






我决定使用requests和BeautifulSoup两个库的功能从猫眼专业版(具体网址:影片总票房排行榜 (maoyan.com))上面获取数据。
-
目录
-
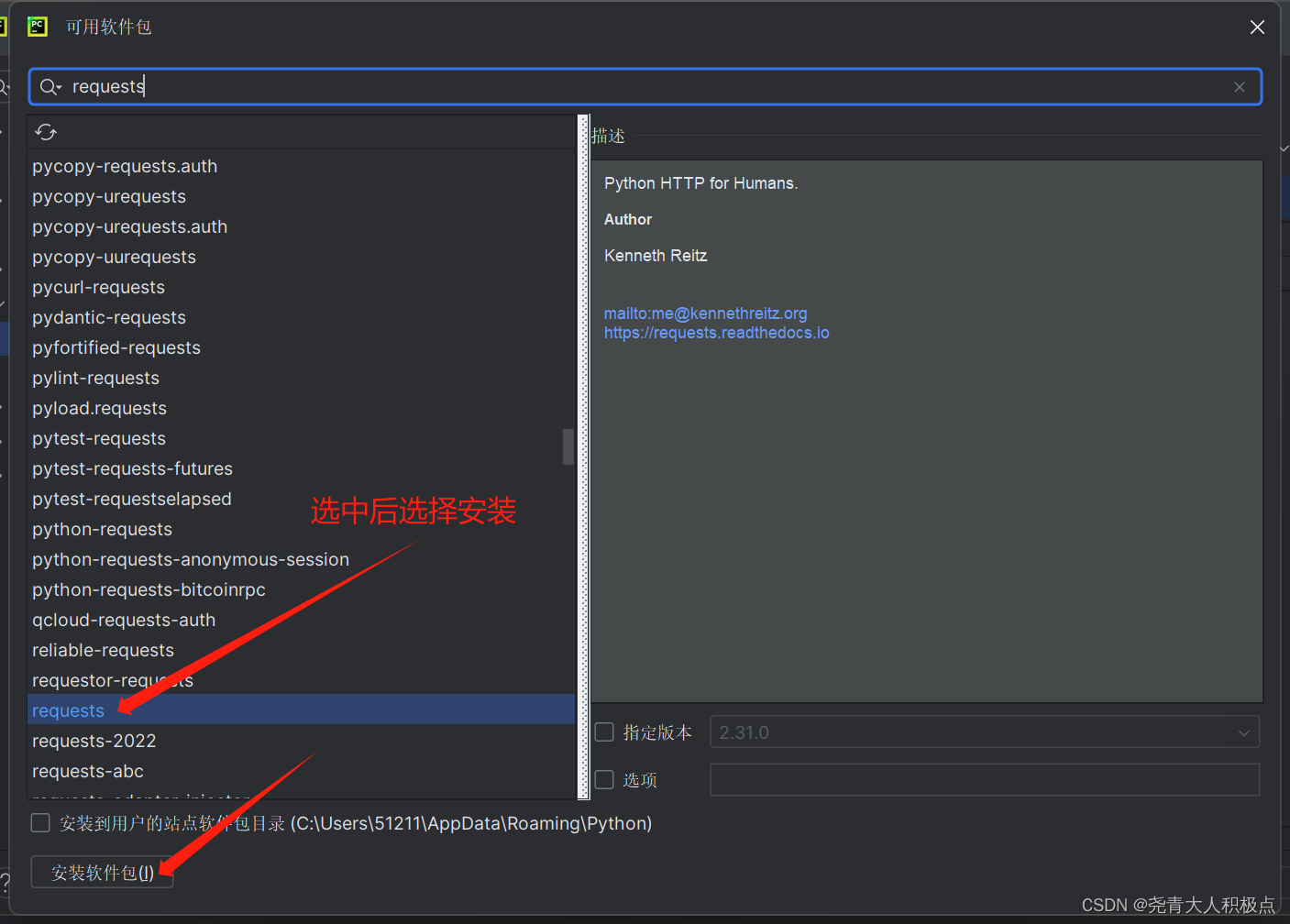
1.安装requests和BeautifulSoup
- tips:requests和BeautifulSoup是Python的扩展库,是需要提前安装的。
在pycharm的具体安装方法如下:

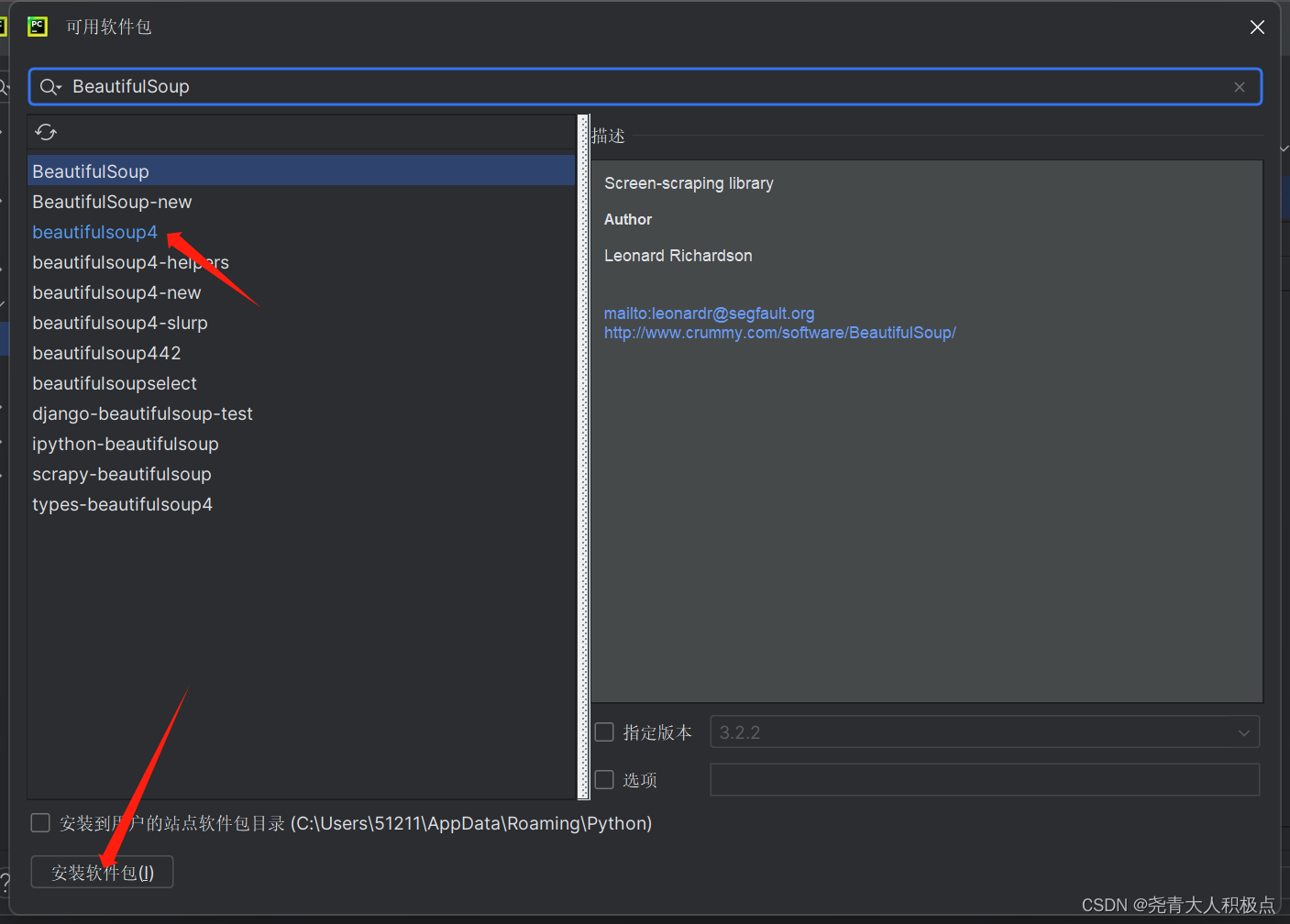
BeautifulSoup也是通过这个方法安装的:
2.关于User-Agent
在很多的网站都会设置反爬虫的功能,一般情况下我们编写的程序发出的请求会被网址拒绝,但浏览器就不会啦。所以我们要将我们编写的程序伪装成浏览器,让网站同意我们的请求。这个时候就要在我们的程序中设置一个User-Agent,将程序发出的请求伪装成浏览器的。
