









第19讲:Flink 如何做维表关联
在实际生产中,我们经常会有这样的需求,需要以原始数据流作为基础,然后关联大量的外部表来补充一些属性。例如,我们在订单数据中,希望能得到订单收货人所在省的名称,一般来说订单中会记录一个省的 ID,那么需要根据 ID 去查询外部的维度表补充省名称属性。
在 Flink 流式计算中,我们的一些维度属性一般存储在 MySQL/HBase/Redis 中,这些维表数据存在定时更新,需要我们根据业务进行关联。根据我们业务对维表数据关联的时效性要求,有以下几种解决方案:
-
实时查询维表
-
预加载全量数据
-
LRU 缓存
-
其他
上述几种关联外部维表的方式几乎涵盖了我们所有的业务场景,下面针对这几种关联维表的方式和特点一一讲解它们的实现方式和注意事项。
实时查询维表
实时查询维表是指用户在 Flink 算子中直接访问外部数据库,比如用 MySQL 来进行关联,这种方式是同步方式,数据保证是最新的。但是,当我们的流计算数据过大,会对外部系统带来巨大的访问压力,一旦出现比如连接失败、线程池满等情况,由于我们是同步调用,所以一般会导致线程阻塞、Task 等待数据返回,影响整体任务的吞吐量。而且这种方案对外部系统的 QPS 要求较高,在大数据实时计算场景下,QPS 远远高于普通的后台系统,峰值高达十万到几十万,整体作业瓶颈转移到外部系统。
这种方式的核心是,我们可以在 Flink 的 Map 算子中建立访问外部系统的连接。下面以订单数据为例,我们根据下单用户的城市 ID,去关联城市名称,核心代码实现如下:
public class Order {
private Integer cityId;
private String userName;
private String items;
public Integer getCityId() {
return cityId;
}
public void setCityId(Integer cityId) {
this.cityId = cityId;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getItems() {
return items;
}
public void setItems(String items) {
this.items = items;
}
@Override
public String toString() {
return "Order{" +
"cityId=" + cityId +
", userName='" + userName + '\'' +
", items='" + items + '\'' +
'}';
}
}
public class DimSync extends RichMapFunction<String,Order> {
private static final Logger LOGGER = LoggerFactory.getLogger(DimSync.class);
private Connection conn = null;
public void open(Configuration parameters) throws Exception {
super.open(parameters);
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/dim?characterEncoding=UTF-8", "admin", "admin");
}
public Order map(String in) throws Exception {
JSONObject jsonObject = JSONObject.parseObject(in);
Integer cityId = jsonObject.getInteger("city_id");
String userName = jsonObject.getString("user_name");
String items = jsonObject.getString("items");
//根据city_id 查询 city_name
PreparedStatement pst = conn.prepareStatement("select city_name from info where city_id = ?");
pst.setInt(1,cityId);
ResultSet resultSet = pst.executeQuery();
String cityName = null;
while (resultSet.next()){
cityName = resultSet.getString(1);
}
pst.close();
return new Order(cityId,userName,items,cityName);
}
public void close() throws Exception {
super.close();
conn.close();
}
}
在上面这段代码中,RichMapFunction 中封装了整个查询维表,然后进行关联这个过程。需要注意的是,一般我们在查询小数据量的维表情况下才使用这种方式,并且要妥善处理连接外部系统的线程,一般还会用到线程池。最后,为了保证连接及时关闭和释放,一定要在最后的 close 方式释放连接,否则会将 MySQL 的连接数打满导致任务失败。
