







【备注】知识点很简单主要是想尝试下markdown
目录
防盗链Filter
网站A中有一资源,其地址为URL,要保证只有本网站的页面通过下载链接才能下载。其他网站链接该URL或是直接访问均不能获取该资源。
实验过程
现有页面
- getHeader_referer.jsp
- getHeader_referer1.jsp
- getHeader_referer2.jsp
页面主要内容
- getHeader_referer.jsp
<%
String str=request.getHeader("referer");
String serverName=request.getServerName();
%>
<%=str %>
<%=serverName %>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>original page</title>
</head>
<body>
<br>
this is original page.<br>
<a href="getHeader_referer1.jsp">page1</a>
</body>
</html>- getHeader_referer1.jsp
<%
String str=request.getHeader("referer");
String serverName=request.getServerName();
%>
<%=str %>
<%=serverName %>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>page 1</title>
</head>
<body>
<br>
this is original page.<br>
<a href="getHeader_referer2.jsp">page2</a>
</body>
</html>- getHeader_referer2.jsp
<%
String str=request.getHeader("referer");
String serverName=request.getServerName();
%>
<%=str %>
<%=serverName %>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Insert title here</title>
</head>
<body>
<br>
this is page 1.<br>
<a href="getHeader_referer.jsp">origin page</a>
</body>
</html>页面关系
实验过程中页面间会有如下链接关系:0
执行过程
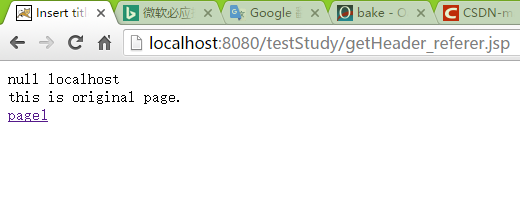
- 访问origin page
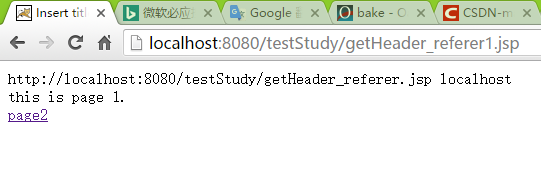
- 点击page1链接
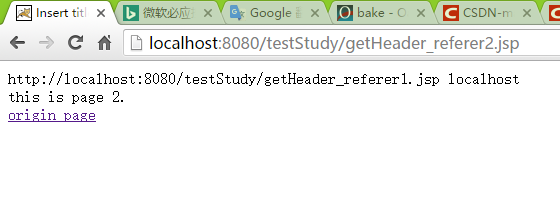
- 点击page2链接
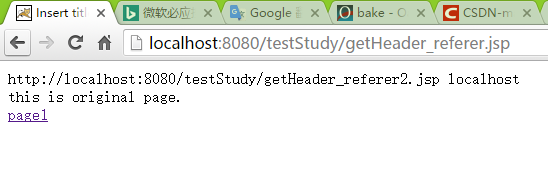
点击origin page链接
分析过程
<%=str %> //输出request.getHeader("referer")值—页面跳转前的页面
<%=serverName %> //服务器名当直接访问某url时,str为null.
通过链接访问时则会打印跳转前页面url—本页面的参考页面。因此,当资源请求时,利用Filter先获取来源地址url,【1】直接访问为url=null 【2】网站链接访问资源时url=来源地址,当来源地址中不包含本站serverName,即资源请求从非本站发出。*【1】【2】均为非法不允许访问,可以直接导向错误页面资源。*















 1065
1065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









