







学习内容:
【精选】强化学习笔记1:强化学习概述_强化学习 序列决策问题_UQI-LIUWJ的博客-CSDN博客
强化学习笔记2:序列决策(Sequential Decision Making)过程_UQI-LIUWJ的博客-CSDN博客
一、导论
强化学习讨论的问题是智能体(Agent)怎么在复杂、不确定的环境(Environment)中最大化它能获得的奖励。
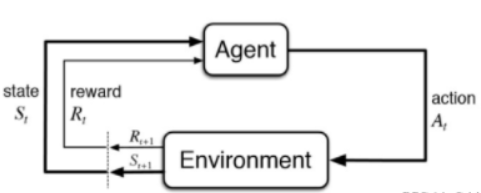
强化学习由两部分组成:智能体和环境。在强化学习过程中,智能体与环境一直在交互。智能体在环境中获取某个状态后,它会利用该状态输出一个动作(Action),这个动作也称为决策(Decision)。然后这个动作会在环境中被执行,环境会根据智能体采取的动作,输出下一个状态以及当前这个动作带来的奖励。
智能体的目的就是尽可能多地从环境中获取奖励。
二、强化学习与其他方法的比较
强化学习VS监督学习
监督学习:1.为了便于网络的学习,要尽可能使输入的数据(即标注的数据)没有关联;
2.在训练过程中,需要把正确的标签信息传递给神经网络,这样才能修正。
强化学习中这两点并不满足!
比如多臂老虎机这个实验就不满足这两点。(【多臂老虎机】采取什么操作策略才能使获得的累积奖励最高?)
Agent获得自己能力的过程中,其实是通过不断地试错探索(trial-and-error exploration)
- 探索(exploration)和利用(exploitation)是强化学习里面非常核心的一个问题。
- 探索:你会去尝试一些新的行为,这些新的行为有可能会使你得到更高的奖励,也有可能使你一无所有。
- 利用:采取你已知的可以获得最大奖励的行为,你就重复执行这个动作就可以了,因为你已经知道可以获得一定的奖励。
- 因此,我们需要在探索和利用之间取得一个权衡,这也是在监督学习里面没有的情况。
在强化学习过程中,没有非常强的监督者(supervisor),只有一个奖励信号(reward signal),并且这个奖励信号是延迟的,就是环境会在很久以后告诉你之前你采取的行为到底是不是有效的。
极大极小化(maxmin)
最大化最小的?
动态规划
对于连续决策型问题,可以使用动态规划。但【前提】是对手的全部信息要作为输入提前提交给算法。
【改进版】——对手建模:在训练时和对手多次交手,从而记录学习出对手的信息
进化方法
1.比如在“策略空间”的hill-climb,这并不是一下子就找到最优的方法,而是像爬山 一样,每一步都找到一个能提高Agent表现的方案,是逐渐找出能提高表现的策略。
2.遗传方法:优胜劣汰,直接评估大量的策略,去除不合格的,留下好的,然后产生新一代的,以此迭代,直到问题解决。
三、RL Agent的主要组成部分
- 策略函数(policy function):agent 会用这个函数来选取下一步的动作。
- 价值函数(value function):我们用价值函数来对当前状态进行估价,它就是说你进入现在这个状态,可以对你后面的收益带来多大的影响。当这个价值函数大的时候,说明你进入这个状态越有利。
- 模型(model):模型表示了 agent 对这个环境的状态进行了理解,它决定了这个世界是如何进行的。
Policy Function
是一个函数,将输入的状态变成行为。决定了Agent的行为。

