







(q)根据哈弗曼树的定义,一棵二叉树要使其WPL值最小,必须使权值越大的叶子结点越靠近根结点,而权值越小的叶子结点
越远离根结点。
哈弗曼依据这一特点提出了一种构造最优二叉树的方法,其基本思想如下:
 下面演示了用Huffman算法构造一棵Huffman树的过程:
下面演示了用Huffman算法构造一棵Huffman树的过程:
 (2)例题:
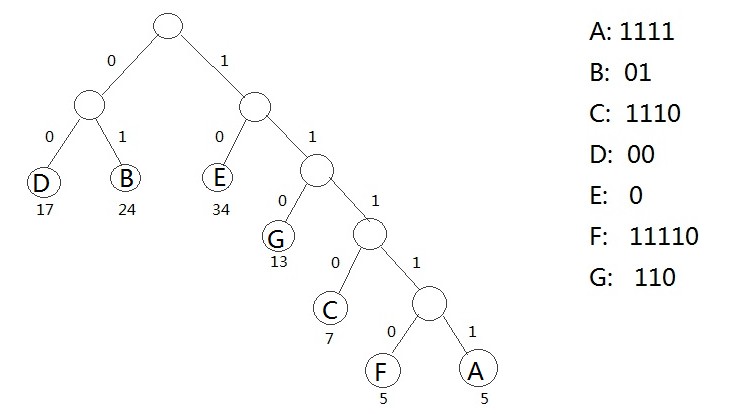
假设一个文本文件TFile中只包含7个字符{A,B,C,D,E,F,G},这7个字符在文本中出现的次数为{5,24,7,17,34,5,13}
利用哈夫曼树可以为文件TFile构造出符合前缀编码要求的不等长编码
具体做法:
1. 将TFile中7个字符都作为叶子结点,每个字符出现次数作为该叶子结点的权值
2. 规定哈夫曼树中所有左分支表示字符0,所有右分支表示字符1,将依次从根结点到每个叶子结点所经过的分支的二进制位的序列作为该
结点对应的字符编码
3. 由于从根结点到任何一个叶子结点都不可能经过其他叶子,这种编码一定是前缀编码,哈夫曼树的带权路径长度正好是文件TFile编码
的总长度
通过哈夫曼树来构造的编码称为哈弗曼编码(huffman code)
(2)例题:
假设一个文本文件TFile中只包含7个字符{A,B,C,D,E,F,G},这7个字符在文本中出现的次数为{5,24,7,17,34,5,13}
利用哈夫曼树可以为文件TFile构造出符合前缀编码要求的不等长编码
具体做法:
1. 将TFile中7个字符都作为叶子结点,每个字符出现次数作为该叶子结点的权值
2. 规定哈夫曼树中所有左分支表示字符0,所有右分支表示字符1,将依次从根结点到每个叶子结点所经过的分支的二进制位的序列作为该
结点对应的字符编码
3. 由于从根结点到任何一个叶子结点都不可能经过其他叶子,这种编码一定是前缀编码,哈夫曼树的带权路径长度正好是文件TFile编码
的总长度
通过哈夫曼树来构造的编码称为哈弗曼编码(huffman code)
 .
(3)结构与创建
.
(3)结构与创建
- class HTNode{ // 树中结点的结构
- public:
- unsigned int weight;
- unsigned int parent,lchild,rchild;
- };
-
- class HTCode{
- public:
- char data; // 待编码的字符
- int weight; // 字符的权值
- char code[N]; // 字符的编码
- };
-
- void Init(HTCode hc[], int *n){
- // 初始化,读入待编码字符的个数n,从键盘输入n个字符和n个权值
- int i;
- printf("input n = ");
- scanf("%d",&(*n));
-
- printf("\ninput %d character\n",*n);
-
- fflush(stdin);
- for(i=1; i<=*n; ++i)
- scanf("%c",&hc[i].data);
-
- printf("\ninput %d weight\n",*n);
-
- for(i=1; i<=*n; ++i)
- scanf("%d",&(hc[i].weight) );
- fflush(stdin);
- }//
-
- void Select(HTNode ht[], int k, int *s1, int *s2){
- // ht[1...k]中选择parent为0,并且weight最小的两个结点,其序号由指针变量s1,s2指示
- int i;
- for(i=1; i<=k && ht[i].parent != 0; ++i){
- ; ;
- }
- *s1 = i;
-
- for(i=1; i<=k; ++i){
- if(ht[i].parent==0 && ht[i].weight<ht[*s1].weight)
- *s1 = i;
- }
-
- for(i=1; i<=k; ++i){
- if(ht[i].parent==0 && i!=*s1)
- break;
- }
- *s2 = i;
-
- for(i=1; i<=k; ++i){
- if(ht[i].parent==0 && i!=*s1 && ht[i].weight<ht[*s2].weight)
- *s2 = i;
- }
- }
-
- void HuffmanCoding(HTNode ht[],HTCode hc[],int n){
- // 构造Huffman树ht,并求出n个字符的编码
- char cd[N];
- int i,j,m,c,f,s1,s2,start;
- m = 2*n-1;
-
- for(i=1; i<=m; ++i){ //初始化操作,全部置0
- if(i <= n)
- ht[i].weight = hc[i].weight;
- else
- ht[i].parent = 0;
- ht[i].parent = ht[i].lchild = ht[i].rchild = 0;
- }
-
- for(i=n+1; i<=m; ++i){
- Select(ht, i-1, &s1, &s2);
- ht[s1].parent = i;
- ht[s2].parent = i;
- ht[i].lchild = s1;
- ht[i].rchild = s2;
- ht[i].weight = ht[s1].weight+ht[s2].weight;
- }
-
- cd[n-1] = '\0';
-
- for(i=1; i<=n; ++i){
- start = n-1;
- for(c=i,f=ht[i].parent; f; c=f,f=ht[f].parent){
- if(ht[f].lchild == c)
- cd[--start] = '0';
- else
- cd[--start] = '1';
- }
- strcpy(hc[i].code, &cd[start]);
- }
