







本章节涉及名词:cache,write buffer,TCM,logical cache,physical cache,virtual cache,locality of reference,temporal locality,spatial locality,flush cache, clean cache
本章摘录自《ARM System Develper’s Guide》第十二章,关于Cache的讲解。
This chapter contains following aspects:
1. cache architectures
2. how to clean and flush caches and to lock code and data segments in cache
Summary
本节是本章最后一节,用于知道本章概况和以后复习。
本章包含内容:cache,write buffer,the priciple of locality of reference, cache line, the placement of a cache, ways, the core bus architecture(哈弗结构和冯诺依曼结构),the cache replacement policy, write policy, allocate policy, flush and clean, lockdown and some rules to improve software performance。
具体如下:



Cache
cache能解决处理器和主存速度不匹配的问题,通常和cache一起使用的还有write buffer-a very small FIFO memory placed between processor core and main memory.
cache和write buffer have additional control hardware that handles the movement of code and data between the processor and main memory.
cache的缺点之一就是不知道哪些数据在cache中,那些在主存中。cache controller中的eviction process是用于决定留下哪些数据,移除哪些数据。
| The Memory Hierarchy and Cache Memory |
(具体图片见p404)
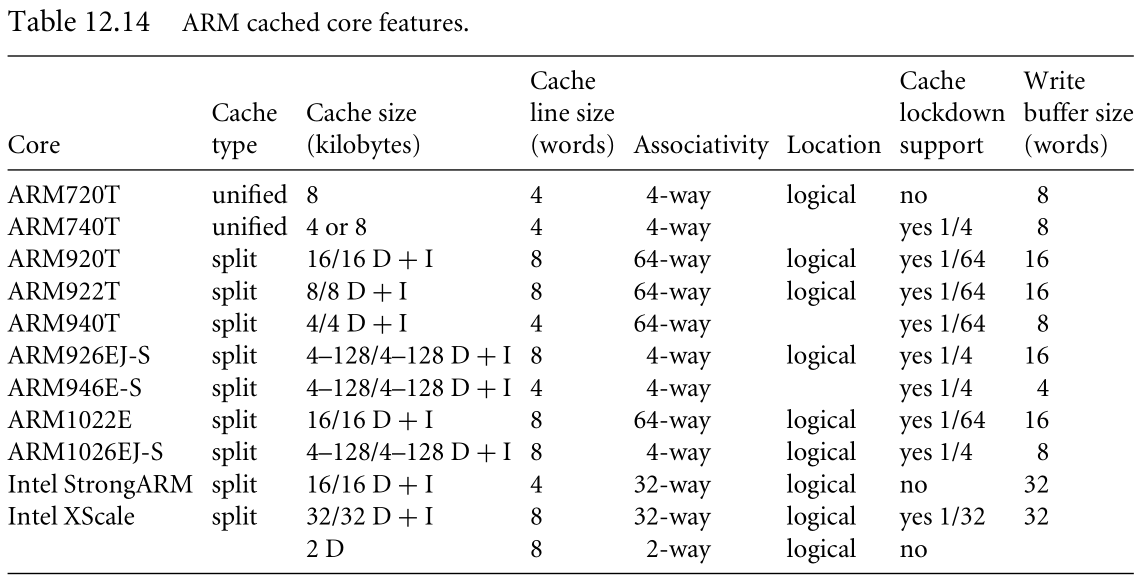
1.第一层-Processor core
2.第二层-main memory,memory components are connected to the processor core through dedicated on-chip interface.在这一层我们发现了tightly coupled memory(TCM)and level-1 cache.主存的目的是保存正在系统运行的程序。
TCM is a fast SRAM located close to the core and guarantees the clock cycles required to fetch instructions or data-critical for real-time algorithms requiring deterministic behavior.TCMs appear as memory in the address map and can be accessed as fast memory(见p35)
3.第三层-Secondary storage
我们发现memory hierarchy取决于结构设计。例如,TCM和SRAM用的相同技术,TCM is located on the chip ,while SRAM is located on a board.
cache可以被用在任何地方,因为在memory components之间速度不一致的时候,cache可以用来提高性能。cache保存的内容可以减少读取指令和数据时的时间。write buffer is used to write data to main memory from the cache.