以下是获取User-Agent的方法:
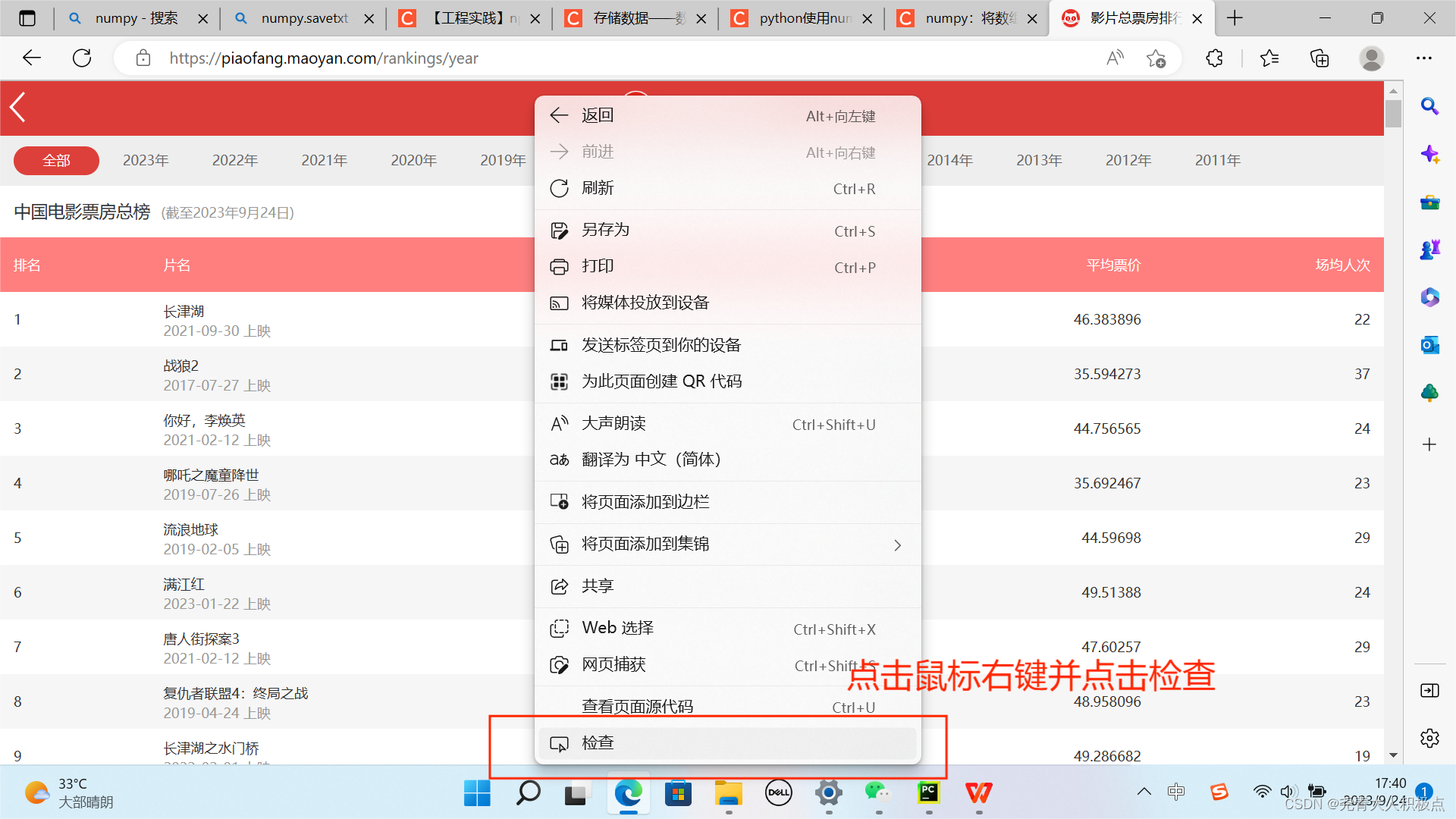
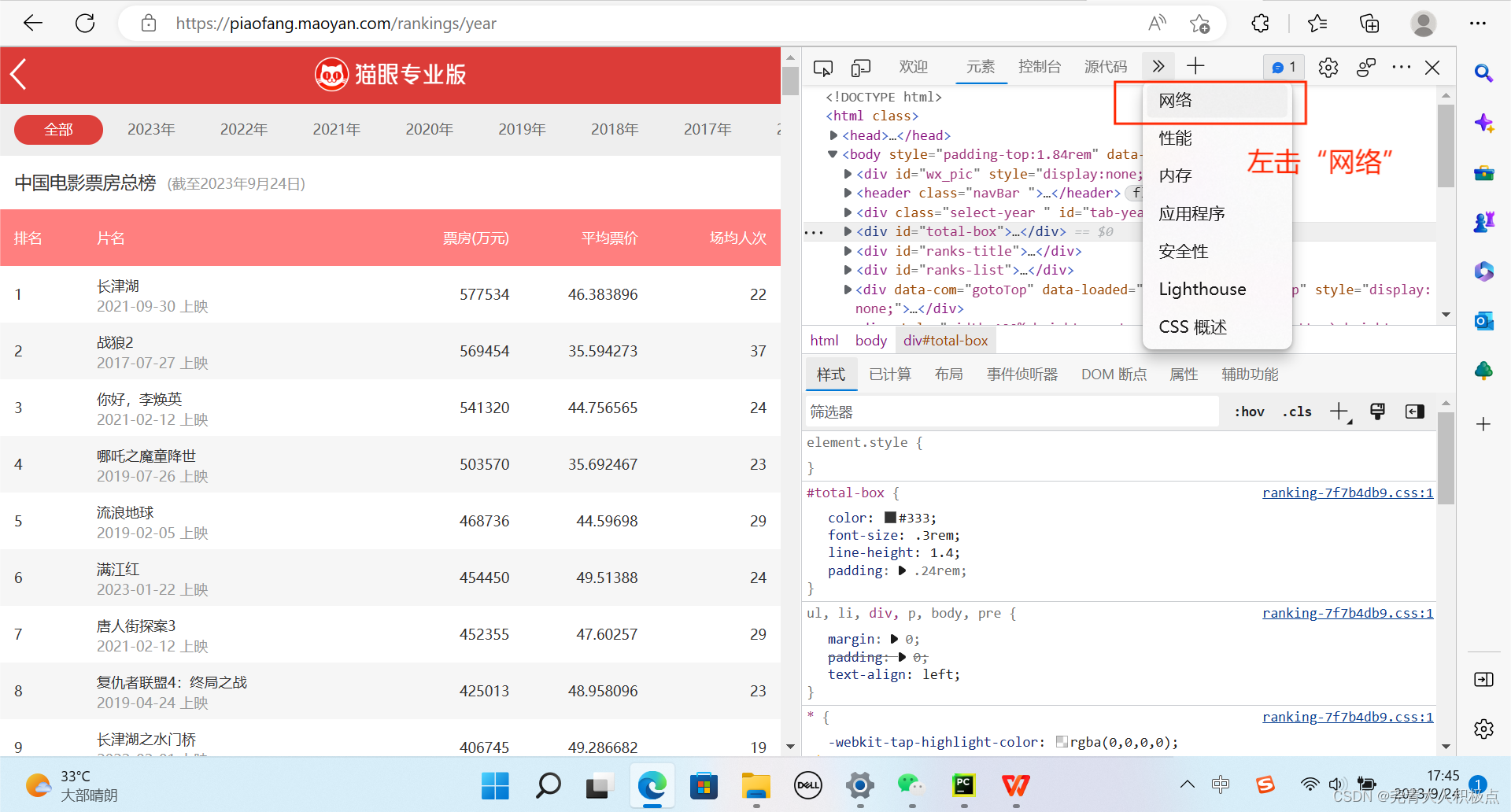
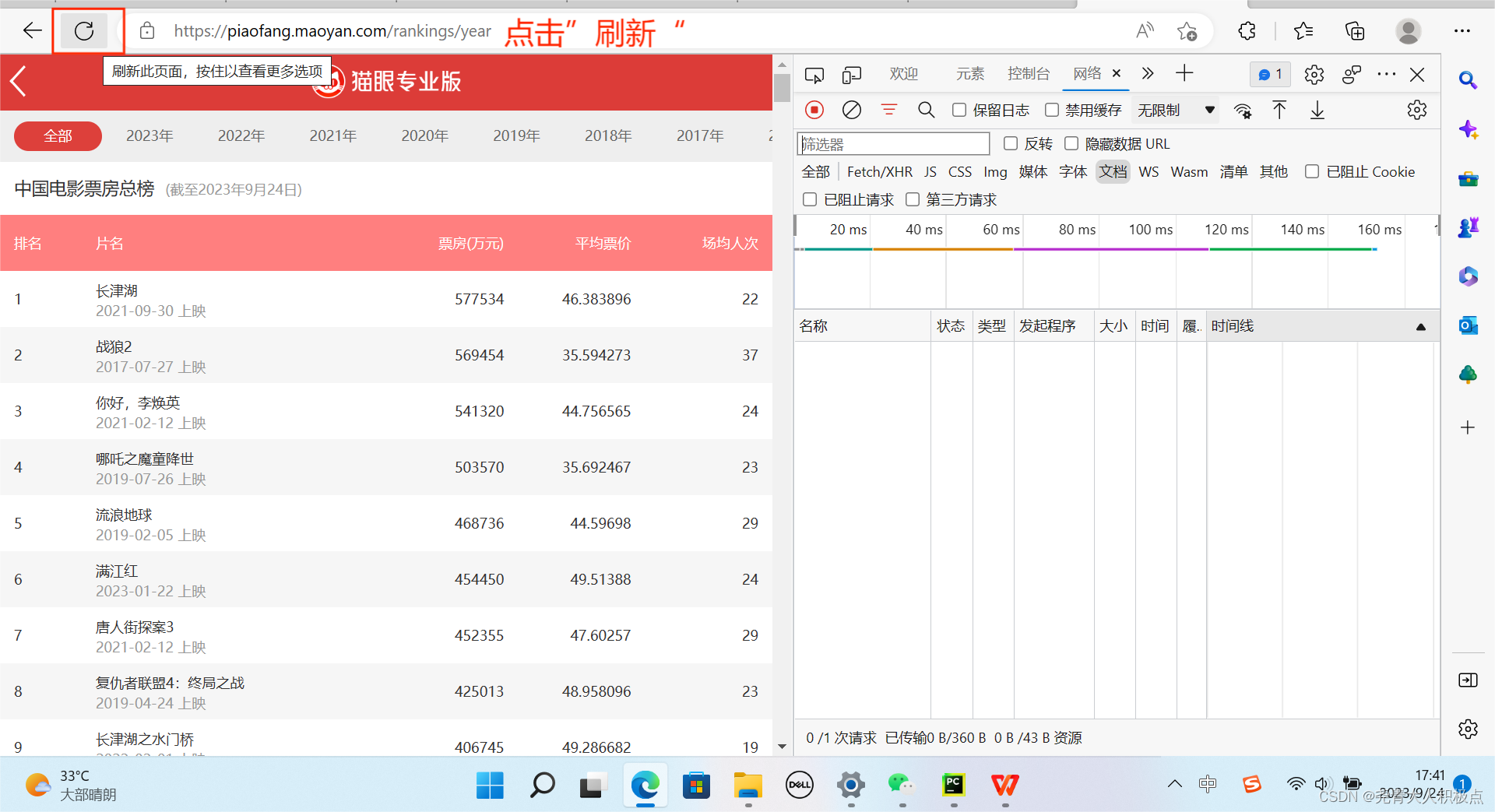

3.编写代码
本人是参考B站的老师讲授的代码【Python爬虫案例】批量爬取电影票房+数据分析可视化_哔哩哔哩_bilibili
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent" :"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.42"
} #将程序发出的请求伪装成浏览器
text = requests.get("https://piaofang.maoyan.com/rankings/year",headers=headers).text