预加载全量数据
全量预加载数据是为了解决每条数据流经我们的数据系统都会对外部系统发起访问,以及对外部系统频繁访问而导致的连接和性能问题。这种思路是,每当我们的系统启动时,就将维度表数据全部加载到内存中,然后数据在内存中进行关联,不需要直接访问外部数据库。
这种方式的优势是我们只需要一次性地访问外部数据库,大大提高了效率。但问题在于,一旦我们的维表数据发生更新,那么 Flink 任务是无法感知的,可能会出现维表数据不一致,针对这种情况我们可以采取定时拉取维表数据。并且这种方式由于是将维表数据缓存在内存中,对计算节点的内存消耗很高,所以不能适用于数量很大的维度表。
我们还是用上面的场景,根据下单用户的城市 ID 去关联城市名称,核心代码实现如下:
public class WholeLoad extends RichMapFunction<String,Order> {
private static final Logger LOGGER = LoggerFactory.getLogger(WholeLoad.class);
ScheduledExecutorService executor = null;
private Map<String,String> cache;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
executor.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
load();
} catch (Exception e) {
e.printStackTrace();
}
}
},5,5, TimeUnit.MINUTES);
}
@Override
public Order map(String value) throws Exception {
JSONObject jsonObject = JSONObject.parseObject(value);
Integer cityId = jsonObject.getInteger("city_id");
String userName = jsonObject.getString("user_name");
String items = jsonObject.getString("items");
String cityName = cache.get(cityId);
return new Order(cityId,userName,items,cityName);
}
public void load() throws Exception {
Class.forName("com.mysql.jdbc.Driver");
Connection con = DriverManager.getConnection("jdbc:mysql://localhost:3306/dim?characterEncoding=UTF-8", "admin", "admin");
PreparedStatement statement = con.prepareStatement("select city_id,city_name from info");
ResultSet rs = statement.executeQuery();
while (rs.next()) {
String cityId = rs.getString("city_id");
String cityName = rs.getString("city_name");
cache.put(cityId, cityName);
}
con.close();
}
}
在上面的例子中,我们使用 ScheduledExecutorService 每隔 5 分钟拉取一次维表数据。这种方式适用于那些实时场景不是很高,维表数据较小的场景。
LRU 缓存
LRU 是一种缓存算法,意思是最近最少使用的数据则被淘汰。在这种策略中,我们的维表数据天然的被分为冷数据和热数据。所谓冷数据指的是那些不经常使用的数据,热数据是那些查询频率高的数据。
对应到我们上面的场景中,根据城市 ID 关联城市的名称,北京、上海这些城市的订单远远高于偏远地区的一些城市,那么北京、上海就是热数据,偏远城市就是冷数据。这种方式存在一定的数据延迟,并且需要额外设置每条数据的失效时间。因为热点数据由于经常被使用,会常驻我们的缓存中,一旦维表发生变更是无法感知数据变化的。在这里使用 Guava 库提供的 CacheBuilder 来创建我们的缓存:
CacheBuilder.newBuilder()
//最多存储10000条
.maximumSize(10000)
//过期时间为1分钟
.expireAfterWrite(60, TimeUnit.SECONDS)
.build();
整体的实现思路是:我们利用 Flink 的 RichAsyncFunction 读取 Hbase 的数据到缓存中,我们在关联维度表时先去查询缓存,如果缓存中不存在这条数据,就利用客户端去查询 Hbase,然后插入到缓存中。
首先我们需要一个 Hbase 的异步客户端:
<dependency>
<groupId>org.hbase</groupId>
<artifactId>asynchbase</artifactId>
<version>1.8.2</version>
</dependency>