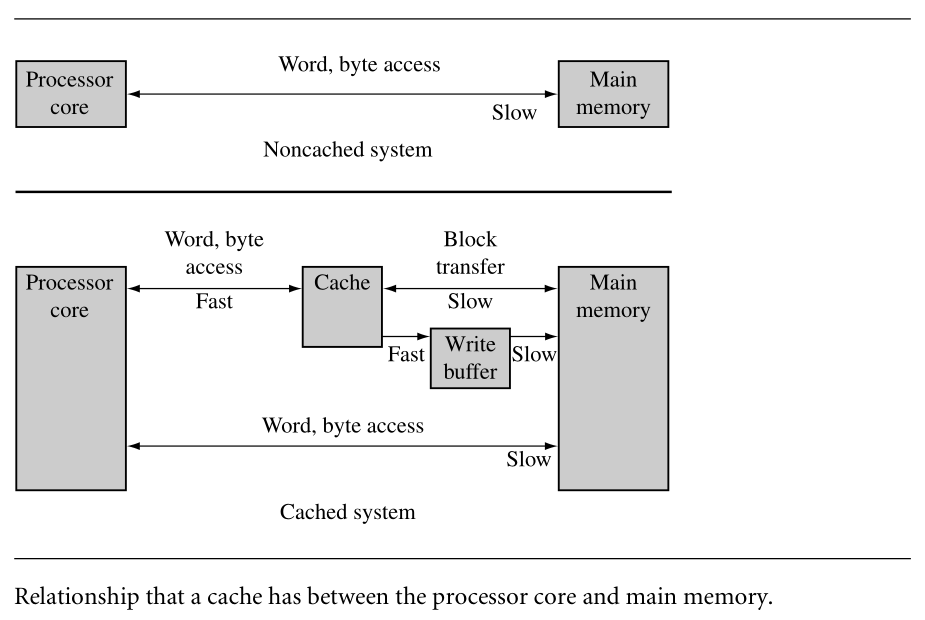
| 1-Caches and Memory Management Units |
If a cached core supports virtual memory,it can be located between the core and the memory management unit (MMU), or between the MMU and physical memory. Placement of the cache before or after the MMU determines the addressing realm the cache operates in
and how a programmer views the cache memory system.

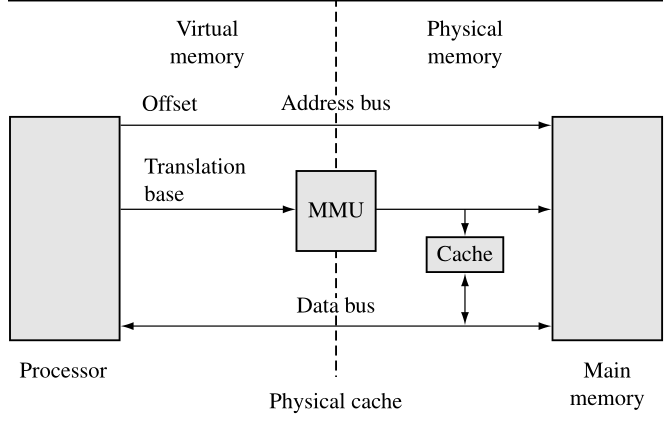

ARM7 to ARM10 use logical caches. ARM11 uses a physical cache.
预测程序的执行是cached system 成功的关键。The principle of locality of reference表明:软件会频繁在局部的数据内存空间执行很多重复的代码。通过加载第一次调用的代码和数据到高速内存中,每一次后续的调用都能节省很多时间,从而提高效率。在空间和时间上都是重复的局部调用。
If reference is in time, it is called temporal locality.If it is by address proximity, then it is called spatial locality.
| The Cache Architecture |
ARM在cached core上使用了2种总线结构。
* Von Neumann结构:对于data和instruction使用单一的cache.这种类型的cache称之为unified cache.
* Harvard结构:使用两个cache,I-Cache(for instruction),D-Cache(for data)这种类型的cache称为:split cache.
