






这篇系列文章来至于一种冲动, 是在内部作为一些科普文。当然人的冲动不是无故产生的。以前团队内部做过一次简单的项目复盘。在实际参与项目交付过程中,实际解决的问题,在参与分析到相关问题的占比,只有不到15%(不用可怜我们=。=!,都是为人民服务!)。在项目中经常会遇到一些哭笑不得问题。
1.为什么CPU还有空闲,这个线程得不到调度运行?
2.这个线程running这么长时间,CPU团队看一下。
3.为什么优先级110的线程抢不过120的线程?
4.这个函数很耗时,但是CPU上很空闲,这个调度团队来看一下。
诸如此类。因此萌生了写个系列文章的念头。由于是科普文,如果有一些不是非常恰当的比喻,也希望可以谅解。
调度器顾名思义是用来做任务的调度的,因为CPU可能只有一个、两个或者4个,在android手机,最多只有8个(个别芯片除外)。调度器做不好,就会出现一核有难,N核围观的惨剧。


(PS:图片来之于网络,侵删)
那么为啥需要调度器呢?
原因是CPU只有这么几个,但是任务数量成千上万个。一个微信APP,可能就有200+个线程。如果手机上同时运行10+个APP。同时存在上千个线程不是梦想。调度器充分利用了分时复用,来让用户感觉到这么多线程在同时运行!
1.Linux的几种调度类
在Linux里面,一共有5种调度类,分别是stop 调度类(经常用来做task的migration),deadline调度类,realtime调度类,fair调度类,以及idle调度类。

它们是有优先级顺序的。按照从上往下的优先级,stop类的优先级最高,idle的优先级最低。
在调度器的核心__pick_next_task里面,该函数按照优先级顺序,遍历执行每一个调度类的pick_next_task的函数。尝试从这些调度类中找到一个可以执行的任务。
for_each_class(class) { p = class->pick_next_task(rq); if (p) return p; } |
这些调度类,我们用到最多的是realtime调度类,以及fair调度类。比如音频相关的线程、surfaceflinger相关的图形绘制线程,都是RT类型的。
其中RT调度类线程的优先级为0~99, 而fair调度的线程的优先级为100~139. 这也是为什么在android系统里面设置线程为RT调度类,这些线程可以优先得到调度,基本上没什么runnable的调度延迟的。
2.RT调度类与fair调度的区别是什么。
我们在看systrace的时候,通常会注意到线程的优先级(priority, 此处破音!!)
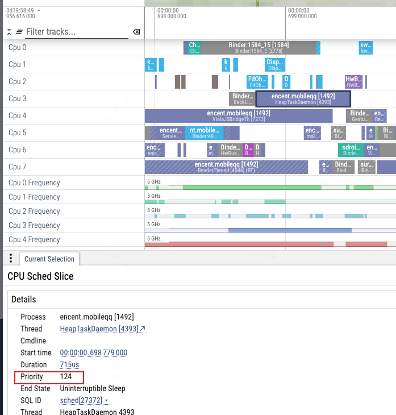
图二:systrace上显示的线程优先级
通常,我们对于priority有着朴实的认知,即按照从高到低排序,就跟”让领导先走“一样。但是天杀的,在Linux操作系统,对于priority,各个调度类的含义是完全不一样的。
我们在上面讲到了,5个调度类是有优先级之分的,在高优先级的调度类里面选不出来任务,才考虑从此优先级的调度类选择,以此类推。
对于RT调度类,这个选任务的函数是pick_next_task_rt ,这个函数用于选择RT类中下一个运行的任务。