核心的代码实现如下:
public class LRU extends RichAsyncFunction<String,Order> {
private static final Logger LOGGER = LoggerFactory.getLogger(LRU.class);
String table = "info";
Cache<String, String> cache = null;
private HBaseClient client = null;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//创建hbase客户端
client = new HBaseClient("127.0.0.1","7071");
cache = CacheBuilder.newBuilder()
//最多存储10000条
.maximumSize(10000)
//过期时间为1分钟
.expireAfterWrite(60, TimeUnit.SECONDS)
.build();
}
@Override
public void asyncInvoke(String input, ResultFuture<Order> resultFuture) throws Exception {
JSONObject jsonObject = JSONObject.parseObject(input);
Integer cityId = jsonObject.getInteger("city_id");
String userName = jsonObject.getString("user_name");
String items = jsonObject.getString("items");
//读缓存
String cacheCityName = cache.getIfPresent(cityId);
//如果缓存获取失败再从hbase获取维度数据
if(cacheCityName != null){
Order order = new Order();
order.setCityId(cityId);
order.setItems(items);
order.setUserName(userName);
order.setCityName(cacheCityName);
resultFuture.complete(Collections.singleton(order));
}else {
client.get(new GetRequest(table,String.valueOf(cityId))).addCallback((Callback<String, ArrayList<KeyValue>>) arg -> {
for (KeyValue kv : arg) {
String value = new String(kv.value());
Order order = new Order();
order.setCityId(cityId);
order.setItems(items);
order.setUserName(userName);
order.setCityName(value);
resultFuture.complete(Collections.singleton(order));
cache.put(String.valueOf(cityId), value);
}
return null;
});
}
}
}
这里需要特别注意的是,我们用到了异步 IO (RichAsyncFunction),这个功能的出现就是为了解决与外部系统交互时网络延迟成为系统瓶颈的问题。
我们在流计算环境中,在查询外部维表时,假如访问是同步进行的,那么整体能力势必受限于外部系统。正是因为异步 IO 的出现使得访问外部系统可以并发的进行,并且不需要同步等待返回,大大减轻了因为网络等待时间等引起的系统吞吐和延迟问题。
我们在使用异步 IO 时,一定要使用异步客户端,如果没有异步客户端我们可以自己创建线程池模拟异步请求。
其他
除了上述常见的处理方式,我们还可以通过将维表消息广播出去,或者自定义异步线程池访问维表,甚至还可以自己扩展 Flink SQL 中关联维表的方式直接使用 SQL Join 方法关联查询结果。
总体来讲,关联维表的方式就以上几种方式,并且基于这几种方式还会衍生出各种各样的解决方案。我们在评价一个方案的优劣时,应该从业务本身出发,不同的业务场景下使用不同的方式。
总结
这一课时我们讲解了 Flink 关联维度表的几种常见方式,分别介绍了它们的优劣和适用场景,并进行了代码实现。我们在实际生产中应该从业务本身出发来评估每种方案的优劣,从而达到维表关联在时效性和性能上达到最优。
第20讲:Flink 高级应用之海量数据高效去重
本课时我们主要讲解 Flink 中的海量数据高效去重。
消除重复数据是我们在实际业务中经常遇到的一类问题。在大数据领域,重复数据的删除有助于减少存储所需要的存储容量。而且在一些特定的业务场景中,重复数据是不可接受的,例如,精确统计网站一天的用户数量、在事实表中统计每天发出的快递包裹数量。在传统的离线计算中,我们可以直接用 SQL 通过 DISTINCT 函数,或者数据量继续增加时会用到类似 MapReduce 的思想。那么在实时计算中,去重计数是一个增量和长期的过程,并且不同的场景下因为效率和精度问题方案也需要变化。
