






在Kafka集群中创建主题名称为englishscore,主题的分区数为3,副本因子为3。分别使用生产者异步不带回调函数的API(前100名学生)、异步带回调函数的API(100~200名学生)、同步AP(200~300名学生)完成学生英语成绩的生产。键为姓名,值为成绩。
启动zookeeper集群
zkServer.sh start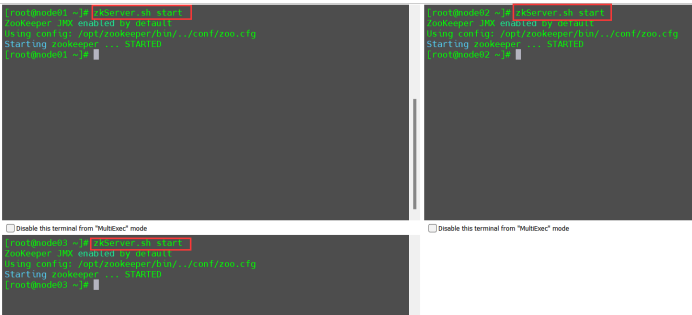
启动kafka集群
cd /opt/kafka
bin/kafka-server-start.sh -daemon config/server.properties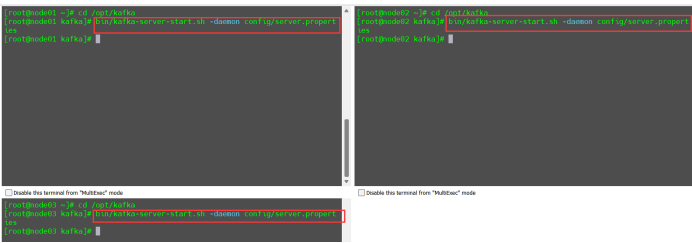
创建主题名称为englishscore,主题的分区数为3,副本因子为3
bin/kafka-topics.sh --zookeeper node01:2181,node02:2181 --partitions 3 --replication-factor 3 --create --topic englishscore
查看主题englishscore的详细信息
bin/kafka-topics.sh --zookeeper node01:2181,node02:2181 --describe --topic englishscore
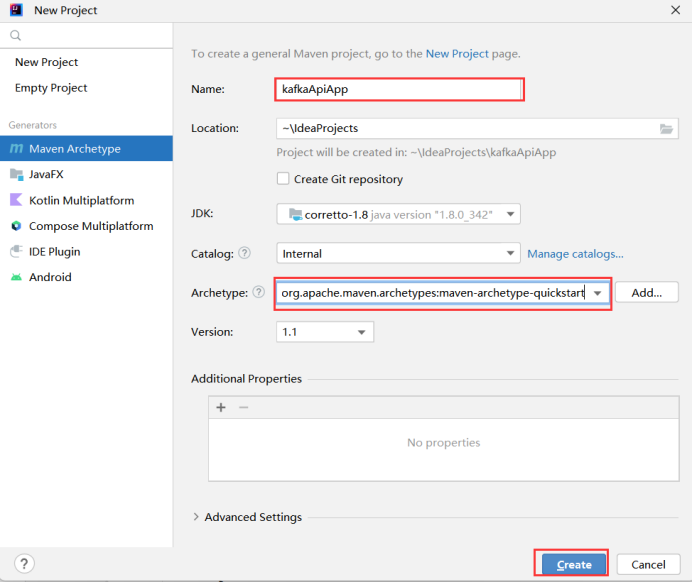
打开IDEA开发工具,创建项目名称为kafkaApiApp,添加Pom文件
pom文件中添加kafka依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
</dependencies>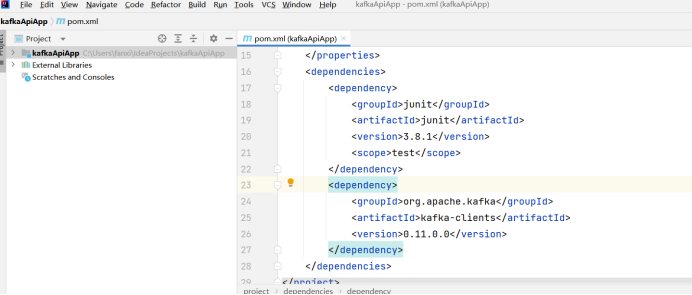
创建生产者异步不带回调函数的API(前100名学生)的类CustomProducer
键为zhangsan+序号,值为100以内的随机数
package cn.lesson;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.Random;
public class CustomProducer {
public static void main(String[] args) {
Random random = new Random();
Properties props = new Properties();
//kafka 集群,broker-list
props.put("bootstrap.servers", "node01:9092,node02:9092");
props.put("acks", "all");
//重试次数
props.put("retries", 1);
//批次大小
props.put("batch.size", 16384);
//等待时间
props.put("linger.ms", 1);
//RecordAccumulator 缓冲区大小
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new
