







关键词:X925、A725、3nm
1、引言
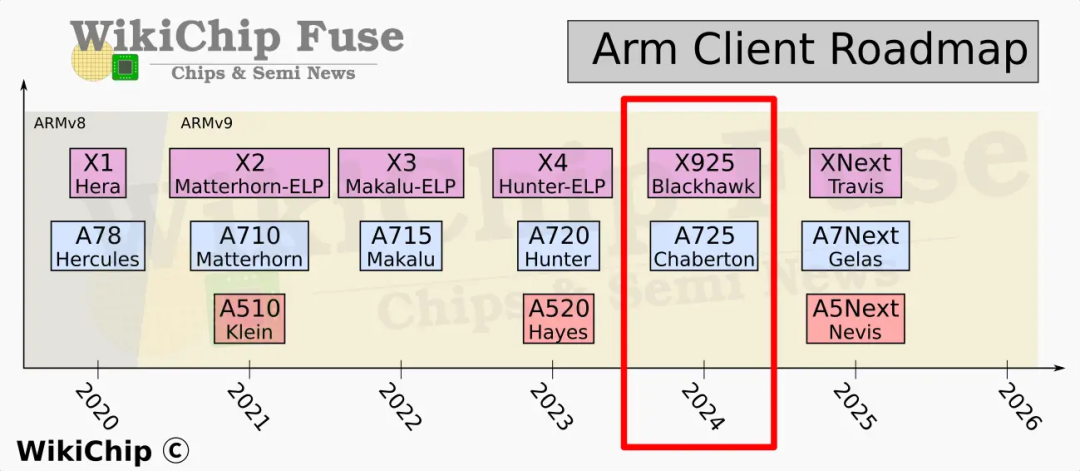
2024年5月,Arm一年一度的新处理器架构更新如期而至。今年是Arm超级大核心X计划的第五代产品,本来按照命名规则应该叫X5,但是这次Arm修改了命名规则,和A系列的命名规则做了一个对齐,新的名称叫做X925,A系列大核心新产品的名称叫做A725,小核心没有更新架构,还是A520。今年Arm新架构的指令集保持和上一年一样,还是Armv9.2架构。因为高通计划在今年采用自研架构处理器,所以预计MTK会先用上搭载X925核心的处理器。命名上,今年的X925,代号叫Blackhawk(黑鹰),A725的代号则叫做Chaberton(夏波顿,法国的一座山名)。