针对上述问题,我们在这里列出几种常见的 Flink 中实时去重方案:
-
基于状态后端
-
基于 HyperLogLog
-
基于布隆过滤器(BloomFilter)
-
基于 BitMap
-
基于外部数据库
下面我们依次讲解上述几种方案的适用场景和实现原理。
基于状态后端
我们在第 09 课时“Flink 状态与容错”中曾经讲过 Flink State 状态后端的概念和原理,其中状态后端的种类之一是 RocksDBStateBackend。它会将正在运行中的状态数据保存在 RocksDB 数据库中,该数据库默认将数据存储在 TaskManager 运行节点的数据目录下。
RocksDB 是一个 K-V 数据库,我们可以利用 MapState 进行去重。这里我们模拟一个场景,计算每个商品 SKU 的访问量。
整体的实现代码如下:
public class MapStateDistinctFunction extends KeyedProcessFunction<String,Tuple2<String,Integer>,Tuple2<String,Integer>> {
private transient ValueState<Integer> counts;
@Override
public void open(Configuration parameters) throws Exception {
//我们设置 ValueState 的 TTL 的生命周期为24小时,到期自动清除状态
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(org.apache.flink.api.common.time.Time.minutes(24 * 60))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
//设置 ValueState 的默认值
ValueStateDescriptor<Integer> descriptor = new ValueStateDescriptor<Integer>("skuNum", Integer.class);
descriptor.enableTimeToLive(ttlConfig);
counts = getRuntimeContext().getState(descriptor);
super.open(parameters);
}
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">void</span> <span class="hljs-title">processElement</span><span class="hljs-params">(Tuple2<String, Integer> value, Context ctx, Collector<Tuple2<String, Integer>> out)</span> <span class="hljs-keyword">throws</span> Exception </span>{
String f0 = value.f0;
<span class="hljs-comment">//如果不存在则新增</span>
<span class="hljs-keyword">if</span>(counts.value() == <span class="hljs-keyword">null</span>){
counts.update(<span class="hljs-number">1</span>);
}<span class="hljs-keyword">else</span>{
<span class="hljs-comment">//如果存在则加1</span>
counts.update(counts.value()+<span class="hljs-number">1</span>);
}
out.collect(Tuple2.of(f0, counts.value()));
}
}
在上面的这段代码里,我们实现了这样的逻辑:定义了一个 MapStateDistinctFunction 类,该类继承了 KeyedProcessFunction。核心的处理逻辑在 processElement 方法中,当一条数据经过,我们会在 MapState 中判断这条数据是否已经存在,如果不存在那么计数为 1,如果存在,那么在原来的计数上加 1。
这里需要注意的是,我们自定义了状态的过期时间是 24 小时,在实际生产中大量的 Key 会使得状态膨胀,我们可以对存储的 Key 进行处理。例如,使用加密方法把 Key 加密成几个字节进再存储。
基于 HyperLogLog
HyperLogLog 是一种估计统计算法,被用来统计一个集合中不同数据的个数,也就是我们所说的去重统计。HyperLogLog 算法是用于基数统计的算法,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2 的 64 方个不同元素的基数。HyperLogLog 适用于大数据量的统计,因为成本相对来说是更低的,最多也就占用 12KB 内存。
我们在不需要 100% 精确的业务场景下,可以使用这种方法进行统计。首先新增依赖:
<dependency>
<groupId>net.agkn</groupId>