在cache之中有两大元素:the cache controller and the cache memory.Cache memory 是特定的内存数组,Cache memory 分为多个Cache Lines的单元。
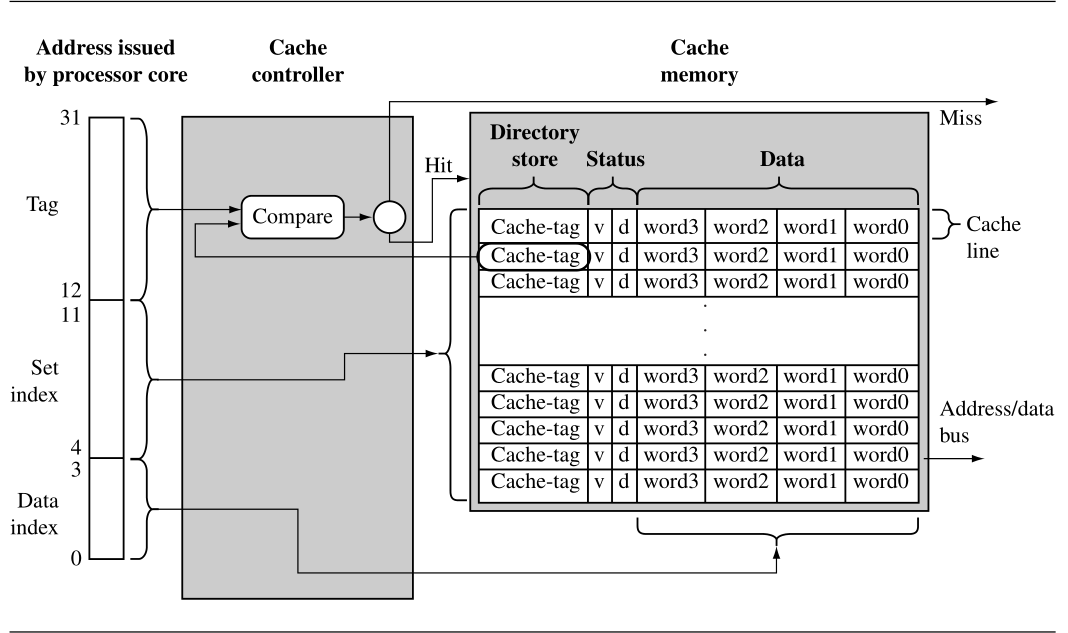
| 1-Basic Architecture of a Cache Memory |
如上图右半部分,简单的cache memory包含三部分:a directory store, a data section, and status information
- a directory store: 指明了保存的cache数据来自于主存的哪里
- data section:存储数据
- status: 包含2种状态位,valid bit: 表示a cache line 是激活状态,且数据当前对于processor core是可获得的。dirty bit: 表示当前cache line的数据已经和主存上的数据不一致了。
| 2-Basic Operation of a Cache Controller |
Cache controller是硬件用于从主存到cache memory的代码或者数据的复制。它相对于软件隐藏了cache操作,也就是说同一个程序在有cache和没有cache的系统中结果是一样的。Cache controller在将read和write memory 请求交给memory controller之前拦截了它们。它通过将请求的地址分为三部分(the tag field, the set index field, and the data index field)来处理请求。
- First, set index: to locate the cache line within the cache memory that might hold the requested code or data.This cache line contains the cache-tag and status bits, which the controller uses to determine the actual data stored there.