RT调度类针对0~99的优先级区间,维护了数组,同时采用bitmap来表示这些数组每一个优先级里面有没有线程。换句话说,RT调度类是按照优先级从高到底的顺序来选择任务的。这一点符合人民群众对于priority的朴素认知。
那么fair调度类呢?这个调度类又取了个名字,叫fair。完整的叫法是completely fair scheduler(好大的口气!!)完全公平调度器,但是fair这个词明显是跟priority相悖的(有优先级顺序之分,就意味着并不公平)。
那么这个fair是啥意思呢?priority又是啥意思呢?网上讲CFS的文章很多,在此不详细解释了。总结一下,在CFS里面引入了一个新的概念,叫virtual runtime。这里的”完全公平“是针对virtual runtime而言的。 runtime我们知道,是指线程在CPU上的运行时长。那么virtual runtime是啥鬼意思呢?
LINUX CFS维护了一个庞大的红黑树,每一个node是任务task(准确的讲是调度实体entity,task是sched entity,但是sched entity不一定是task。是不是有点像绕口令?!)
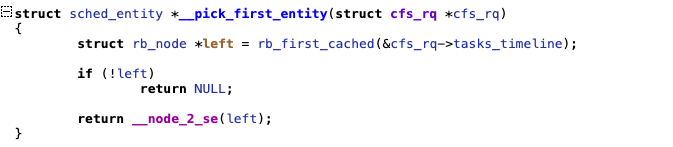
每次CFS调度类选取下一个执行的任务的时候,总是选取红黑树最左边的节点,也就是virtual runtime最小的线程。
那么virtual runtime是怎么计算的呢?
curr->vruntime += calc_delta_fair(delta_exec, curr); |
关于pelt的计算非常复杂,这里简化一下。
virtual runtime = physical runtime / weight;
虚拟时间,等于实际的物理运行时间,除以一个权重。这时候权重就起很大的作用。
这个权重,就是通过priority转化而来的。
3345 void reweight_task(struct task_struct *p, int prio)
3346 {
3347 struct sched_entity *se = &p->se;
3348 struct cfs_rq *cfs_rq = cfs_rq_of(se);
3349 struct load_weight *load = &se->load;
3350 unsigned long weight = scale_load(sched_prio_to_weight[prio]);
3351
3352 reweight_entity(cfs_rq, se, weight);
3353 load->inv_weight = sched_prio_to_wmult[prio];
3354 }
3355 EXPORT_SYMBOL_GPL(reweight_task);
到这里,我们稍微可以清晰一些。原来在FAIR调度类里面,priority并不是指普通意义上的优先级,其实是weight权重的意思。这个权重影响了任务获取CPU资源的占比(注意,占比是一个跟时间宽度有关系的变量)。
那么上面的第三个问题:
3. 为什么优先级110的线程抢不过120的线程?
就基本有答案了,因为cfs线程并不是通过priority优先级来进行排序调度的。因为这里的优先级代表着权重,代表着在一段时间内获取的资源的占比。当然影响FAIR调度的线程调度的原因并不只是这一种,其余原因后续再讲。
3.调度器都管哪些任务
我们知道。任务的状态有很多种,比如下面的这张图片
图三:systrace上显示进程片段结束时的状态
我们看到这个进程是以Uninterruptible Sleep状态结束的,顾名思义,进入睡眠状态,且不可打断。这种经常是线程在等某个条件资源的时候没有得到满足。
(PS:比较懒,图片都是网上找的)
在调度器里面,有两个专门的函数,enqueue和dequeue函数。
其中enqueue函数是指一个线程被唤醒之后,把线程放入到调度队列中。不同调度类有不同的管理办法。dequeue函数是指进程进入阻塞状态时,从队列中移除。
因此其实调度器的队列中只有处于TASK_RUNNING状态,也就是可运行状态的进程。对于处于非可运行状态的线程,其实就不在调度器的管理范围内,这一点也比较好理解。调度器本身就是利用分时复用机制,让就绪状态的任务轮换着执行,看起来像某个线程独占了CPU一样。因此大部分正常的时候,虽然系统的线程数量很多,成千上万个,但是在就绪队列里面(调度器的视野里面的)线程数量并不多(PS:CPU团队大部分都是处理的“不正常”的情况)
这样的话,上面的第一个问题其实就得到了解释。
4. 为什么CPU这空,我的线程得不到运行?
当CPU空闲,但是任务得不到执行,基本就是这个线程在等待某些条件,但是这个条件一直没有得到满足。比如线程卡锁、或者线程在读取文件,处于IO阻塞状态;又或者线程在等待某些条件,典型的如pthread_cond_wait。
上面提到了在CFS里面,priority并不是真正意义上的有顺序之分的优先级,而是weight权重的意义。这种在学术上被称之为“proportional scheduling”. 即按照一定的比例给不同的线程分配资源。有兴趣的同学可以去搜一下论文。从这个名字也就可以看出来,这种调度方式只能保证在一定时间内的资源配比比例,但是无法保障我们可能很多人关心的latency延迟问题。
4. 比例调度的问题
笔者上研究生的时候,就开始当牛马了。也亏了这段牛马的经历,在找工作的时候占了不少的优势。在研究生阶段,开始参与到linux的项目写驱动。人生第一次接触到服务器。当时实验室有一台服务器,供实验室的所有同学公共使用,进行代码的编写与编译。第一感觉就是CPU数量多,内存大,编译快。一个爽字了得。
但是当笔者ssh连接到服务器上写代码的时候,经常会被卡成狗,键盘输入,卡好久才显示一下。这时候top看一下,好家伙,排前几的都是gcc相关的线程。这时候笔者就会从座位上站起来拍桌子,大喊一声。谁又在“make -j 32” ?!
不用想,这时候是有人在编译代码,更有甚者make -j 64.
这时候,前面提到的proportional scheduling就出问题了,虽然这套机制在比较正常的运行。但是遇到这种优先级(权重)不够,数量来凑的情况,就容易被抓住漏洞。通过不讲武德地同时开启很多条工作线程,就可以攫取到系统的资源。
这时候大名鼎鼎的control group就出现了。
5. cgroup
cgroup全称control group。注意这个名字,非常准确,而且也是它最初的设计意图。在调度器层面,也就是CFS层面,有几种conctrol的功能机制,我们后面慢慢讲一下。先看一下具体的描述。
1039 if CGROUP_SCHED 1040 config FAIR_GROUP_SCHED 1041 bool "Group scheduling for SCHED_OTHER" 1042 depends on CGROUP_SCHED 1043 default CGROUP_SCHED 1044 1045 config CFS_BANDWIDTH 1046 bool "CPU bandwidth provisioning for FAIR_GROUP_SCHED" 1047 depends on FAIR_GROUP_SCHED 1048 default n 1049 help 1050 This option allows users to define CPU bandwidth rates (limits) for 1051 tasks running within the fair group scheduler. Groups with no limit 1052 set are considered to be unconstrained and will run with no 1053 restriction. 1054 See Documentation/scheduler/sched-bwc.rst for more information |
其中对当前android影响最大的就是FAIR_GROUP_SCHED。一般简称组调度。组调度是针对fair类(优先级100~139区间的线程)CFS进程的。这里我们做几个小实验来看看组调度带来的影响。cpuctl的cgroup被挂载在/dev/cpuctl的文件目录下,
进入/dev/cpuctl目录,可以看到里面有很多的文件夹以及一些文件节点。有些事android系统默认创建的,比如top-app、foreground、background等文件夹。有些是OPPO自己创建的,比如dex2oat、sstop、touch等等;
除了目录之外,还有很多的文件节点,比如tasks、cpu.shares,这些节点都是cgroup默认创建的。进入子目录的话,里面的文件节点会更多,比如
本章我们最关注的是cpu.shares这个参数。前面我们讲到了,比例调度存在的一个问题,就是如果一个进程或者业务开启大量的线程的话,即使单个线程的优先级比较低,份额占比比较低。但是依然可以靠着数量多来占用比较多的CPU资源。那么control group,可以通过cpu.shares来控制资源占比。cpu.shares可以认为是group的weight。如果能够控制住cgroup的weight,那么不管这个group里面有多少线程,这些线程的优先级是多少。都可以控制住这个cgroup占用的系统资源的占比。
我们可以通过mkdir在/dev/cpuctl里面创建几个分组,姑且成为test1跟test2吧。