<artifactId>hll</artifactId>
<version>1.6.0</version>
</dependency>
我们还是以上述的商品 SKU 访问量作为业务场景,数据格式为 <SKU, 访问的用户 id>:
public class HyperLogLogDistinct implements AggregateFunction<Tuple2<String,Long>,HLL,Long> {
@Override
public HLL createAccumulator() {
return new HLL(14, 5);
}
@Override
public HLL add(Tuple2<String, Long> value, HLL accumulator) {
//value 为访问记录 <商品sku, 用户id>
accumulator.addRaw(value.f1);
return accumulator;
}
@Override
public Long getResult(HLL accumulator) {
long cardinality = accumulator.cardinality();
return cardinality;
}
@Override
public HLL merge(HLL a, HLL b) {
a.union(b);
return a;
}
}
在上面的代码中,addRaw 方法用于向 HyperLogLog 中插入元素。如果插入的元素非数值型的,则需要 hash 过后才能插入。accumulator.cardinality() 方法用于计算 HyperLogLog 中元素的基数。
需要注意的是,HyperLogLog 并不是精准的去重,如果业务场景追求 100% 正确,那么一定不要使用这种方法。
基于布隆过滤器(BloomFilter)
BloomFilter(布隆过滤器)类似于一个 HashSet,用于快速判断某个元素是否存在于集合中,其典型的应用场景就是能够快速判断一个 key 是否存在于某容器,不存在就直接返回。
需要注意的是,和 HyperLogLog 一样,布隆过滤器不能保证 100% 精确。但是它的插入和查询效率都很高。
我们可以在非精确统计的情况下使用这种方法:
public class BloomFilterDistinct extends KeyedProcessFunction<Long, String, Long> {
private transient ValueState<BloomFilter> bloomState;
private transient ValueState<Long> countState;
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">void</span> <span class="hljs-title">processElement</span><span class="hljs-params">(String value, Context ctx, Collector<Long> out)</span> <span class="hljs-keyword">throws</span> Exception </span>{
BloomFilter bloomFilter = bloomState.value();
Long skuCount = countState.value();
<span class="hljs-keyword">if</span>(bloomFilter == <span class="hljs-keyword">null</span>){
BloomFilter.create(Funnels.unencodedCharsFunnel(), <span class="hljs-number">10000000</span>);
}
<span class="hljs-keyword">if</span>(skuCount == <span class="hljs-keyword">null</span>){
skuCount = <span class="hljs-number">0L</span>;
}
<span class="hljs-keyword">if</span>(!bloomFilter.mightContain(value)){
bloomFilter.put(value);
skuCount = skuCount + <span class="hljs-number">1</span>;
}
bloomState.update(bloomFilter);
countState.update(skuCount);
out.collect(countState.value());
}
}
我们使用 Guava 自带的 BloomFilter,每当来一条数据时,就检查 state 中的布隆过滤器中是否存在当前的 SKU,如果没有则初始化,如果有则数量加 1。
基于 BitMap
上面的 HyperLogLog 和 BloomFilter 虽然减少了存储但是丢失了精度, 这在某些业务场景下是无法被接受的。下面的这种方法不仅可以减少存储,而且还可以做到完全准确,那就是使用 BitMap。