- Then, 通过valid bit确定cache line是否有效,然后比较the cache-tag和请求地址的tag-field。如果都符合则cache hit否则表示cache miss。
- 如果a cache miss, controller会从主存中复制整个cache line到cache memory中去,然后提供requested code and data给processor。这种复制被称之为: a cache line fill
- 如果a cache hit, 则直接provide requested code and data from cache memory to processor。这里会使用data indext field去选择cache line中实际的code和data并将其提供给处理器。
| 3-The Relationship between Cache and Main Memory |
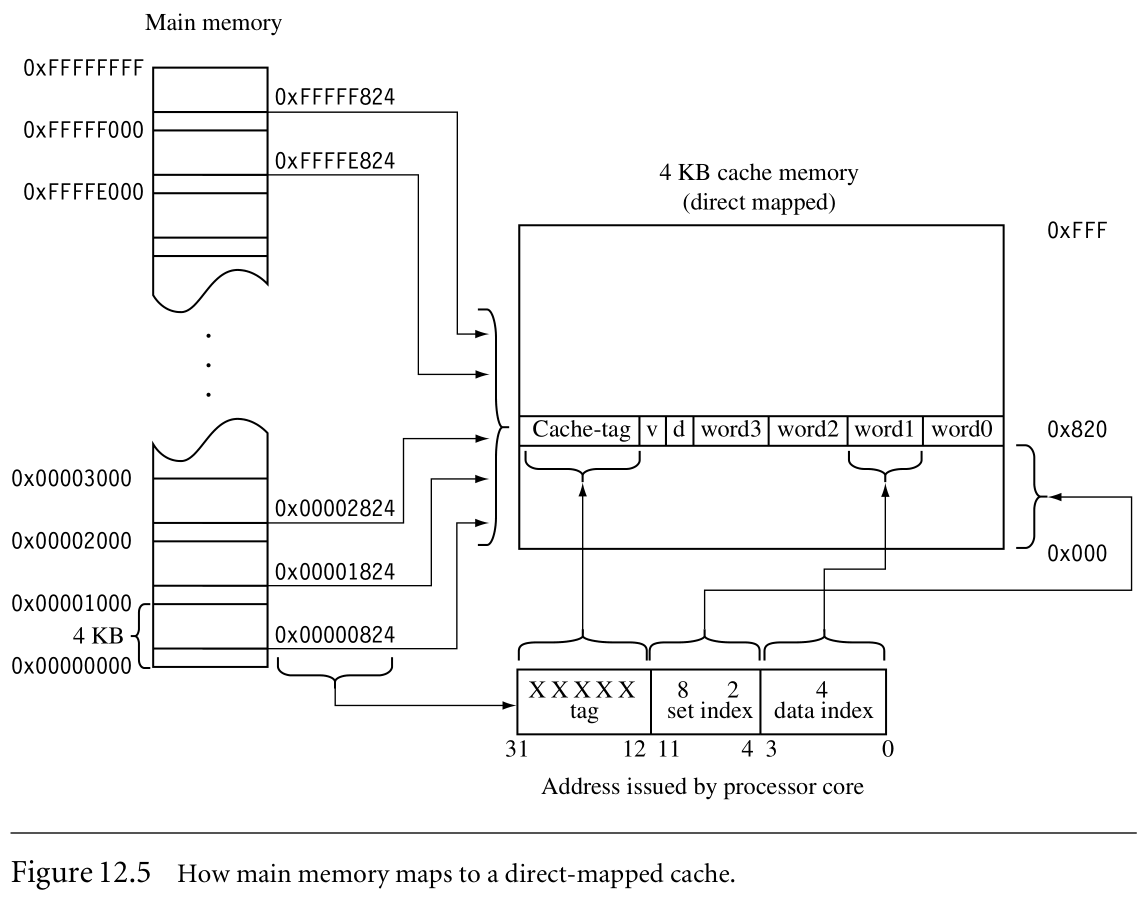
我们采用最简单的cache—a direct-mapped cache.因为主存比Cache大很多,所以主存中很多地址被map到cache memory中同一个位置上。
如图:1.set index 在以0x824结尾的cache memory中选择了一个位置。2. data index用于选择cache line中的word/halfword/byte,图中是选择了word1. 3. tag field用于和directory store里cache-tag value比较。比较决定了requested data是在cache中还是main memory中。
Cache controller可以在复制值到cache的同时,将正在加载的值提供给core,这被称之为data streaming. Streaming允许cache controller在cache line中装载剩余值的时候,processor持续地执行。
thrashing
Directed-mapped cache会出现一个问题,就是软件为cache memory上同一位置出现争夺。导致不停地cache miss和continuous eviction。
| 4-Set Associativity |