我们创建了2个线程,pid分别为24725以及24722. 这两个线程的优先级都是120(注意PR这一列,20即为优先级120)

同时我们通过taskset命令把这两个线程都放到CPU7上,这样可以减少其余线程的干扰。
抓取的systrace如下,完美。
下面,我们把这两个进程放到test1跟test2两个分组
这时候这两个分组的cpu.shares都是默认值1024.抓取一个systrace,可以看到这两个任务分别在CPU7上交替运行。
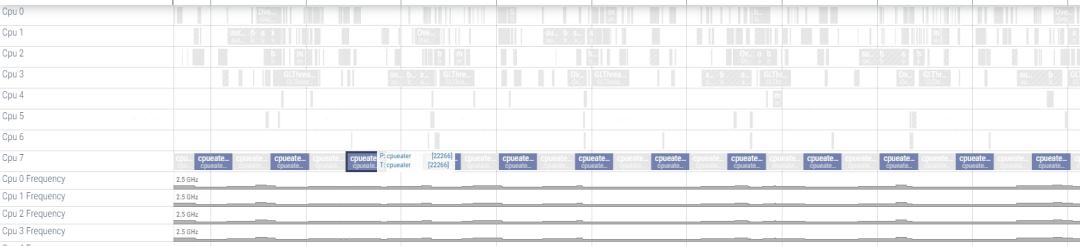
接下来我们调整线程的优先级,通过
renice -n -20 22262
将22262的优先级调整到100.(注意PR这一列,20为优先级120, 0即为优先级100)

