







Adult数据集
adult 数据集的任务是预测一名工人的收入是高于 50 000 美元还是低于 50 000 美元。这个数据集的特征包括工人的年龄、雇用方式(独立经营、私营企业员工、政府职员等)、教育水平、性别、每周工作时长、职业,等等。

这个数据集需要自己在网上下载,在百度里搜即可,其他博主已经整理好了下载的链接。
使用独热向量编码来对分类变量进行数据表示
由上一个title中的表得知,类似于性别gender、教育程度education等特征,它们都是以字符串的形式呈现的,显然无法作为机器学习模型的输入(输入应该是numPy或scipy格式的数组),因此需要进行数据预处理。数据预处理的方法是使用独热向量编码(one-hot)。独热向量很好理解,看下表即可,相当于用一位表示一个状态。
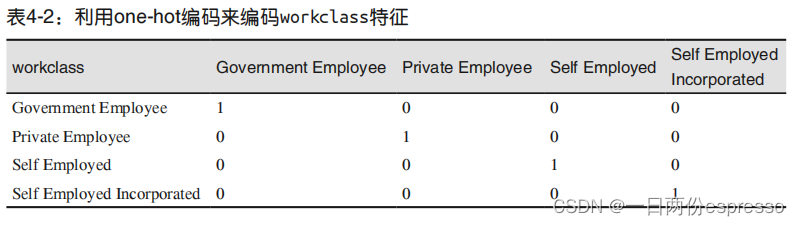
用到的工具:pandas.DataFrame的get_dummies方法
import pandas as pd
from IPython.display import display
# 文件中没有包含列名称的表头,因此我们传入header=None
# 然后在"names"中显式地提供列名称
data = pd.read_csv(
"data/adult.data", header=None, index_col=False,
names=['age', 'workclass', 'fnlwgt', 'education', 'education-num',
'marital-status', 'occupation', 'relationship', 'race', 'gender' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1534
1534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