为了减少thrashing的频率,我们采用了额外的设计。如图,就是将cache memory分为了相同大小的4个ways,在four ways上的同一位置的cache line拥有相同的ste index。
The set of cache lines pointed to by the set index are set associative
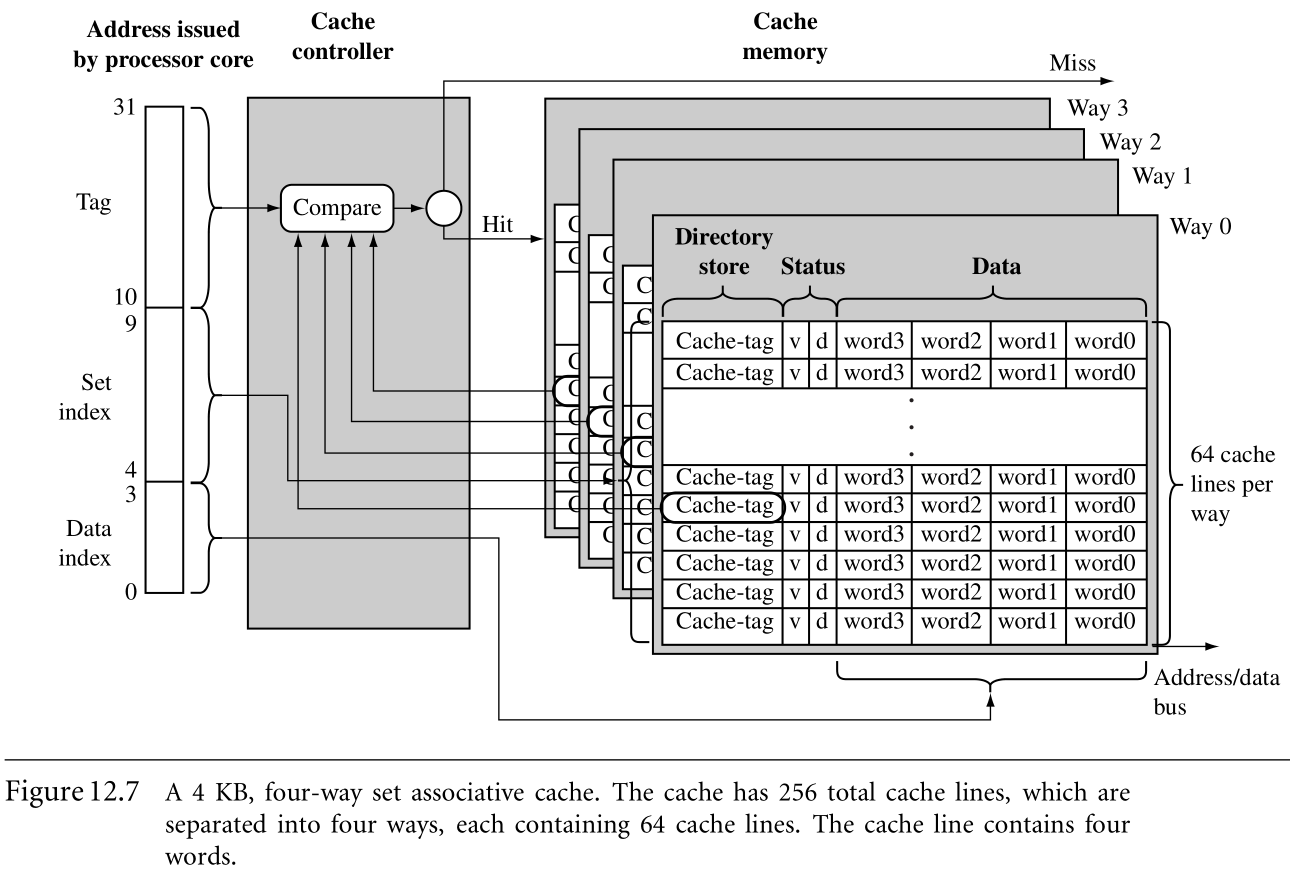
By this design, any single location in main memory now maps to four different locations in the cache.
Increasing Set Associativity
随着cache controller关联度的上升,thrashing的可能性就随之下降。最理想的状态是任何主存的位置都有cache line对应,然后这会增加硬件的复杂度。一种提升set associativities的方法就是a content addressable memory(CAM)。
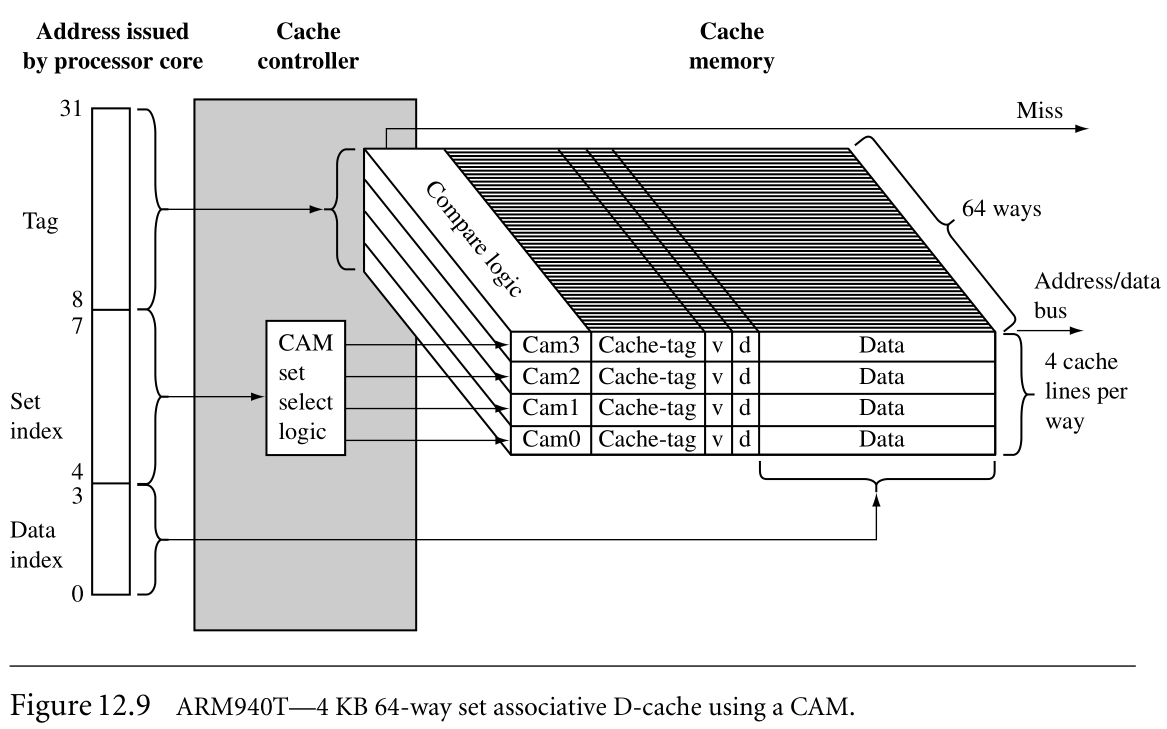
CAM使用一组比较器比较输入的tag-address和cache tag。CAM采用了和SRAM完全相反的方法:SRAM是输入address,输出data;CAM是输入data,输出address。CAM允许多个cache-tag同时比较,就增加了a set中cache line的数量。ARM940T如图,就是用了4KB 64-way set associative D-cache。
controller使用set index bits enable CAM, 通过CAM找到a cache line,然后CAM使用data index去找到cache line中需要的word,haldword或者byte。
| 5-Write Buffers |
write buffer能提高cache的性能。If the cache controller evicts a dirty cache line, it writes the cache line to the write buffer instead of main memory.Thus the new cache line data will be available sonner.