KafkaProducer<String, String>(props);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("englishscore",
"zhangsan"+Integer.toString(i), Integer.toString(random.nextInt(100))));
}
producer.close();
}
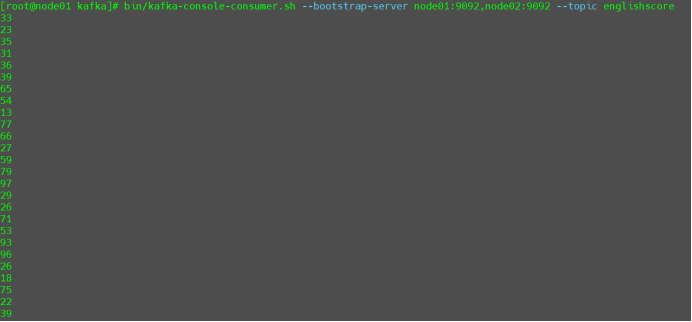
}Kafka集群启动控制台消费者进程,消费主题englishscore
bin/kafka-console-consumer.sh --bootstrap-server node01:9092,node02:9092 --topic englishscoreIDEA中,执行CustomProducer代码,查看消费者控制台执行效果
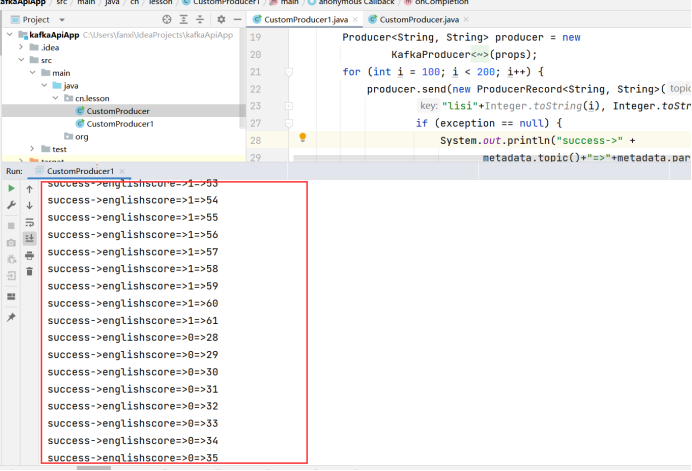
编写异步带回调函数的API(100~200名学生)的代码CustomProducer1
键为lisi+序号,值为100以内的随机数,并打印消息所在的主题、分区、消费位移
package cn.lesson;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.Random;
public class CustomProducer1 {
public static void main(String[] args) {
Random random = new Random();
Properties props = new Properties();
props.put("bootstrap.servers", "node01:9092,node02:9092");//kafka 集群,broker-list
props.put("acks", "all");
props.put("retries", 1);//重试次数
props.put("batch.size", 16384);//批次大小
props.put("linger.ms", 1);//等待时间
props.put("buffer.memory", 33554432);//RecordAccumulator 缓冲区大小
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new
KafkaProducer<String, String>(props);
for (int i = 200; i < 300; i++) {
producer.send(new ProducerRecord<String, String>("englishscore",
"lisi"+Integer.toString(i), Integer.toString(random.nextInt(100))), new Callback() {
//回调函数,该方法会在 Producer 收到 ack 时调用,为异步调用
public void onCompletion(RecordMetadata metadata,