2、Arm的CSS方案
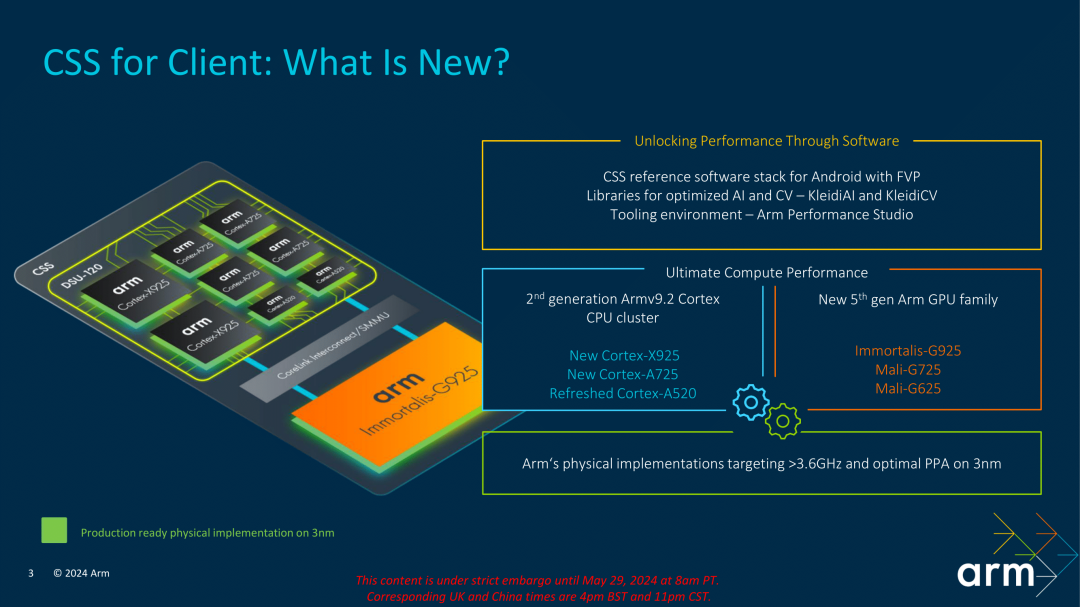
在2023年的TCS上,Arm就推行了CSS(Compute Subsystem)方案,我理解是一个和芯片厂商深入合作开发解决先进工艺适配的解决方案,可以基于3nm工艺和Armv9的技术,快速适配Android系统并优化AI等方案,具备高效整合CPU和GPU的能力,如将频率推高到3.6GHz以上(参考去年4nm的天玑9200+可以跑到3.35GHz),以及深入开展3nm的PPA优化等等。
3、3nm工艺制程
今年开始,Android阵营的旗舰处理器工艺逐步向3nm迁移,为半导体工业带来了更多的机遇和挑战。从前期苹果A17系列表现看,3nm依旧是一个成功的工艺制程,并且3nm还会逐步从N3升级N3E、N3P等更优秀的工艺制程。但是,从已经非常成熟的4nm向新的3nm迁移,需要花费更多的时间、金钱,也会遇到更多的问题,这也是Arm推CSS计划联合厂商一起设计的部分原因。况且3nm相比4nm有多少幅度的提升,仍然需要时间和更多产品的实际数据来检验。
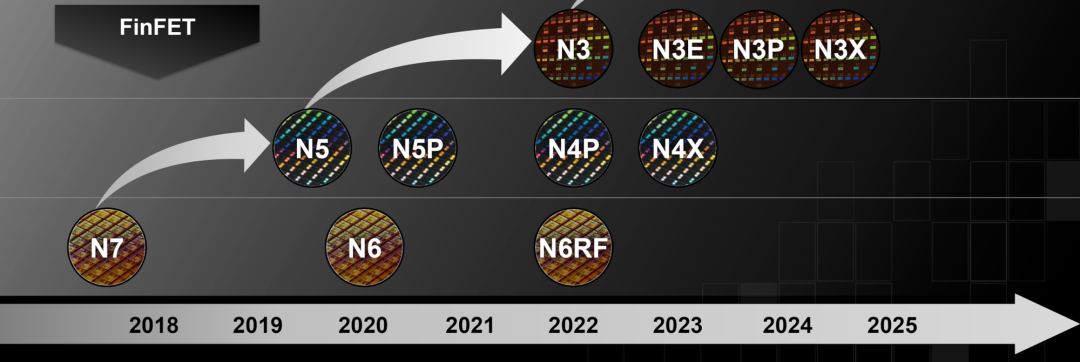
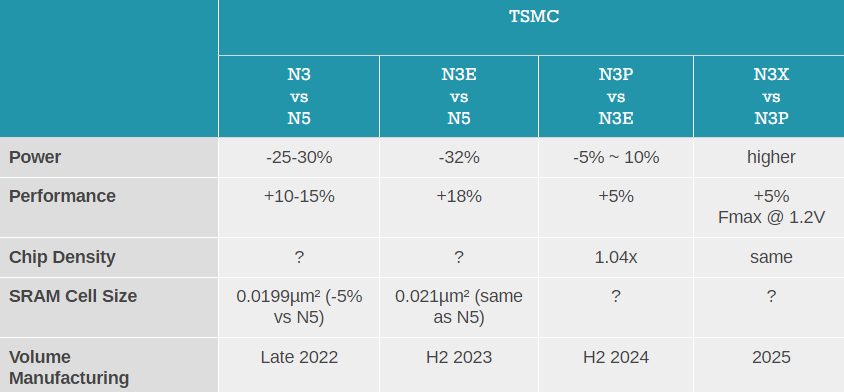 从图中看,为新工艺准备,Arm在3-4年前,就要开启相关产品的ISA和IP设计了。
从图中看,为新工艺准备,Arm在3-4年前,就要开启相关产品的ISA和IP设计了。

4、整体介绍
今年Arm参考设计中一个明显改变是大核心多了,相比传统的1+3+4架构,今年Arm的参考
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