这时候再抓一个trace看一下情况。
这时候2个进程的CPU额度占比大概是2:1. (1024:512)
我们总结一下上面的实验结果:
进程分组情况 | 进程优先级 | 资源大概占比 |
都在根组 | 一个进程为100 一个进程为120 | 24:1856 (systrace上随便框的,数据不够准确,看个大概就行了) |
一个进程在test1,一个进程在test2。cpushares都是1024 | 一个进程为100 一个进程为120 | 1:1 |
一个进程在test1,cpushares为512。一个进程在test2,cpushares为1024 | 两个进程的优先级都是120 | 1:2 |
这其实就是control group的背后的设计原理,当进程在同一个分组时,其资源占比受到priority权重的影响。当进程在不同分组时,其资源配额受到组的cpu.shares的控制。
通过上文的描述,以及上面的一系列实验,我们可以得出2个结论:
1.CFS的优先级代表weight,不保证高优先级抢占低优先级。但是毕竟CFS是proportional scheduling。因此从统计的角度,大部分时候还是高优先级抢占低优先级。但是无法保证。
2.引入cgroup之后,在任务选核时出现了2层结构,第一层收到cgroup的cpu.shares的限制。第二层才是原来的CFS优先级。 比如很多同学经常看systrace的时候会有疑问,为什么一个110优先级的线程抢不过139的线程。除了第一个点之外,大概率可能是因为这两个线程在不同的cgroup分组,首先受到cgroup分组的shares的资源约束。这里要多讲一点,cgroup的shares会按照cgroup内线程在各个CPU上的分布,按比例(CFS prio)带到各个CPU上。但是我们的任务在选核时其实没有考虑到这一点,导致可能某个cgroup分到某个CPU上的配额很低,最终因为配额过低导致这个被“抛弃”的任务runnable很长(脑补一下,两个公司一起搞活动,A公司11人,B公司9人。分成两个队伍,一个组10人。最终A公司就有个倒霉蛋要跟B公司的人组一队,是不是很不合群被遗忘的感觉)。
那么再次回到我们最开始说到的make -j32的问题。如果给不同的用户通过cgroup进行资源配置的控制,那么编译的时候即使开再多的线程,其资源占比也是受到控制的。
上面的资源占比控制,只有在出现资源竞争的时候才会生效。比如上面,如果24725线程处于sleeping状态的话,那么即使24722线程的cpushares再低,进程的优先级再低,也是可以100%占用到资源的。原因无他,因为没有跟它竞争了,所以它就拿到了全部。
图:开启组调度之后的调度topology的变化
那么我们是否可以再进一步压制线程24722的资源呢?答案是可以,也就是CFS_BANDWIDTH。具体这里不详细介绍了,有兴趣的同学可以google一下相关信息。
这里补充一点,在上文中,我们提到”LINUX CFS维护了一个庞大的红黑树,每一个node是任务task(准确的讲是调度实体entity,task是sched entity,但是sched entity不一定是task)“。
从上面的图中topology,其实可以得到答案,因为在开启了组调度之后。任务从原来的扁平结构,变成了树状的结构。组是一个虚拟的概念,是很多任务的一个虚拟结合。组其实也是一个调度实体(sched entity),当某个组被选中之后,才会继续从组内选择一个合适的task来继续执行。因此才说”task是sched entity,但是sched entity不一定是task“。
6. cgroup的问题
上面通过一系列的实验来说明了cgroup如何限制资源配额,来解决大量低优先级线程占用较高资源配额的问题。但是有时候“成也萧何、败也萧何”。cgroup虽然解决了一些问题,但是同时这个机制也带来了不少的问题。或者说在android上没有有效的利用起来。
我们知道,android中app,AMS会根据应用的状态将其放到不同的分组,如top-app,foreground,background。
这个大家可以在systrace里面,找到systemserver里面的oomadjuster用到,查看到相应的信息。
回到cgroup问题这个话题,在android系统里面,top-app、foreground、以及background分组的cpu.shares配额默认都是1024(以后会经常看到1024这个magic number,就跟我们日常用的100分制跟5分制的打分一样). 这是明显不合理的。
1.另外android系统默认把线程推到foreground分组,导致大量自研APK以及浮窗、分屏应用,都堆积在foreground分组里面。那么foreground分组到底应该分配多少呢?不知道。但是根据foreground中apk数量进行动态调整应该是个可行的方法。
2.由于android中service是基于C-S架构设计的,因此整个android充斥着大量的IPC(binder)调用。这些调用可能跨资源group组。比如处于top-app的前台应用,向处于foreground中的systemserver发起binder调用。那么问题来了。binder执行线程的资源,是占用的top-app分组的呢?还是占用的foreground分组的呢? 答案是foreground分组,这又是另外一个不合理点。
鉴于文章篇幅较长,我们将分期刊登,敬请期待下周的续篇更新。
往
期
推
荐
DRM(Digital Rights Management)生态以及架构介绍


















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