Value Function
价值函数是对未来奖励的一个预测,用来评估状态的好坏。

还有一种价值函数是Q函数
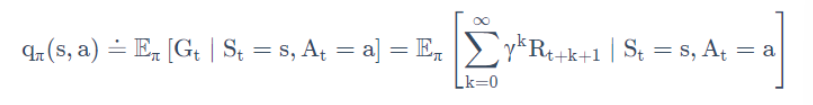
与V函数不同,Q函数里面包含有两个变量:状态s和动作a,而V函数只包含状态s这一个变量。
V函数与Q函数的关系
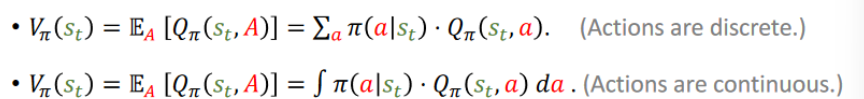
Model
模型决定了下一个状态会是什么样的(以及如果你选择了这个状态的话,你会得到多大的奖励),就是说下一步的状态取决于你当前的状态以及你当前采取的行为。
由两个部分构成:

四、强化学习分类
1.有无模型
- model-based(有模型):它通过学习环境的状态转移来采取动作。
- model-free(免模型) :它没有去直接估计环境状态的转移,也没有得到环境的具体转移变量。它通过学习价值函数和策略函数进行决策。Model-free 的模型里面没有一个环境转移的模型。
1.1有模型强化学习
马尔可夫决策过程,表示为四元组 <S,A,P,R>,即状态集合、动作集合、状态转移函数和奖励函数。