Bit-Map 的基本思想是用一个 bit 位来标记某个元素对应的 Value,而 Key 即是该元素。由于采用了 Bit 为单位来存储数据,因此可以大大节省存储空间。
假设有这样一个需求:在 20 亿个随机整数中找出某个数 m 是否存在其中,并假设 32 位操作系统,4G 内存。在 Java 中,int 占 4 字节,1 字节 = 8 位(1 byte = 8 bit)
如果每个数字用 int 存储,那就是 20 亿个 int,因而占用的空间约为 (2000000000*4/1024/1024/1024)≈7.45G
如果按位存储就不一样了,20 亿个数就是 20 亿位,占用空间约为 (2000000000/8/1024/1024/1024)≈0.233G
在使用 BitMap 算法前,如果你需要去重的对象不是数字,那么需要先转换成数字。例如,用户可以自己创造一个映射器,将需要去重的对象和数字进行映射,最简单的办法是,可以直接使用数据库维度表中自增 ID。
首先我们新增一个依赖:
<dependency>
<groupId>org.roaringbitmap</groupId>
<artifactId>RoaringBitmap</artifactId>
<version>0.8.0</version>
</dependency>
然后,我们还以商品的 SKU 的访问记录举例:
public class BitMapDistinct implements AggregateFunction<Long, Roaring64NavigableMap,Long> {
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> Roaring64NavigableMap <span class="hljs-title">createAccumulator</span><span class="hljs-params">()</span> </span>{
<span class="hljs-keyword">return</span> <span class="hljs-keyword">new</span> Roaring64NavigableMap();
}
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> Roaring64NavigableMap <span class="hljs-title">add</span><span class="hljs-params">(Long value, Roaring64NavigableMap accumulator)</span> </span>{
accumulator.add(value);
<span class="hljs-keyword">return</span> accumulator;
}
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> Long <span class="hljs-title">getResult</span><span class="hljs-params">(Roaring64NavigableMap accumulator)</span> </span>{
<span class="hljs-keyword">return</span> accumulator.getLongCardinality();
}
<span class="hljs-meta">@Override</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> Roaring64NavigableMap <span class="hljs-title">merge</span><span class="hljs-params">(Roaring64NavigableMap a, Roaring64NavigableMap b)</span> </span>{
<span class="hljs-keyword">return</span> <span class="hljs-keyword">null</span>;
}
}
在上述方法中,我们使用了 Roaring64NavigableMap,其是 BitMap 的一种实现,然后我们的数据是每次被访问的 SKU,把它直接添加到 Roaring64NavigableMap 中,最后通过 accumulator.getLongCardinality() 可以直接获取结果。
基于外部数据库
假如我们的业务场景非常复杂,并且数据量很大。为了防止无限制的状态膨胀,也不想维护庞大的 Flink 状态,我们可以采用外部存储的方式,比如可以选择使用 Redis 或者 HBase 存储数据,我们只需要设计好存储的 Key 即可。同时使用外部数据库进行存储,我们不需要关心 Flink 任务重启造成的状态丢失问题,但是有可能会出现因为重启恢复导致的数据多次发送,从而导致结果数据不准的问题。
总结
这一课时我们讲解了多种不同的 Flink 大数据下的去重方法,并且详细比较了它们的异同。在实际的业务场景中,精确去重和非精确去重需要灵活选择不同的方案,在准确性和效率上达到统一。
第21讲:Flink 在实时计算平台和实时数据仓库中的作用
基于 Flink 的实时计算平台