#通过requests请求到电影票房的网页
main_page = BeautifulSoup(text,"html.parser")#后面这个是html的解析器
#使用BeautifulSoup对text进行解析
div = main_page.find("div",attrs={"id": "ranks-list"})
#找到名为div且id为ranks-list的所有标签
f = open("MovieData.csv", mode="a")
#创建一个名为MovieData.csv的文件,放在变量f中,且可以在其后面直接追加文字
uls = div.find_all('ul')
#找到div元素中所有名为ul的元素,并存储在uls变量中
for ul in uls : #对uls中的元素进行遍历
lst1 = ul.find_all("li", attrs={"class": "col1"})#找到ul中所有类名为col1的Li元素,并储存在lst1
lst2 = ul.find_all("li", attrs={"class": "col2"})#找到ul中所有类名为col2的Li元素,并储存在lst2
lst3 = ul.find_all("li", attrs={"class": "col3"})#找到ul中所有类名为col3的Li元素,并储存在lst3
lst4 = ul.find_all("li", attrs={"class": "col4"})#找到ul中所有类名为col4的Li元素,并储存在lst4
for li in lst1 : #对lst1中的元素进行遍历
ps = li.find_all("p") #找到ps中所有p元素,并储存在ps
for p in ps : #对ps中的元素进行遍历
f.write(p.text.strip()) #将p标签中的文本去除分隔符后写进f中的文件
f.write(",") #在f文件后面追加,
for li in lst2: #对lst2中的元素进行遍历
f.write(li.text.strip()) #将li标签中的文本去除分隔符后写进f中的文件
f.write(",") #在f文件后面追加,
for li in lst3: #对lst3中的元素进行遍历
f.write(li.text.strip()) #将li标签中的文本去除分隔符后写进f中的文件
f.write(",") #在f文件后面追加,
for li in lst4: #对lst4中的元素进行遍历
f.write(li.text.strip()) #将li标签中的文本去除分隔符后写进f中的文件
f.write(",") #在f文件后面追加,
f.write("\n") #在f文件后面追加换行符该文章仅作为本人的学习记录,如有错误,请各位大佬指出。

















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