写到write buffer中的数据是不可读的,因为这个原因,write buffer 的FIFO深度仅有一些cache lines的深度。在ARM10中,write buffer可以合并新的数据到a sinle cache line中,只要它们代表了主存中相同的数据块。这种合并称之为 coalescing, write merging, write collapsing, or write combining.
| 6-Measuring Cache Efficiency |
cache efficiency有几种方式来表示:the cache hit rate , the cache miss rate.
hit rate = (cache hits / memory requests) * 100可以用这两种方法来描述读写的性能。
此外还有两种cache性能的测量方法:
1. hit time - 访问cache中内存位置的时间
2. miss penalty - 从主存加载cache line到cache中所花费的时间。
| Coprocessor 15 and caches |
There are several coprocessor 15 registers used to specifically configure and control ARM cached cores.

In the next several sections we use CP15 registers listed in Table 12.2 to provide example routines to clean and flush caches, and to lock code or data in cache.The control system usually calls these routines as part of its memory management activities.
| Flushing and Cleaning Cache Memory |
ARM使用术语flush和clean来描述关于Cache的两个基本操作。
To“flush a cache”就是值清除所有的存储数据,也就是简单的将相应cache line中valid bit位清除,另一方面可以用术语invalidate来替代flush,顾名思义就是无效化数据。然而,在使用了writeback policy的D-cache,需要的就是操作cleaning
To“clean a cache”就是强制将dirty cache lines从cache写入到main memory中,并且清除cache line中的dirty bits。clean操作保持了cached memory和main memory数据的一致性,仅仅适用于采用writeback policy的D-caches。
在两种情况下是需要flush and clean cache的:
1. The self-modifying code may be held in the D-cache with writeback policy,then when the program branches to the location where the self-modifying code should be, it will execute old instructions.To prevent this, “clean the cache”.
2. Existing instructions in the I-cache may mask new instructions written to main memory, a fetch of instructions would retrieve the old code from the I-cache and not new instructions from main memory. **”Flush the I-cache”**prevent this from happening
| Flushing ARM Cached Cores |
Flushing a cache invalidates the contents of a cache.If the cache is using a writeback policy, care should be taken to clean the cache before flushing so data is not lost as result of the flushing process.
下图分别是flush entire cache,I-cache,D-cache的MCR指令,后面是支持的core
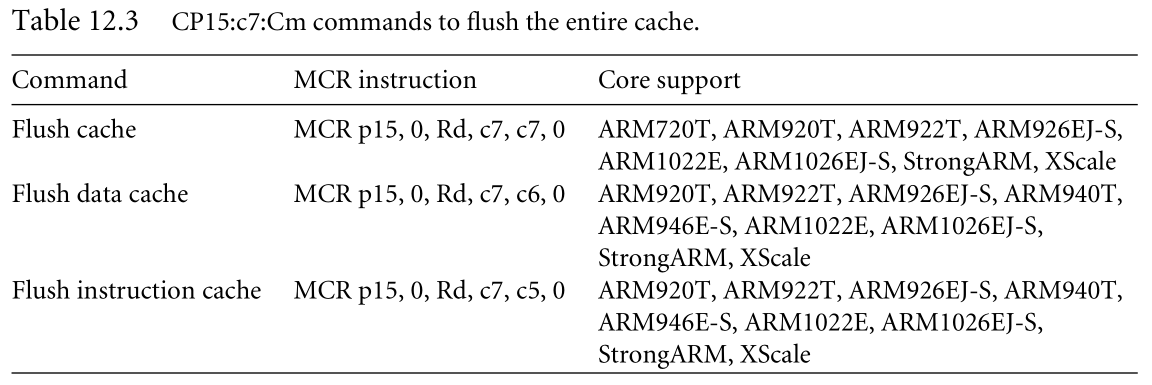
(P425~427有实际使用MCR指令进行flush cache的例子)
| Cleaning ARM Cached Cores |
如本节一开始的介绍,To“clean a cache”就是强制将dirty cache lines从cache写入到main memory中,并且清除cache line中的dirty bits。clean操作保持了cached memory和main memory数据的一致性,仅仅适用于采用writeback policy的D-caches。
术语writeback和copyback有时候用来替代clean,so to force a writeback or copyback of cache to main memory is the same as cleaning the cache.在非ARM的世界里,术语flush的意思和ARM中的clean是一样的。
| Cleaning the D-Cache |
在这本书出版的时候,有三种方法用于clean the D-Cache,这些方法是取决于具体的芯片的。方法如下:
1. Way and set index addressing
2. Test-clean
3. Special allocate command reading a dedicated block of memory
| 1-Way and Set Index Addressing |
Some ARM cores support cleaning and flushing a single cache line using the way and set index to address its location in cache. The commands available to clean and flush a cache line by way are shown as MCR instructionsinTable12.5.Two commands flush a cache line, one flushes an instruction cache line, and another flushes a data cache line. The remaining two commands clean the D-cache: one cleans a cache line and another cleans and flushes a cache line.