大部分公司随着业务场景的不断丰富,同时在业界经过多年的实践检验,基于 Hadoop 的离线存储体系已经足够成熟。但是离线计算天然时效性不强,一般都是隔天级别的滞后,业务数据随着实践的推移,本身的价值就会逐渐减少。越来越多的场景需要使用实时计算,在这种背景下实时计算平台的需求应运而生。
架构选型
我们在第 03 课时“Flink 的编程模型与其他框架比较”中,提到过 Flink 自身独有的优势。
首先在架构上,Flink 采用了经典的主从模式,DataFlow Graph 与 Storm 形成的拓扑 Topology 结构类似,Flink 程序启动后,会根据用户的代码处理成 Stream Graph,然后优化成为 JobGraph,JobManager 会根据 JobGraph 生成 ExecutionGraph。ExecutionGraph 才是 Flink 真正能执行的数据结构,当很多个 ExecutionGraph 分布在集群中,就会形成一张网状的拓扑结构。
其次在容错方面,针对以前的 Spark Streaming 任务,我们可以配置对应的 checkpoint,也就是保存点(检查点)。当任务出现 failover 的时候,会从 checkpoint 重新加载,使得数据不丢失。但是这个过程会导致原来的数据重复处理,不能做到“只处理一次”的语义。Flink 基于两阶段提交实现了端到端的一次处理语义。
在任务的反压上,Flink 没有使用任何复杂的机制来解决反压问题,Flink 在数据传输过程中使用了分布式阻塞队列。我们知道在一个阻塞队列中,当队列满了以后发送者会被天然阻塞住,这种阻塞功能相当于给这个阻塞队列提供了反压的能力。
这些优势和特性,使得 Flink 在实时计算平台的搭建上占有一席之地。
实时计算平台整体架构
一般的实时计算平台的构成大都是以下几部分构成。
-
实时数据收集层
在实际业务中,大量的实时计算都是基于消息系统进行的数据收集和投递,这都离不开强大的消息中间件。目前业界使用最广的是 Kafka,另外一些重要的业务数据还会用到其他消息系统比如 RocketMQ 等。Kafka 因为高吞吐、低延迟的特性,特别适合大数量量、高 QPS 下的业务场景,而 RocketMQ 则在事务消息、一致性上有独特的优势。
-
实时计算层
Flink 在计算层同时支持流式及批量分析应用,这就是我们所说的批流一体。Flink 承担了数据的实时采集、实时计算和下游发送的角色。随着 Blink 的开源和一些其他实时产品的开源,支持可视化、SQL 化的开发模式已经越来越普及。
-
数据存储层
这里是我们的实时数据存储层,存储层除了传统 MySQL 等存储引擎以外,还会根据场景数据的不同存储在 Redis、HBase、OLAP 中。而这一层我个人认为最重要的技术选型则是 OLAP。OLAP 的技术选型直接制约着数据存储层和数据服务层的能力。关于 OLAP 的技术选型,可以参考这里。
-
数据服务层
数据服务层会提供统一的对外查询、多维度的实时汇总,加上完善的租户和权限设计,能够支持多部门、多业务的数据需求。另外,基于数据服务层还会有数据的展示、大屏、指标可视化等。
实时计算平台实际应用
美团在公开发表的文章中提到,目前美团实时计算平台的架构组成:最底层是实时数据收集层,使用 Kafka 进行数据收集,支撑了大量的实时计算和离线数据拉取任务。
基于实时数据收集层之上,是基于 Flink 的实时计算层,美团选择了 Flink on Yarn 模式,并且选择了 Redis、HBase 和 ElasticSearch 作为数据存储。同时,美团还面向数据开发者进行作业托管、作业调优和诊断报警功能。
整体来看,美团的实时计算平台主要包含作业管理和资源管理两个方面的能力。基于作业管理上可以做到任务的发布、回滚、状态监控等,在资源管理上基于多租户的设计进行业务隔离,并且 Flink Job 采用 on Yarn 的模式,任务之间进行资源隔离。
根据公开的技术分享文档来看,目前美团点评的实时计算平台节点已经达到几千台,在资源的优化上需要做到自动扩容、缩容,另外实时计算任务和离线任务的混合部署也需要考虑到如何进行更细粒度资源的释放。
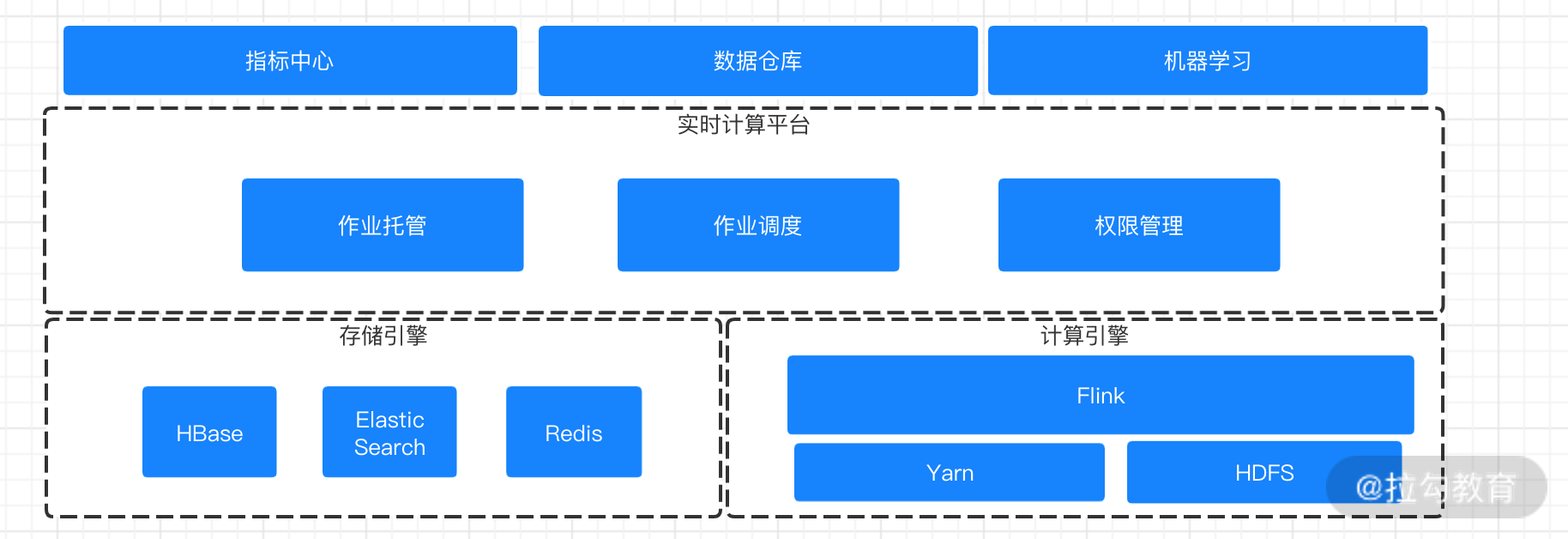
美团的实时计算平台图
微博的实时计算平台是随着业务线的快速扩张,为了满足业务需求逐渐演变。在初期架构中,仅仅存在计算和存储两层,每次接入一个新的实时计算业务就要重新开发一遍,代码的利用率低下,接入成本很高。
基于上面的需求,微博开发了基于 Flink 的通用组件,用来快速支持实时数据的快速接入。从下到上共分为五层,分别是接入层、计算层、存储层、服务层和应用层。整体的架构图如下图所示:
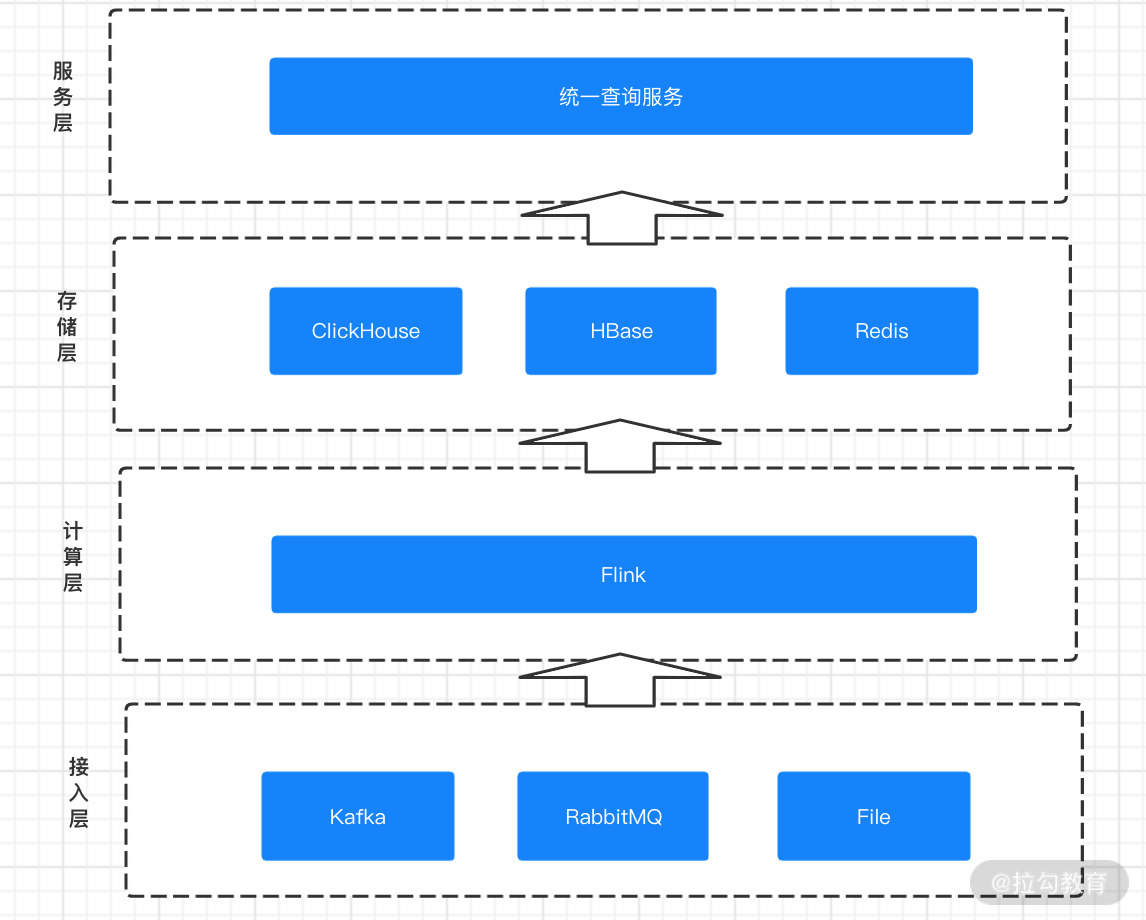
微博的实时计算平台图
基于微博的实时计算架构,数据从产生进入消息系统,通过 Flink 进行 ETL 进入存储层。根据业务不同的指标和数据需求,写入不同的存储中。统一查询服务则根据目前业务的需要,将查询服务微服务化,从数仓如 Redis、ElasticSearch、MySQL 等不同的存储中直接抽取。
微博的实时计算平台初期架构仅仅包含计算和存储两层,每个新的实时计算需求都要重新开发一遍,代码利用率低、重复开发。不同业务的不同需求对同一个指标的计算没有进行统一。随着数据量和业务的增长,前期架构的弊端开始显现,逐步发展成现在通用的计算架构。
在全新的计算架构下,微博基于 ClickHouse 进行多维度的计算来满足大数据量下的快速查询需求。数据分层上也借鉴了离线数仓的经验,构建了一套多层级的实时数仓服务,并且开发了多种形式的微服务对指标提取、数据聚合、数据质量、报警监控等进行支持。
