







KMP是一种线性复杂度的串匹配算法,普通的匹配算法的复杂度是O(m*n)而KMP则是O(m+n)。
自己理解的KMP核心思想是:
abcddadc i 此时等于3时发现不匹配,
abedse j=3
此时,传统算法是 i再从2开始匹配,但KMP是拒绝走回头路的,既然已经匹配过3了,那下一次i就需要算4了。
i既然不回头,那回头的就只能是j了。
怎样才能达到这样,不必重复比较呢?
算法创作者发现避免重复计算是与目标串是否与开头重复有关的。
算法主体过程是
i一直增大,与目标串匹配,发现不能匹配时,就需要改变j(即向右移动目标串)
j跳转到下一个next[j]是提前根据目标串算好的。
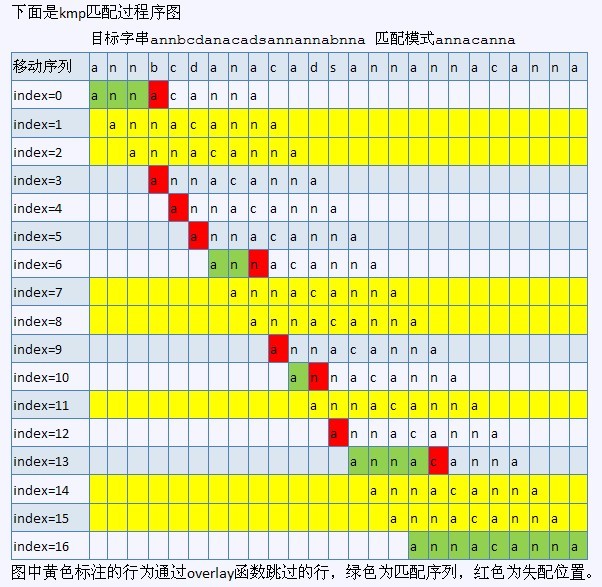
这里附上一个图,大致示意一下。黄色部分是没有必要的比较。(i走回头路了。)
计算next[j]:
如有 目标串T:
a b a b b a a b a
j = 0时 next[0] = 0;
j = 1 时next[1] = 1;
j > 2 时,则是要看 前面 j-1个字母是否有开头和结尾重复,
如j = 2
前面两个为 a b ,可以看出开头和结尾重复,则next[2] = 1;
如 j = 3
前面三名为 a b a .可以看出,开头和结尾有重复,
a b a
a b a。所以,next[3] = 2;
如 j= 4;
前面 四个为 a b a b。有重复,并且最多重复了
a b a b
a b a b.所以 next[4] = 3;
如 j = 5;
前面5个为a b a b b ,开头和结尾没有重复,则next[5] = 1;
如 j = 6.
前面 6 个为 a b a b b a .有重复
a b a b b a
a b a b b a 则 next[6] = 2;
如j = 7
前面7个为 a b a b b a a,开头和结尾有重复,
a b a b b a a
a b a b b a a ,则next[7] = 2;
如j = 8
前面8个为 a b a b b a a b ,有重复
a b a b b a a b
a b a b b a a b,开头和结尾最多重复 2.所以next[8]= 3;
所以:next[] = {0,1,1,2,3,1,2,2,3}
KMP是匹配到i和j不相等时,j= next[j]
这样的效果是:
ababccababbaa
ababbaa
i = 4,j =4时 不匹配,
i =4; j =next[j] - 1= 2
ababccababbaa
ababbaa
下一次 i 与 j = 2匹配,则j = next[2] = 1
ababccababbaa
ababbaa
此时j = next[j] - 1 = 0,i++;
i = 5 ,j = 0
不匹配,且j == 0
i++
ababccababbaa
ababbaa
成功。















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