- }
-
-
- int main()
- {
- int i,m,n,w[N+1];
- HTNode ht[M+1];
- HTCode hc[N+1];
- Init(hc, &n); // 初始化
- HuffmanCoding(ht,hc,n); // 构造Huffman树,并形成字符的编码
-
- for(i=1; i<=n; ++i)
- printf("\n%c---%s",hc[i].data,hc[i].code);
- printf("\n");
-
- return 0;
- }
(2)例题:
假设一个文本文件TFile中只包含7个字符{A,B,C,D,E,F,G},这7个字符在文本中出现的次数为{5,24,7,17,34,5,13}
利用哈夫曼树可以为文件TFile构造出符合前缀编码要求的不等长编码
具体做法:
1. 将TFile中7个字符都作为叶子结点,每个字符出现次数作为该叶子结点的权值
2. 规定哈夫曼树中所有左分支表示字符0,所有右分支表示字符1,将依次从根结点到每个叶子结点所经过的分支的二进制位的序列作为该
结点对应的字符编码
3. 由于从根结点到任何一个叶子结点都不可能经过其他叶子,这种编码一定是前缀编码,哈夫曼树的带权路径长度正好是文件TFile编码
的总长度
通过哈夫曼树来构造的编码称为哈弗曼编码(huffman code)
.
(3)结构与创建
- class HTNode{ // 树中结点的结构
- public:
- unsigned int weight;
- unsigned int parent,lchild,rchild;
- };
- class HTCode{
- public:
- char data; // 待编码的字符
- int weight; // 字符的权值
- char code[N]; // 字符的编码
- };
- void Init(HTCode hc[], int *n){
- // 初始化,读入待编码字符的个数n,从键盘输入n个字符和n个权值
- int i;
- printf("input n = ");
- scanf("%d",&(*n));
- printf("\ninput %d character\n",*n);
- fflush(stdin);
- for(i=1; i<=*n; ++i)
- scanf("%c",&hc[i].data);
- printf("\ninput %d weight\n",*n);
- for(i=1; i<=*n; ++i)
- scanf("%d",&(hc[i].weight) );
- fflush(stdin);
- }//
- void Select(HTNode ht[], int k, int *s1, int *s2){
- // ht[1...k]中选择parent为0,并且weight最小的两个结点,其序号由指针变量s1,s2指示
- int i;
- for(i=1; i<=k && ht[i].parent != 0; ++i){
- ; ;
- }
- *s1 = i;
- for(i=1; i<=k; ++i){
- if(ht[i].parent==0 && ht[i].weight<ht[*s1].weight)
- *s1 = i;
- }
- for(i=1; i<=k; ++i){
- if(ht[i].parent==0 && i!=*s1)
- break;
- }
- *s2 = i;
- for(i=1; i<=k; ++i){
- if(ht[i].parent==0 && i!=*s1 && ht[i].weight<ht[*s2].weight)
- *s2 = i;
- }
- }
- void HuffmanCoding(HTNode ht[],HTCode hc[],int n){
- // 构造Huffman树ht,并求出n个字符的编码
- char cd[N];
- int i,j,m,c,f,s1,s2,start;
- m = 2*n-1;
- for(i=1; i<=m; ++i){ //初始化操作,全部置0
- if(i <= n)
- ht[i].weight = hc[i].weight;
- else
- ht[i].parent = 0;
- ht[i].parent = ht[i].lchild = ht[i].rchild = 0;
- }
- for(i=n+1; i<=m; ++i){
- Select(ht, i-1, &s1, &s2);
- ht[s1].parent = i;
- ht[s2].parent = i;
- ht[i].lchild = s1;
- ht[i].rchild = s2;
- ht[i].weight = ht[s1].weight+ht[s2].weight;
- }
- cd[n-1] = '\0';
- for(i=1; i<=n; ++i){
- start = n-1;
- for(c=i,f=ht[i].parent; f; c=f,f=ht[f].parent){
- if(ht[f].lchild == c)
- cd[--start] = '0';
- else
- cd[--start] = '1';
- }
- strcpy(hc[i].code, &cd[start]);
- }
- }
- int main()
- {
- int i,m,n,w[N+1];
- HTNode ht[M+1];
- HTCode hc[N+1];
- Init(hc, &n); // 初始化
- HuffmanCoding(ht,hc,n); // 构造Huffman树,并形成字符的编码
- for(i=1; i<=n; ++i)
- printf("\n%c---%s",hc[i].data,hc[i].code);
- printf("\n");
- return 0;
- }















 3542
3542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