基于 Flink 的实时数据仓库
我们在之前的课程中提过,Flink 的实际应用场景之一就是实时数据仓库。
实时数仓背景
传统的离线数据仓库将业务数据集中进行存储后,以固定的计算逻辑定时进行 ETL 和其他建模后产出报表等应用。离线数据仓库主要是构建 T+1 的离线数据,通过定时任务每天拉取增量数据,然后创建各个业务相关的主题维度数据,对外提供 T+1 的数据查询接口。
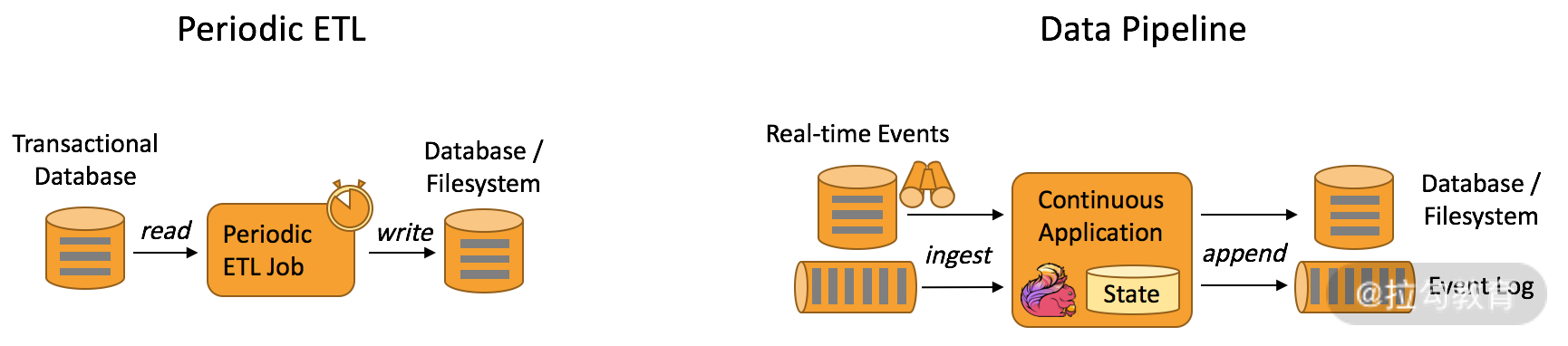
离线数据仓库 ETL 和实时数据仓库的差异图
上图展示了离线数据仓库 ETL 和实时数据仓库的差异,可以看到离线数据仓库的计算和数据的实时性均较差。数据本身的价值随着时间的流逝会逐步减弱,因此数据发生后必须尽快地达到用户的手中,实时数仓的构建需求也应运而生。
实时数据仓库的建设是“数据智能 BI”必不可少的一环,也是大规模数据应用中必然面临的挑战。
Flink 在实时数仓的优势
Flink 在实时数仓和实时 ETL 中有天然的优势:
-
状态管理,实时数仓里面会进行很多的聚合计算,这些都需要对状态进行访问和管理,Flink 支持强大的状态管理;
-
丰富的 API,Flink 提供极为丰富的多层次 API,包括 Stream API、Table API 及 Flink SQL;
-
生态完善,实时数仓的用途广泛,Flink 支持多种存储(HDFS、ES 等);
-
批流一体,Flink 已经在将流计算和批计算的 API 进行统一。
实时数仓的实际应用
离线数据仓库的设计中,我们会把仓库结构分为不同的层次来存储不同的数据,大概可以分为:ODS 源数据、DWD 明细层、DWS 汇总层、ADM 应用层。在实时数据仓库的设计中也可以参考这个设计。
但是需要注意的是,在实时数据模型的处理方式上和离线有所区别。例如,明细层的汇总一般是基于 Flink 等接入 Kafka 消息进行关联的,维度表的数据一般会放在 HDFS、HBase 中作为明细层的补充。另外,在实时数据仓库中要选择不同的 OLAP 库来满足即席查询。
我们来看一下网易严选和美团的实时数据仓库的设计分别是怎样的。
网易严选
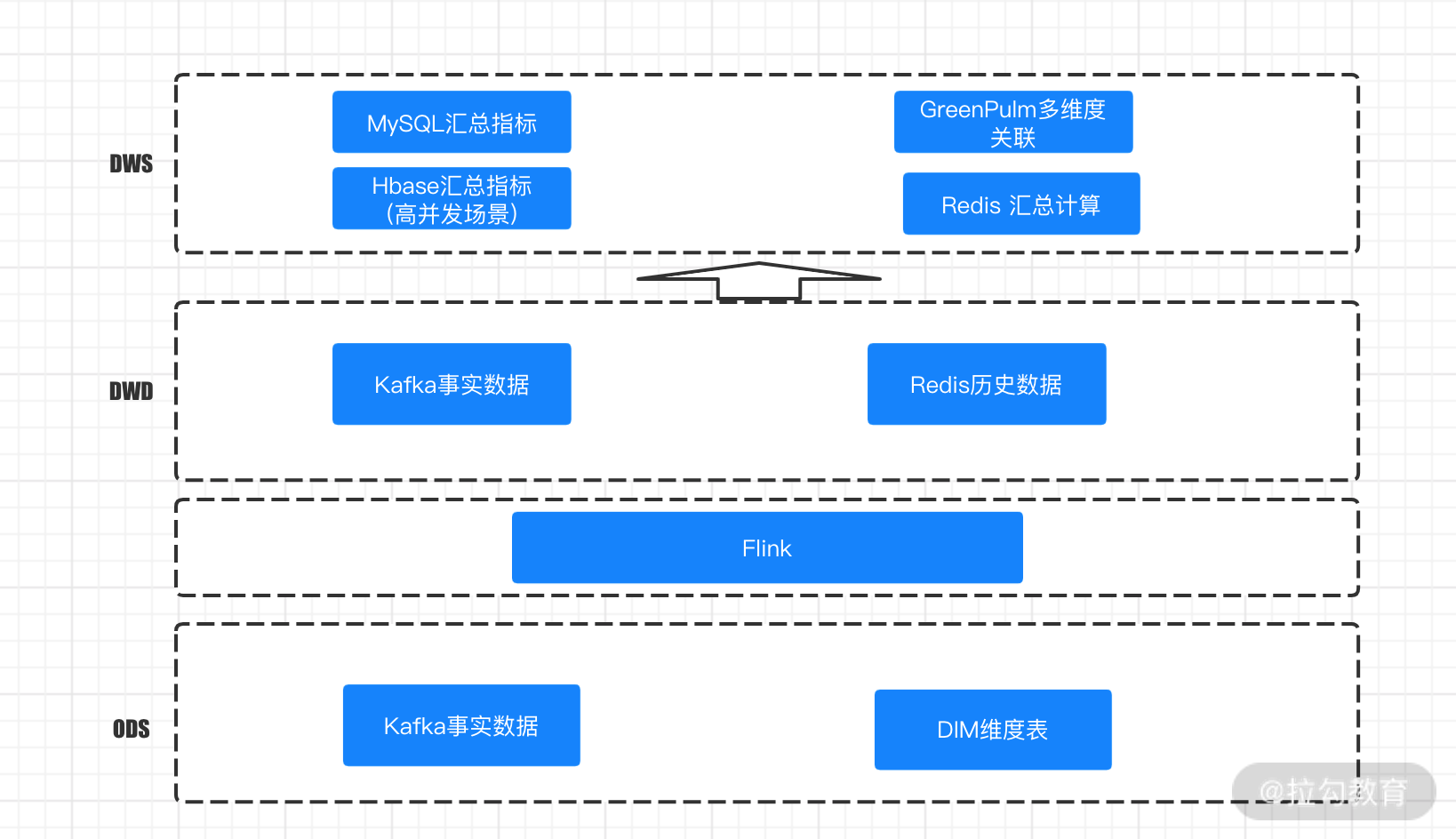
网易严选的实时数据仓库设计图
如上图所示,网易严选的实时数据仓库 ODS 层主要是基于 Kafka 的事实数据,经过 Flink 处理后形成 DWD 明细层,在 DWD 层中会关联一些维度和历史数据,并且存入 Redis 中。在 DWS 层中会根据不同的业务场景有不同的存储,高并发查询和写入会基于 HBase 进行。如果你需要基于明细做不同维度的汇总那么就要在 GreenPulm 这个 OLAP 引擎中进行查询分析,另外一些维度较多的查询、排序等直接存储在 Redis 中供查询使用。
我们可以看出网易严选在建设实时数仓的主要考量是计算和存储。在计算上,网易严选选择了 Flink,主要是因为 Flink 的端到端的精确一次语义支持和容错特性。另外在存储方面,网易严选选择把 Flink 处理完的数据备份到 Kafka,并且根据业务场景和数据应用特点选择了不同的存储介质,例如一些高并发查询会基于 HBase 进行,常见的汇总指标会放入 MySQL 中直接使用。
在我们的实际业务场景下,明细和汇总数据会根据查询 QPS、维度的复杂程度等选择不同的介质,其中 HBase、OLAP、Redis 等都是常见存储介质,需要用户根据实际业务进行选择。
美团
下图是美团的实时数仓分层的架构模型图:
-
ODS 层,基于 MySQL Binlog 和 Kafka 的日志消息;
-
明细层,基于事实数据关联成明细数据;
-
汇总层,使用明细数据进行多维度的查询汇总;
-
应用层,对外提供 HTTP、RPC 等查询服务。
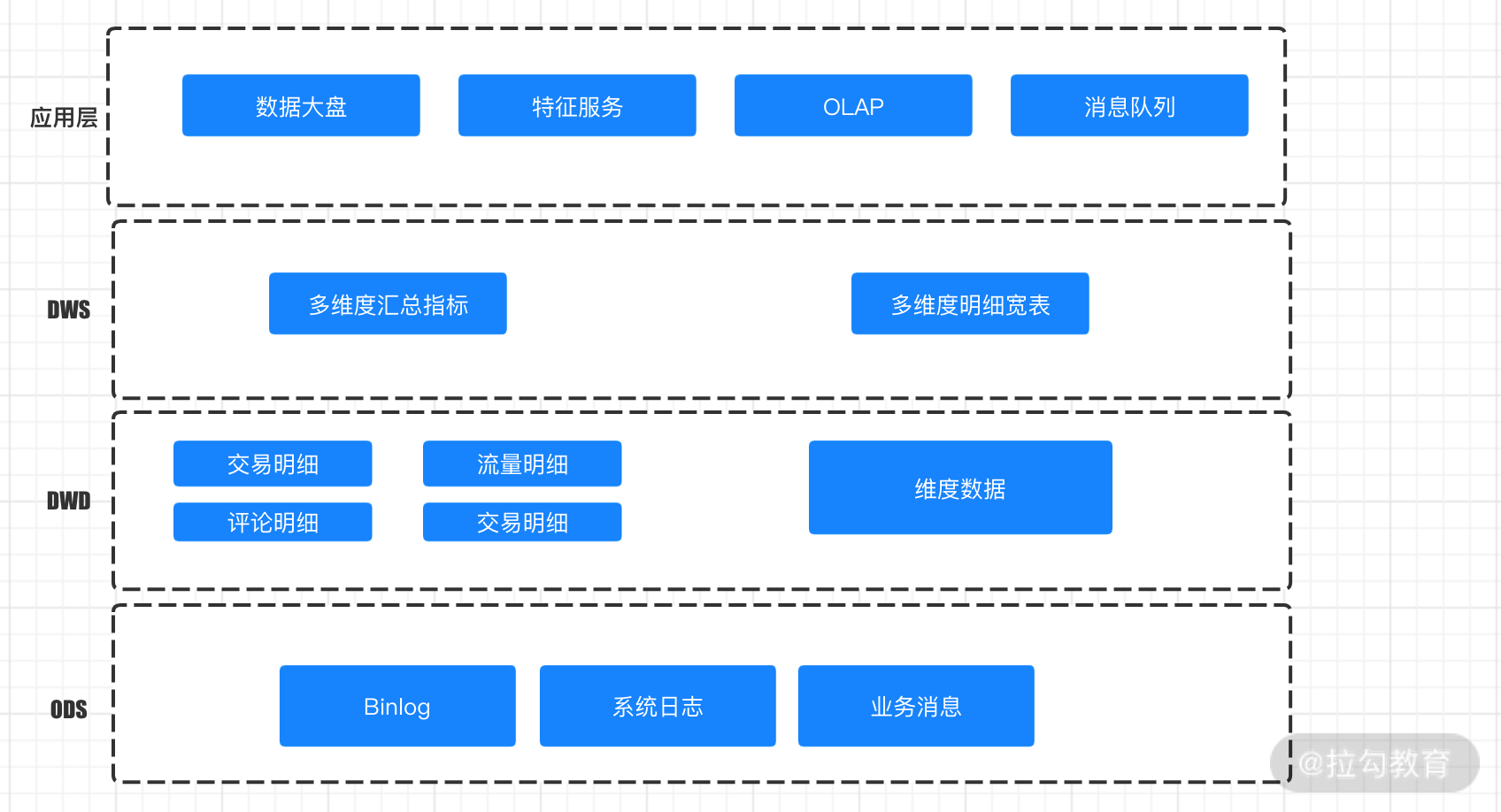
美团的实时数仓分层架构模型图
美团的 ODS 存放的主要是业务数据,其中大多是基于 MySQL 的 Binlog 和消息数据,这也是我们在实际业务中常用的方法。我们在建设实时数据仓库的过程中一个要求就是要和实际业务系统进行解耦,所以消息系统是我们的必然选择。
明细层是根据业务进行的划分,这一层的计算主要是基于 Flink 进行的,这一层承担着业务数据的解析、关联维表、明细存储的功能。
汇总层会基于明细数据进行再次关联和汇总,根据业务需要产出中间层和指标结果层。
最上层是同一对外服务的应用层,这层在我们的实际应用中非常重要。主要是根据外部系统的查询需要提供不同的查询服务,基于 HTTP、RPC 等的查询服务是常见选择,我们需要仔细评估访问的 QPS、查询负载等对接口进行限流、幂等、容错设计。并且需要进行严格的权限设计,防止数据泄露和非法访问。
总结
本课时我们讲解了基于 Flink 的实时计算平台的设计和架构,并且讲解了美团和微博的实时计算平台设计;与此同时还讲解了 Flink 在实时数仓的优势和应用。总体来看,实时数据平台和实时数仓在业界已经有了较为成熟的方案,我们可以根据已有的方案和公司业务设计自己的实时计算平台和实时数据仓库。















 9220
9220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











