




第一次安装,走了不少弯路
- 环境 centos7,jdk1.8,hadoop2.6.4
(1) 先安装jdk,配置环境
1)JAVA_HOME为/usr/local/java/jdk1.8.0_101
2)vim /etc/profile文件追加以下内容
1. JAVA_HOME=/usr/local/jdk1.8.0_101
2. CLASS_PATH=$JAVA_HOME/lib
3. PATH=$JAVA_HOME/bin:$PATH
4. export PATH JAVA_HOME CLASS_PATH
然后esc退出编辑,:wq 退出保存
(2) 安装hadoop
l 参考http://blog.csdn.net/l1028386804/article/details/51536051
l http://www.cnblogs.com/caca/p/centos_hadoop_install.html
l 下载 hadoop-xxx.tar.gz,不要下载成源码(src)
l 解压到usr/Hadoop/Hadoop.xxx下
l 修改配置
vim /etc/profile
exportHADOOP_HOME=/usr/Hadoop/Hadoop.xxx
exportPATH=$PATH:$HADOOP_HOME/bin,并保存退出
#source /etc/profile 使配置生效
=============================
vim./hadoop-env.sh
exportJAVA_HOME=/usr/java/jdk1.8.0_101/
并保存退出
接着要修改HADOOP_HOME 目录下的/etc/hadoop目录下的几个的文件
core-site.xml 【ip地址改成localhost也可】
#vim core-site.xml,直接复制替换
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<description>.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
replication 是数据副本数量,默认为3,salve少于3台就会报错
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<configuration>
mapred-site.xml,不存在,复制mapred-site.xml.template,修改成该文件
修改Hadoop中MapReduce的配置文件,配置的是JobTracker的地址和端口。
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://192.168.1.249:9001</value>
</property>
</configuration>
启动 Hadoop
格式化HDFS文件系统
Hdfs namenode-format
启动
在启动前关闭集群中所有机器的防火墙,不然会出现datanode开后又自动关闭
service iptablesstop
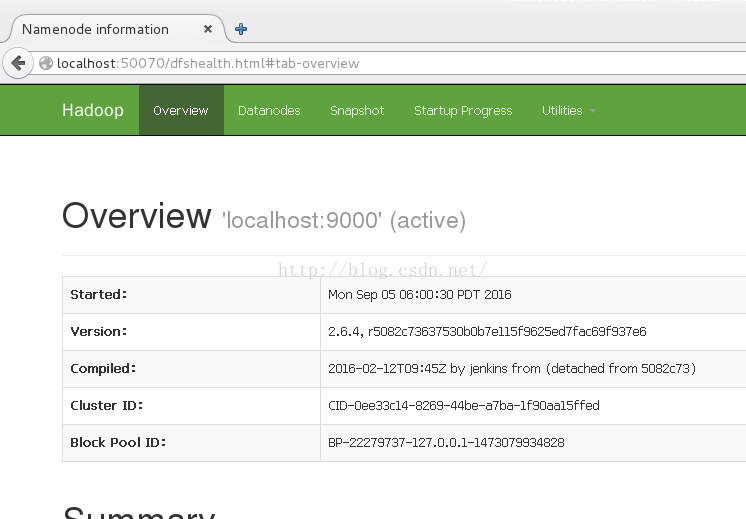
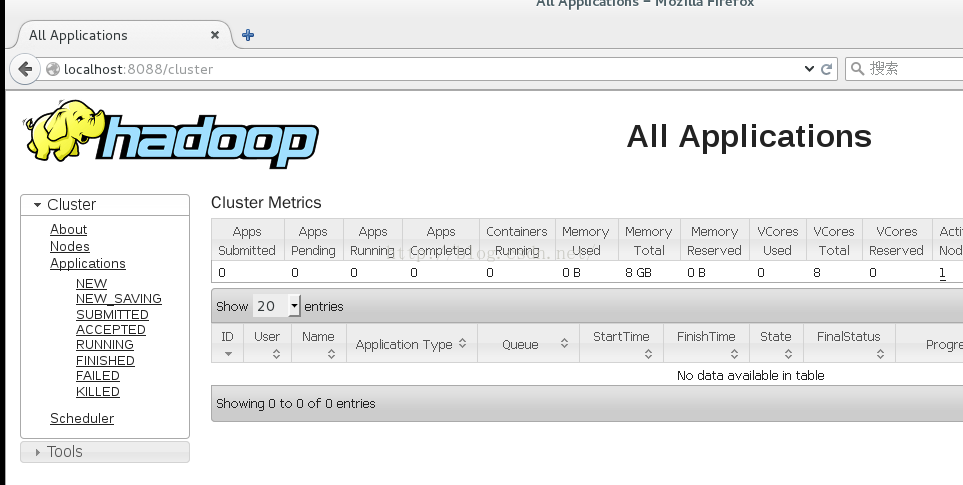
启动:./start-all.sh在sbin下执行#./start-all.sh
启动验证
1)执行jps命令,有如下进程,说明Hadoop正常启动
# jps
54679 NameNode
54774 DataNode
15741 Jps
9664 Master
55214 NodeManager
55118 ResourceManager
54965 SecondaryNameNode

















 3214
3214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