1.2无模型强化学习
State其实是环境的State!
然而在实际应用中,智能体并不是那么容易就能知晓马尔可夫决策过程中的所有元素的。
通常情况下,状态转移函数和奖励函数很难估计,甚至连环境中的状态都可能是未知的,这时就需要采用免模型学习。
免模型学习没有对真实环境进行建模,智能体只能在真实环境中通过一定的策略来执行动作,等待奖励和状态迁移,然后根据这些反馈信息来更新行为策略,这样反复迭代直到学习到最优策略。(让 agent 跟环境进行交互,采集到很多的轨迹数据)
1.3有模型强化学习和无模型强化学习的区别
无模型强化学习通常属于数据驱动型方法,需要大量的采样来估计状态、动作及奖励函数,从而优化动作策略。
有模型强化学习可以在一定程度上缓解训练数据匮乏的问题,因为智能体可以在虚拟环境中进行训练,而虚拟环境知道状态转移函数。
有模型强化学习相比于无模型强化学习仅仅多出一个步骤,即对真实环境进行建模。
在实际应用中,如果不清楚该用有模型强化学习还是无模型强化学习,可以先思考一下,在智能体执行动作前,是否能对下一步的状态和奖励进行预测,如果可以,就能够对环境进行建模,从而采用有模型学习。
2.基于策略(Policy-Based RL)和基于价值(Value-Based RL)
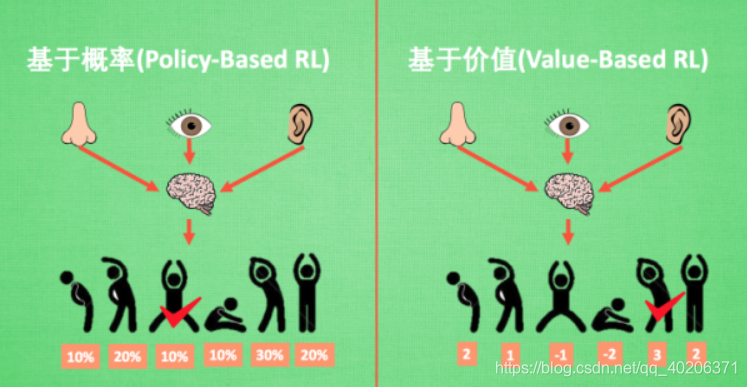
2.1 基于策略(Policy-Based RL)
- 通过分析所处的环境,直接输出下一步要采取的各种动作的概率,然后根据概率采取行动,所以每种动作都有可能被选中,只是可能性不同
- 并不去学习价值函数,而是学习Policy,或者而是直接给它一个状态,它就会输出这个动作的概率
基于策略迭代:
智能体会制定一套动作策略(确定在给定状态下需要采取何种动作),并根据这个策略进行操作。
强化学习算法直接对策略进行优化,使制定的策略能够获得最大的奖励。
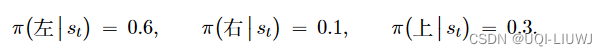
2.2 基于价值(Value-Based RL)
- 显式学习价值函数,输出则是所以动作的价值,根据最高价值来选择动作
- 隐式学习策略,策略是从学到的价值函数里面推算出来的
基于价值迭代:
智能体不需要制定显式的策略,它维护一个价值表格或价值函数,并通过这个价值表格或价值函数来选取价值最大的动作。
基于价值迭代的方法只能应用在不连续的、离散的环境下(如围棋或某些游戏领域),对于行为集合规模庞大、动作连续的场景(如机器人控制领域),其很难学习到较好的结果(此时基于策略迭代的方法能够根据设定的策略来选择连续的动作)。
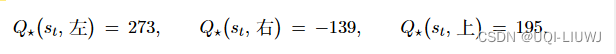
2.3 两者比较
- 相比基于概率的方法, 基于价值的决策部分更为铁定,毫不留情,就选价值最高的,而基于概率的,即使某个动作的概率最高,但是还是不一定会选到它
- 我们现在说的动作都是一个一个不连续的动作,而对于选取连续的动作,基于价值的方法是无能为力的。我们可以能用一个概率分布在连续动作中选取特定动作,这也是基于概率的方法的优点之一
- 把 value-based 和 policy-based 结合起来就有了 Actor-Critic agent。这一类 agent 把它的策略函数和价值函数都学习了,然后通过两者的交互得到一个最佳的行为。(智能体会根据策略做出动作,而价值函数会对做出的动作给出价值,这样可以在原有的策略梯度算法的基础上加速学习过程,取得更好的效果。)
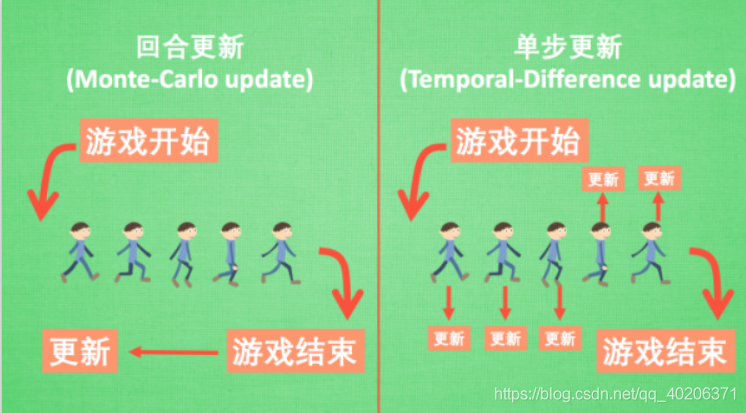
3.回合更新和单步更新
4.在线学习(On-Policy)和离线学习(Off-Policy)
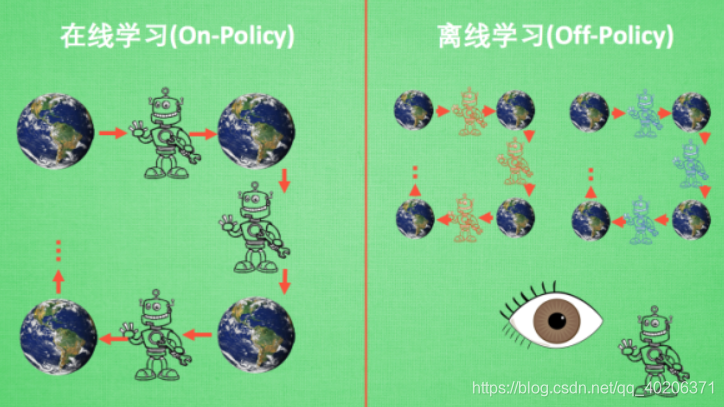
- 在线学习就是指我必须本人在场, 并且一定是本人边玩边学习。
- 离线学习是你可以选择自己玩, 也可以选择看着别人玩, 通过看别人玩来学习别人的行为准则。同样是从过往的经验中学习, 但是这些过往的经历没必要是自己的经历, 任何人的经历都能被学习。
















 749
749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