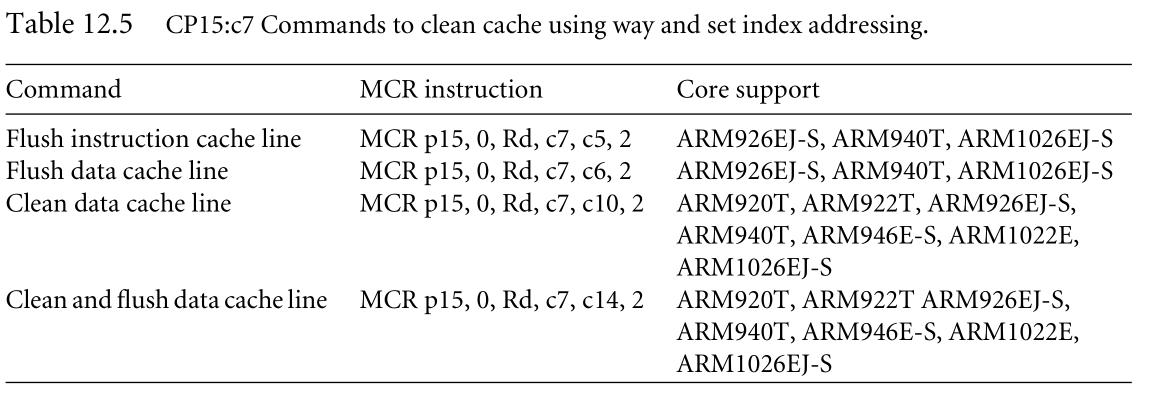
| 2-Test-Clean Command |
Two of the newer ARM cores,the ARM926EJ-S and ARM1026EJ-S,have commands to clean cache lines using a test-clean CP15:c7 register. The test clean command is a special clean instruction that can efficiently clean a cache when used in a software loop.The ARM926EJ-S and ARM1026EJ-S also support cleaning using set and way indexing; however, using the test clean command method of cleaning the D-cache is more efficient.

| 3-Special allocate command reading a dedicated block of memory |
The Intel XScale and Intel StrongARM processors use a third method to clean their D-caches. The Intel XScale processors have a command to allocate a line in the D-cache without doing a line fill. When the processor executes the command, it sets the valid bit and fills the directory entry with the cache-tag provided in the Rd register. No data is transferred from main memory when the command executes. Thus, the data in the cache is not initialized until it is written to by the processor. The allocate command, shown in Table 12.7, has the beneficial feature of evicting a cache line if it is dirty.

| Cleaning and Flushing Portions Of a Cache |
ARM cores support cleaning and flushing a single cache line by reference to the location it represents in main memory. We show these commands as MCR instructions in Table 12.8.
