根本就不对,本算法主要来自于
Data Structures & algorithms in java 第十二章
堆排序简介
堆排序与快速排序,归并排序一样都是时间复杂度为O(N*logN)的几种常见排序方法
堆是一种重要的数据结构,为一棵完全二叉树 ,堆排序是一种选择排序
二叉堆满足二个特性:
1.父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2.每个结点的左子树和右子树都是一个二叉堆(都是大根堆或小根堆)。
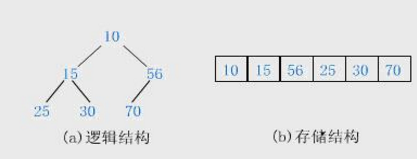
一般都用数组来表示堆,i结点的父结点下标就为[(i – 1) / 2]向下取整。它的左右子结点下标分别为2 * i + 1和2 * i + 2。如第0个结点左右子结点下标分别为1和2,结点1的子结点下标分别是3和4, 2结点下标分别是5和6
堆中最大结点的下标是currentSize-1,至少有一个子结点的最大结点下标是index,则2*index+1<=currentSize-1得到index+1<=currentSize/2;得到index<=currentSize/2-1或index<currentSize/2
筛选
一般在输出堆顶元素之后,视为将这个元素排好序,然后用堆中最后一个元素填补它的位置,自上向下进行调整:首先将堆顶元素和它的左右子树的根结点进行比较,把最小的元素交换到堆顶;然后顺着被破坏的路径一路调整下去,直至叶子结点,就得到新的堆。
我们称这个自堆顶至叶子的调整过程为"筛选",分为向下筛选,和向上筛选,每次向下筛选比向上筛选多一次比较:因为向上筛选只需要和父节点比较即可,向下筛选要和两个子节点比较
插入元素是向上筛选,因为总是插在最后;删除元素是向下筛选,因为总是删除根
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 23万+
23万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