Exception exception) {
if (exception == null) {
System.out.println("success->" +
metadata.topic()+"=>"+metadata.partition()+"=>"+metadata.offset());
} else {
exception.printStackTrace();
}
}
});
}
producer.close();
}
}运行CustomProducer1代码,消费者控制台查看执行结果
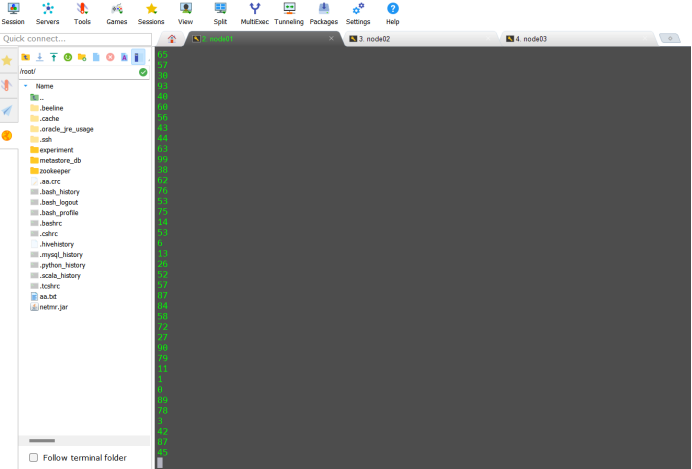
12.编写同步API(200~300名学生)CustomProducer2,键为lisi+序号,值为100以内的随机数。
package cn.lesson;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.Random;
import java.util.concurrent.ExecutionException;
public class CustomProducer2 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Random random = new Random();
Properties props = new Properties();
props.put("bootstrap.servers", "node01:9092,node02:9092");//kafka 集群,broker-list
props.put("acks", "all");
props.put("retries", 1);//重试次数
props.put("batch.size", 16384);//批次大小
props.put("linger.ms", 1);//等待时间
props.put("buffer.memory", 33554432);//RecordAccumulator 缓冲区大小
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new
KafkaProducer<String, String>(props);
for (int i = 200; i < 300; i++) {
producer.send(new ProducerRecord<String, String>("englishscore",
"wangwu"+Integer.toString(i), Integer.toString(random.nextInt(100)))).get();
}
producer.close();
}
}13.运行CustomProducer1代码,消费者控制台查看执行结果
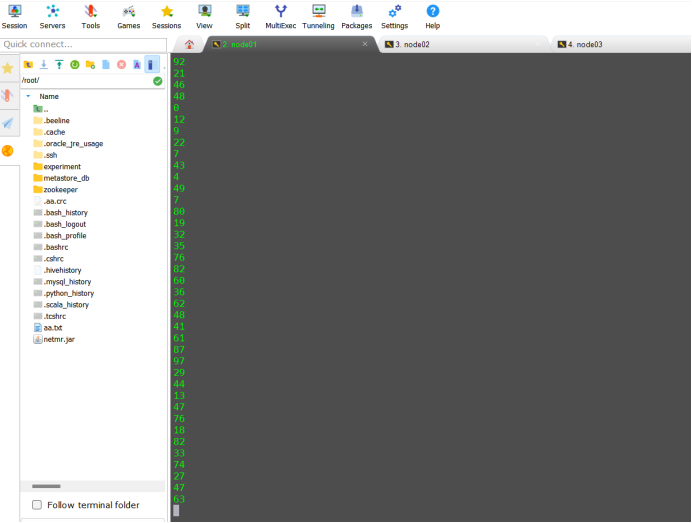















 1023
1023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