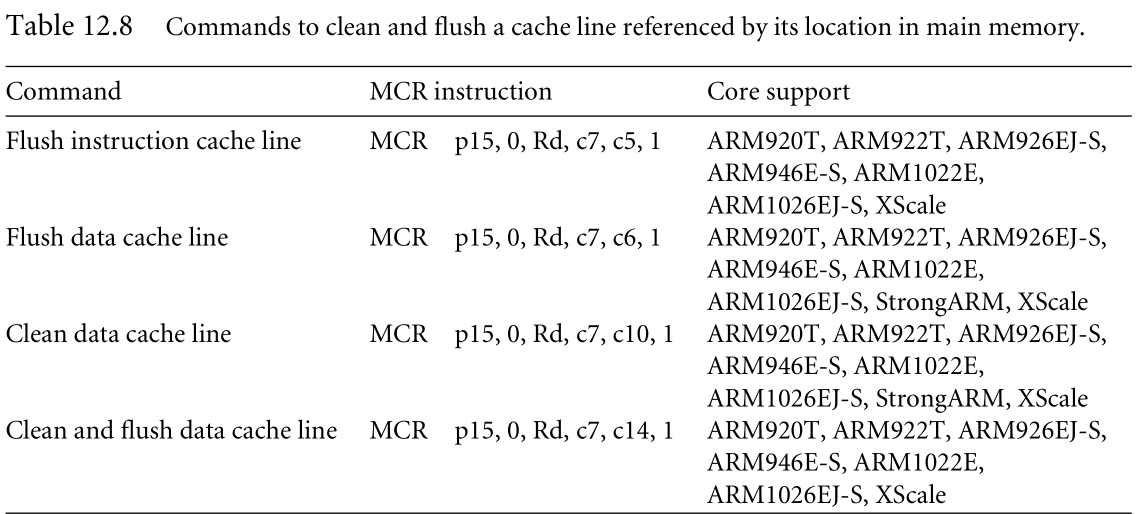
| Cache Lockdown |

Data or code locked in an ARM cache core is immune from replacement. However, when the cache is flushed, the information in lockdown is lost and the area remains unavailable as cache memory. The cache lockdown routine must be rerun to restore the lockdown information.
| Locking Code and Data in Cache |
lockdown一共有三种方法:

(具体内容参照p444~456)
| Caches and Software Performance |
这里有一些简单的规则来帮助你写出利用好Cache结构的代码:
1. Memory-mapped peripherals在被配置使用cache或者write buffer时会经常fail。最好的办法是将其配置为noncached and nonbuffered memory,这样能强制处理器在每一次内存访问的时候读取外设,而不是从Cache中读取陈旧的数据。
2. 试着将经常访问的数据有序的存放在内存中,要知道从主存读取新数据需要1个cache line fill的时间。如果在cache line中的数据仅仅被访问了1次,效率是很低下的。
3. Try to organize data so reading, processing, and writing is done in cache-line-sized block whose lower main memory address matches the starting address of the cache line.
4. 最一般的办法就是使代码更小,相关的数据更近,这样能提高效率。
5. 在使用cache的时候,链表会降低程序的性能,因为其随机性,搜索链表会遇到大量的cache misses。最好的办法时将其放入连续的数组之中。
6. 除了编写使用Cache的高效代码,chapter5,6关于高效编程的技术也是提升软件性能的关键。
| Cache Policy |
有三种策略决定cache的操作:the write policy, the replacement policy, and the allocation policy.
| 1-Write policy- writethrough or writeback |
The cache write policy determines where data is stored during processor write operations
Writethrough
The controller can write to both cache and main memory, updating the values in both locations. This writethrough policy is slower than a writeback policy.
Writeback
Cache controller can write to cache memory and not update main memory,this is known as writeback or copyback
Cache configured as writeback caches must use one or more of the dirty bits in the cache line status information block.
| 2-Cache Line Replacement Policies |
On a cache miss, the replacment policy selects a cache line in a set that is used for the next fill.
The process of selecting and replacement a victim cache line is known as eviction.
ARM cached core supprt two replacment policy
round-robin or cyclic replacement
The selection algorithm uses a sequential, incrementing victim counter.
The round-robin replacement policy has greater predictability than pseudorandom
pseudorandom
The selection algorithm uses a nonsequential incrementing vitim counter that randomly select an increment value.
Another common replacement policy:
least recently used(LRU)
This policy keeps track of cache line use and selects the cache line that has been unused for the longest time as the next victim.ARM’s cached cores don’t support LRU,but there are some ARM-based products that use the LRU replacement policy.
| 3-Allocation Policy on a Cache Miss |
The allocation policy determines when the cache controller allocates a cache line.
There are two strategies ARM caches may use to allocate a cache line after a the occurrence of a cache miss.
read-allocate
A read allocate on cache miss policy allocates a cache line only during a read from main memory.
The ARM7, ARM9, and ARM 10 cores use this policy.
read-write-allocate
This policy allocates a cache line for either a read or write to memory.
The Intel XScale supports both read-allocate and write-allocate on miss.
















 1705
1705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











